📝 Paper Summary
Parameter-Efficient Fine-Tuning
Neural Architecture Search
By systematically exploring design spaces, this paper discovers universal architectural patterns for parameter-efficient fine-tuning that outperform manually designed individual strategies.
Core Problem
Existing Parameter-Efficient Fine-Tuning (PEFT) strategies are typically hand-crafted and uniformly assigned across all network layers, ignoring potential structural optimizations.
Why it matters:
- Applying the same strategy to all layers is sub-optimal because different layers capture distinct levels of information (e.g., surface syntax vs. deep semantics)
- Discovering optimal tuning patterns improves model performance without increasing the parameter budget or computational overhead
- A unified design space perspective reveals universal patterns that generalize across different models and tasks, reducing manual engineering
Concrete Example:
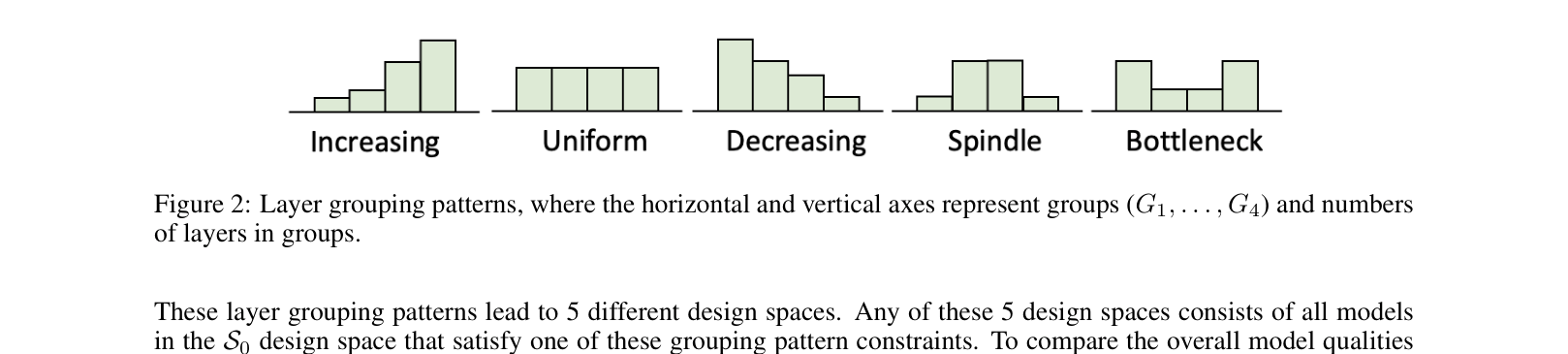
Instead of blindly adding Adapter modules to every single layer of a T5 model, systematically grouping layers into a "spindle" pattern (fewer layers at the ends, more in the middle) and assigning different strategies (e.g., LoRA early, BitFit later) yields higher validation accuracy under the exact same parameter budget.
Key Novelty
PEFT Design Spaces
- Defines a structured search space composed of four choices: how to group layers, how to allocate parameters, which groups to tune, and which specific tuning method to assign
- Progressively refines this design space by evaluating randomly sampled models and greedily keeping structural constraints that yield the highest validation performance
Architecture
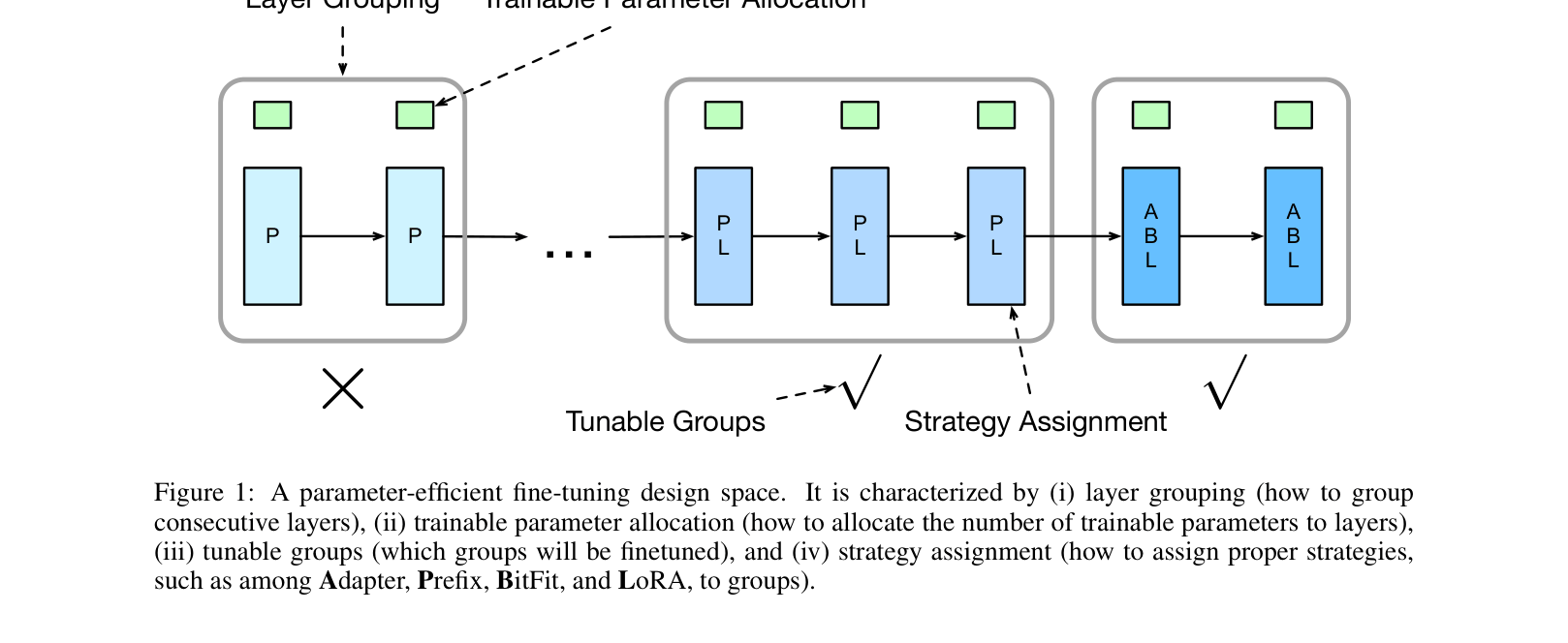
A visualization of the parameter-efficient fine-tuning design space components: Layer Grouping, Trainable Parameter Allocation, Tunable Groups, and Strategy Assignment
Evaluation Highlights
- +2.4 points on GLUE (General Language Understanding Evaluation) average score over the best PEFT baseline using T5-base with a 0.5% parameter budget
- Outperforms full fine-tuning by +1.2 points on GLUE using T5-base, demonstrating that proper PEFT design can surpass tuning all parameters
- Discovered design patterns transfer seamlessly to RoBERTa and BART backbones on summarization and translation tasks without requiring a new search process
Breakthrough Assessment
8/10
Shifting PEFT from manual individual method design to systematic design space exploration is a highly impactful conceptual step, yielding robust configurations that reliably beat strong baselines.