📝 Paper Summary
Fine-Grained Visual Recognition (FGVR)
Multi-modal Large Language Models (MLLMs)
Fine-R1 enhances fine-grained visual recognition in MLLMs by combining structured chain-of-thought supervised fine-tuning with a triplet-augmented policy optimization that balances intra-class robustness and inter-class discrimination.
Core Problem
General-purpose MLLMs struggle with fine-grained visual recognition due to high intra-class variance and low inter-class variance, often overfitting to seen categories and failing to generalize to new ones without massive annotated data.
Why it matters:
- Distinguishing visually similar sub-categories (e.g., specific bird species) requires expert knowledge that general models lack, limiting real-world utility in domains like biology or industrial inspection.
- Existing solutions require costly large-scale annotations or overfit to closed sets, failing in open-world scenarios where new categories emerge constantly.
- Even state-of-the-art models like GPT-4 and GeminiPro underperform compared to specialized contrastive models (CLIP) on these discriminative tasks.
Concrete Example:
When identifying a bird, a standard MLLM might vaguely guess 'Flycatcher' or hallucinate a common species. It fails to notice subtle beak shape differences between an 'Acadian Flycatcher' and a 'Least Flycatcher' because it lacks a structured reasoning process to compare these candidates explicitly.
Key Novelty
Triplet Augmented Policy Optimization (TAPO) with CoT SFT
- First, Chain-of-Thought Supervised Fine-tuning (CoT SFT) teaches the model a structured reasoning routine: analyze visuals → propose candidates → compare → predict.
- Second, Triplet Augmented Policy Optimization (TAPO) uses reinforcement learning with triplets (anchor, positive, negative images) to enforce two behaviors: consistency across variations of the same class and distinct responses for visually similar but different classes.
Architecture
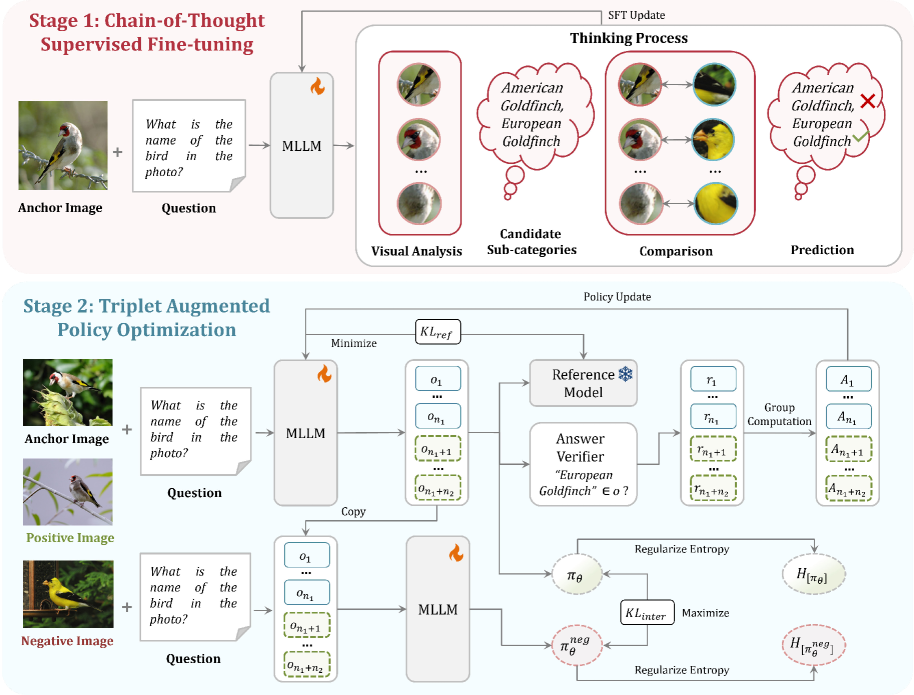
The two-stage training framework of Fine-R1 involving CoT SFT and Triplet Augmented Policy Optimization (TAPO).
Evaluation Highlights
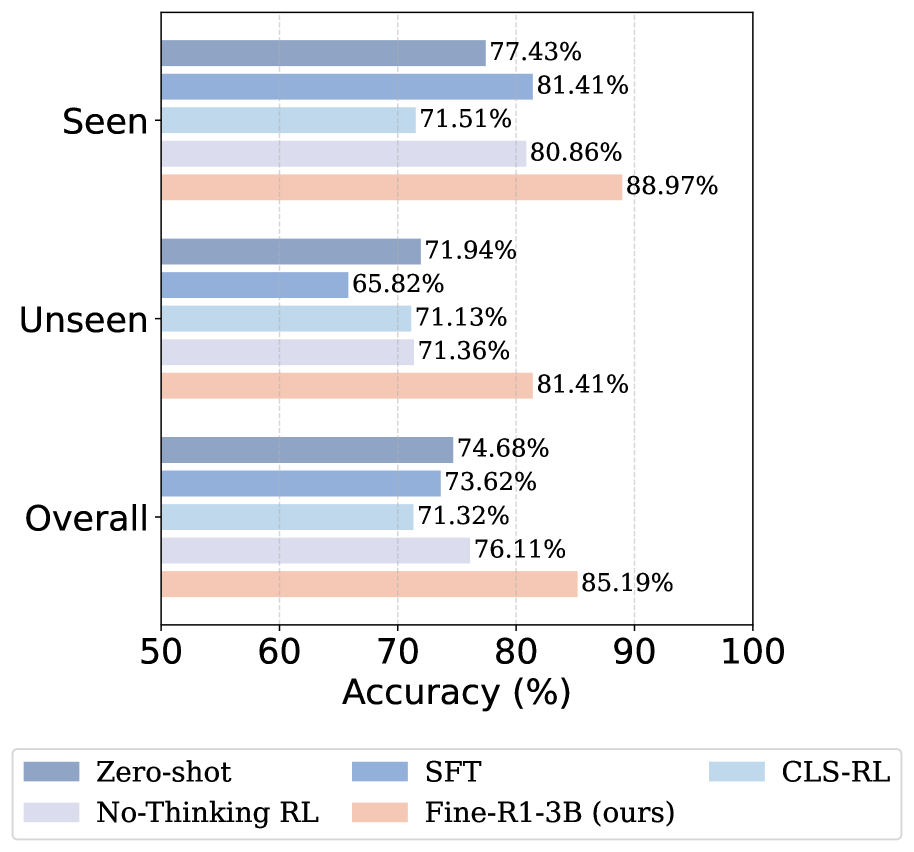
- Surpasses Qwen2.5-VL-7B by +23.75% on open-world fine-grained recognition.
- Outperforms specialized discriminative models like SigLIP-L by +4.27% in closed-world settings.
- Achieves +15.59% improvement over standard SFT on unseen categories (generalization), validating that the model learns to deploy knowledge rather than just memorizing.
Breakthrough Assessment
8/10
Significant performance jumps in the notoriously difficult FGVR domain, successfully beating both larger general MLLMs and specialized CLIP models while demonstrating strong generalization to unseen classes.