📊 Experiments & Results
Evaluation Setup
Offline SFT followed by Online RL (GRPO) on reasoning tasks
Benchmarks:
- SynLogic (Synthetic Logic Puzzles)
- Enigmata (Harder Logic Puzzles)
- MATH-500 (Mathematical Reasoning)
- AIME-2024 / AIME-2025 (Competition Math)
- AMC-2023 (Competition Math)
Metrics:
- Pass@1
- Pass@8
- Accuracy (post-RL)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Logic Puzzle Results: PEAR significantly improves post-RL performance compared to baselines. | ||||
| Logic Games (SynLogic) | Accuracy (Post-RL) | 55.0 | 95.0 | +40.0 |
| Math Benchmark Results: Consistent gains on standard math competitions using Qwen3-1.7B-Base. | ||||
| AIME-2025 | Pass@8 | 4.6 | 19.2 | +14.6 |
| AIME-2024 | Pass@8 | 12.8 | 20.8 | +8.0 |
| MATH-500 | Pass@1 | 51.8 | 56.0 | +4.2 |
| Distilled Model Results: PEAR improves even strong, distilled models. | ||||
| MATH-500 | Pass@1 | 63.2 | 66.4 | +3.2 |
| Ablation Study: Negative data and KL-distillation compatibility. | ||||
| Enigmata | Pass@1 (Post-RL) | 47.0 | 54.0 | +7.0 |
Experiment Figures
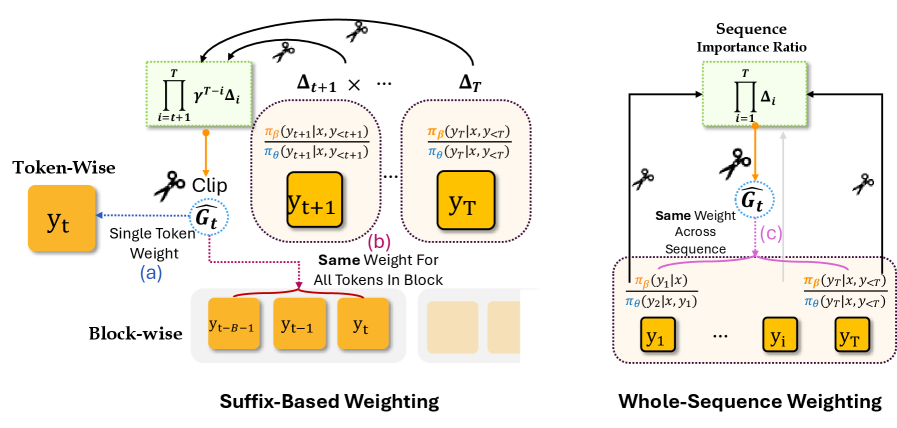
Conceptual illustration of the distribution mismatch.
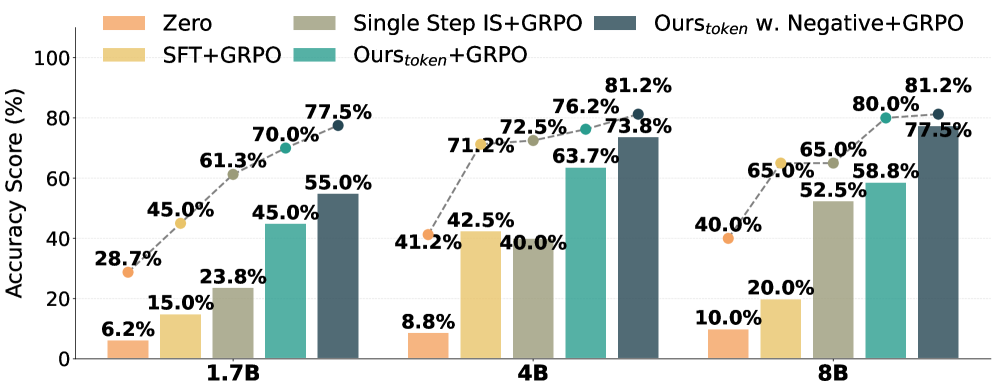
Ablation on weighting strategies and negative data.
Main Takeaways
- Offline performance is a poor predictor of online RL performance; some methods (like TopLogP) improve offline metrics but degrade post-RL results.
- PEAR consistently outperforms SFT and other reweighting baselines (TALR, One-step) across diverse model sizes (0.6B to 8B) and benchmarks.
- The benefits of PEAR transfer across domains: models trained offline on one distribution (SynLogic) transfer better to a shifted online distribution (Enigmata).
- Token-level suffix weighting (PEAR B=1) is generally the most effective variant, though sequence-level weighting also performs surprisingly well.
- PEAR reduces parameter drift during RL compared to SFT, suggesting the initialization is 'closer' to the optimal RL solution.