📝 Paper Summary
Tokenizer-free language modeling
Hierarchical transformer architectures
Robustness and adaptability in NLP
The paper proposes a hierarchical architecture that processes text as words but encodes/decodes them as character sequences, matching standard model performance while significantly improving robustness and adaptability to new languages.
Core Problem
Standard subword tokenizers (like BPE) create rigid, large vocabularies that struggle with spelling variations, generalize poorly to new domains/languages, and consume significant parameter budgets.
Why it matters:
- Fixed tokenizers fail catastrophically on noisy text (typos) or unseen languages, requiring complete retraining of the tokenizer and embedding layers to adapt effectively.
- Large vocabulary sizes (e.g., 128k in Llama-3) mean embedding matrices and output heads consume a massive portion of the parameter budget (approx. 13% of an 8B model).
- Mismatch between pretraining and downstream data tokenization degrades performance, a critical issue for applying models to specialized domains or low-resource languages.
Concrete Example:
Spelling mistakes or variations can lead to drastically different token sequences for semantically close inputs (e.g., 'color' vs 'colour' or 'teh' vs 'the') using standard BPE, degrading model performance.
Key Novelty
Hierarchical Character-Word-Character Architecture
- Uses a 'sandwich' design: a small character-level encoder compresses characters into a word embedding, a large backbone processes these word embeddings, and a small character-level decoder generates the next word's characters.
- Eliminates the need for a trained tokenizer or fixed vocabulary by using a simple whitespace splitting rule and processing raw bytes/characters directly.
- Treats the backbone's output as an abstract 'predictive' embedding that triggers an autoregressive character generation loop for the next word.
Architecture
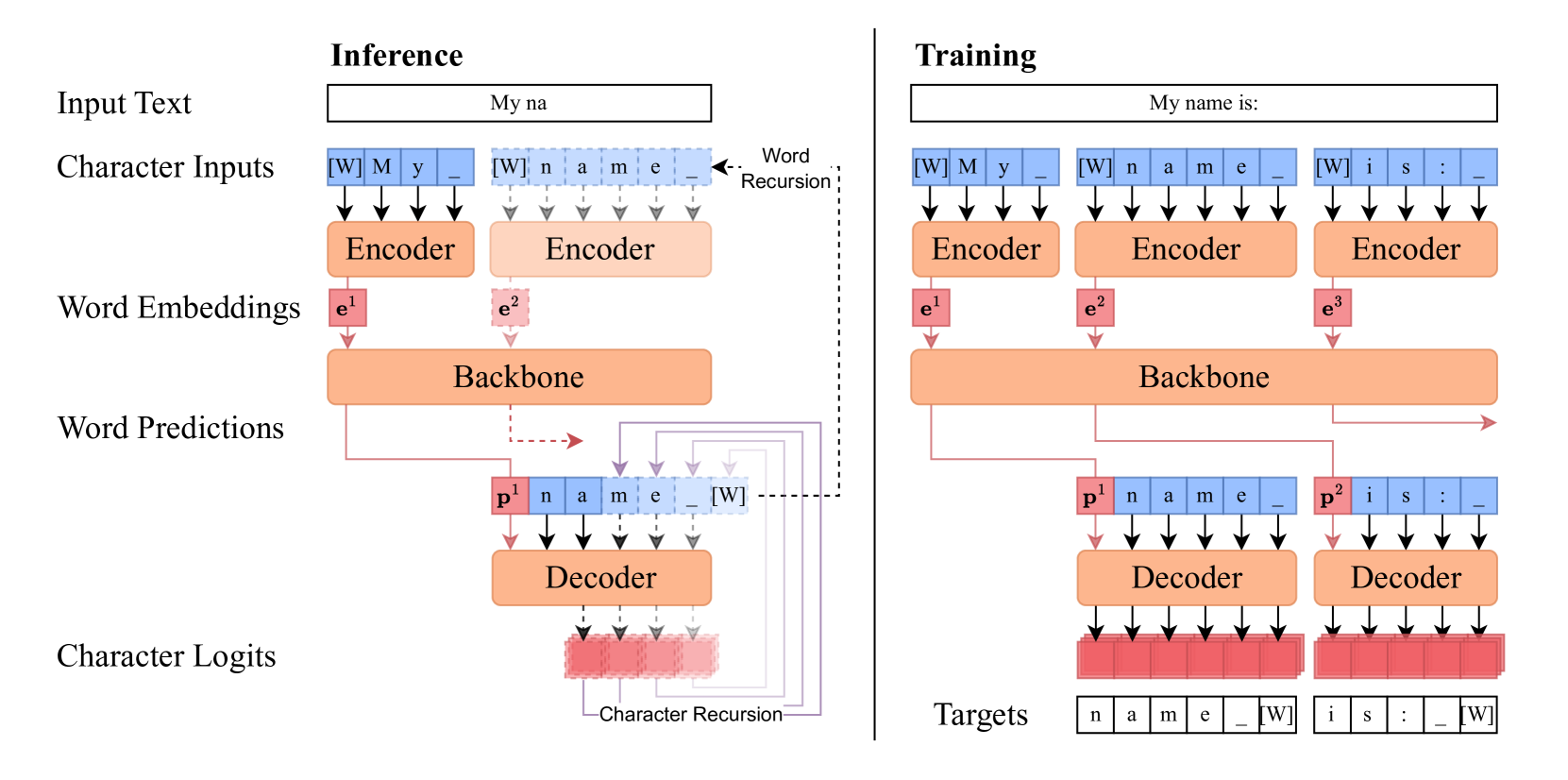
Schematic of the Hierarchical Autoregressive Transformer architecture and its inference loop.
Evaluation Highlights
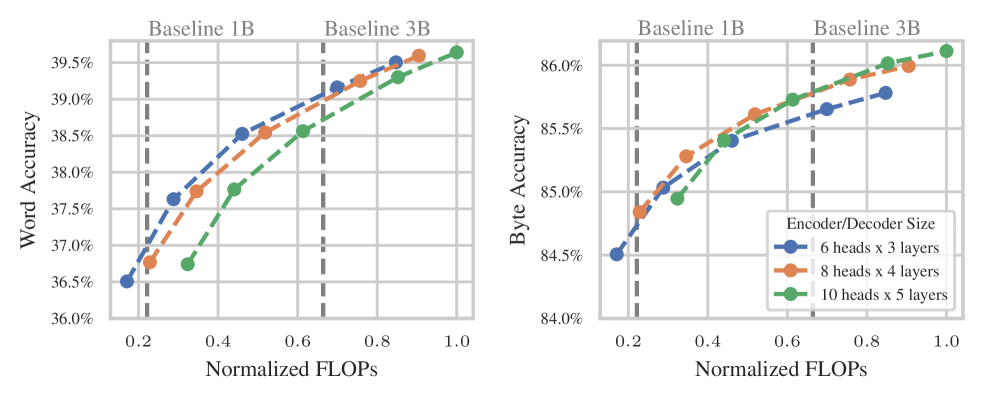
- Matches the downstream task performance of standard subword-based models (Llama architecture) at scales up to 7 billion parameters.
- Achieves superior performance and 2x faster training speed when adapting to a new language (German) compared to subword baselines.
- Demonstrates significantly greater robustness to input perturbations (typos/noise) than tokenizer-based models.
Breakthrough Assessment
8/10
Successfully scales a tokenizer-free, hierarchical approach to 7B parameters with competitive performance, solving major pain points of subword tokenization (robustness, adaptability) without the usual computational penalty of character-level models.