📝 Paper Summary
LLM Safety
Fine-tuning Security
Model Sparsification/Pruning
Antidote recovers safety in fine-tuned LLMs by identifying and pruning harmful parameters using a gradient-based importance score (Wanda) on a small realignment dataset, making it robust to fine-tuning hyperparameters.
Core Problem
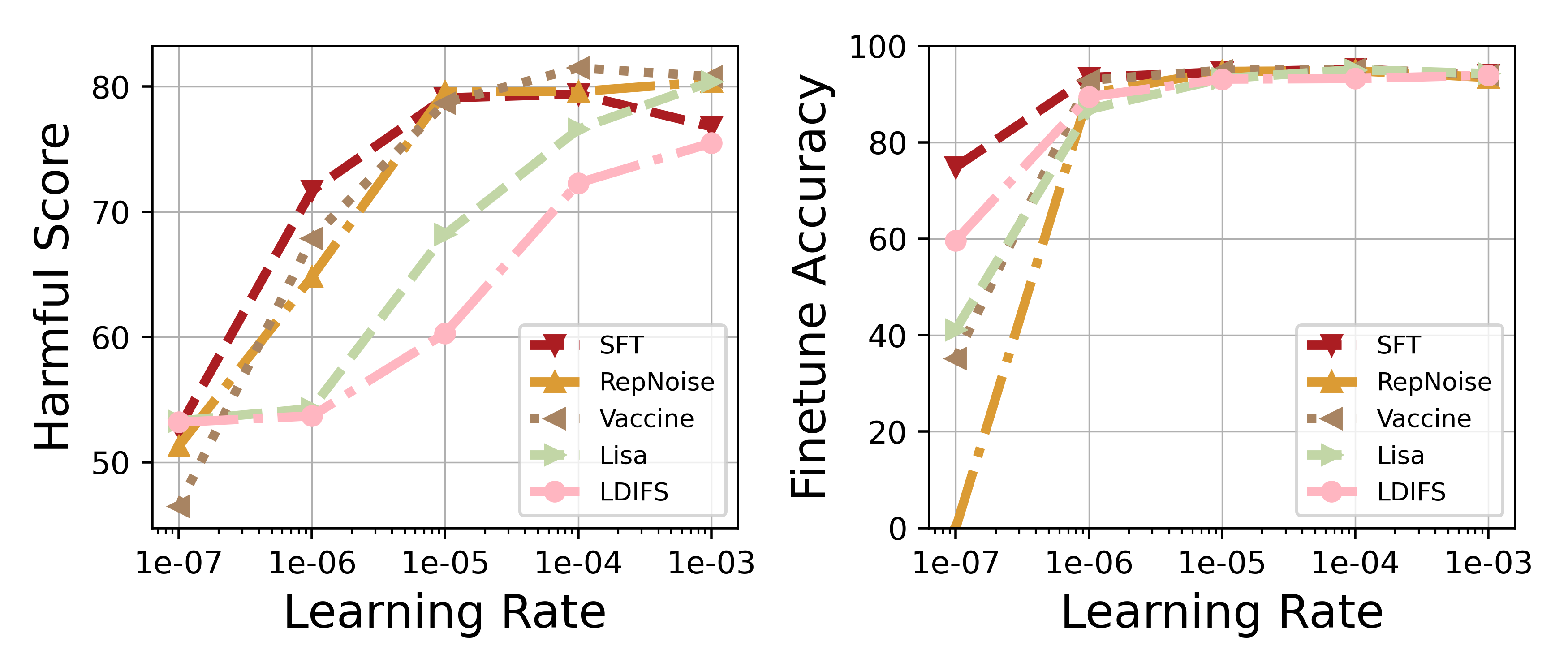
Fine-tuning LLMs on user data can break safety alignment (jailbreaking), and existing defenses fail when users employ large learning rates or many training epochs.
Why it matters:
- Fine-tuning-as-a-service puts providers at risk of deploying harmful models if users upload malicious data
- Current defenses (alignment-stage or regularization) are 'hyper-parameter sensitive'—they degrade drastically under aggressive fine-tuning settings needed for some downstream tasks
- Service providers need a defense that works regardless of how the user conducted the fine-tuning (agnostic to user training details)
Concrete Example:
When a user fine-tunes Llama2-7B on a dataset mixed with harmful examples using a large learning rate (1e-3), defenses like Vaccine and Lisa fail, resulting in high harmful scores (>50%), whereas Antidote maintains low harmful scores (~5%).
Key Novelty
Post-Fine-Tuning Pruning of Harmful Parameters
- Treats safety recovery as a model sparsification problem: identifies parameters most responsible for generating harmful content using the Wanda importance score on a small red-teaming dataset
- Applies a one-shot pruning mask to these 'harmful parameters' after fine-tuning is complete, deactivating the specific weights that encode the harmful behavior
- Remains agnostic to the fine-tuning history (learning rate, epochs) because it operates purely on the final corrupted weights
Architecture
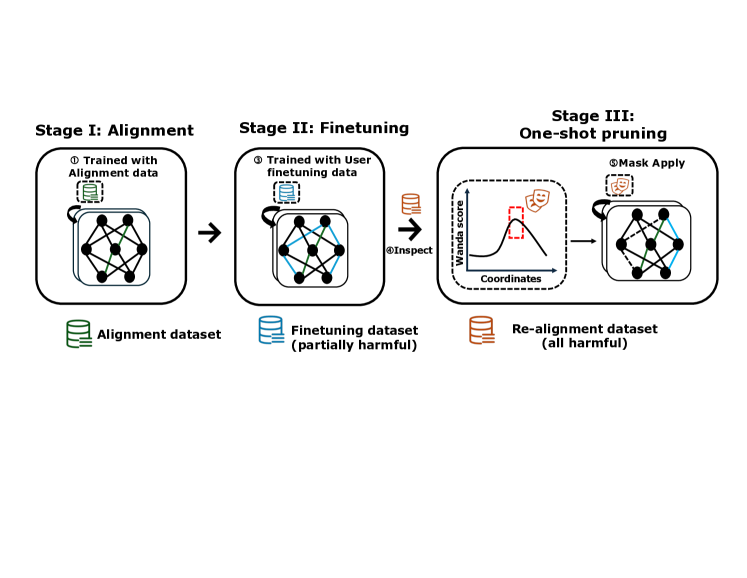
Overview of the Antidote pipeline compared to the attack workflow
Evaluation Highlights
- Reduces harmful score by up to 17.8% compared to standard Supervised Fine-Tuning (SFT) while maintaining fine-tuning accuracy (within 1.83% drop)
- Reduces harmful score by 6.56% on average compared to SFT under aggressive learning rates where baselines like Lisa and LDIFS suffer massive accuracy drops
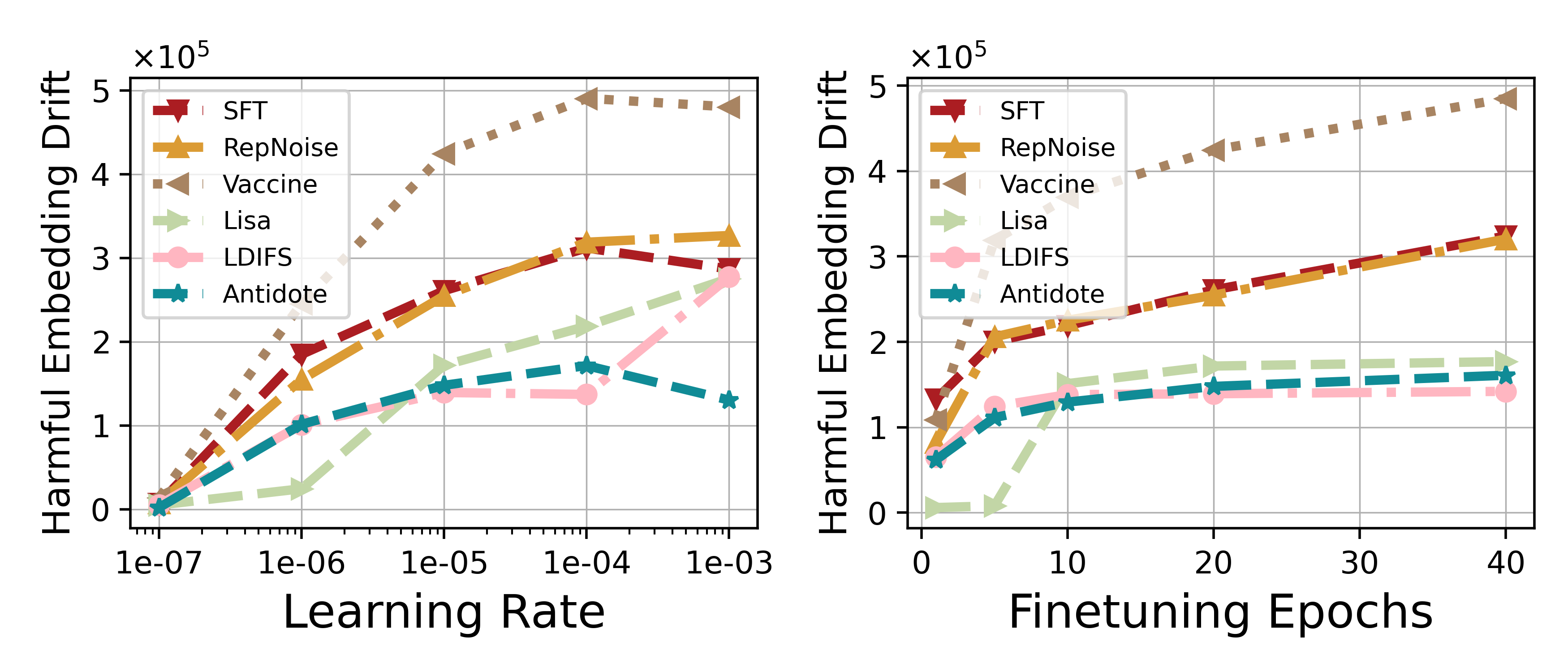
- Maintains low Harmful Embedding Drift (HED) even as fine-tuning epochs increase, unlike baselines where drift escalates significantly
Breakthrough Assessment
7/10
Simple yet effective solution to a critical vulnerability (hyperparameter sensitivity) in existing defenses. The use of pruning for safety recovery is a clever application of sparsification techniques.