📝 Paper Summary
Parameter-Efficient Fine-Tuning (PEFT)
Large Language Models
Diffusion Models
Spectral Adapter fine-tunes the top singular vector space of pretrained weights (via additive or rotational updates) to improve parameter efficiency and multi-adapter fusion capabilities compared to standard LoRA.
Core Problem
Fine-tuning large models is computationally expensive, and existing PEFT methods like LoRA ignore the spectral structure of pretrained weights, potentially limiting rank capacity and complicating multi-adapter fusion.
Why it matters:
- Large model fine-tuning demands huge compute resources, making efficient methods critical for accessibility
- Current methods like LoRA can struggle with 'concept binding' when merging multiple adapters (e.g., in diffusion models), leading to identity loss
- Storing and exchanging full fine-tuned models is prohibitive; lightweight adapters are needed but must maintain high performance
Concrete Example:
In diffusion models, simply adding two LoRA adapters tuned for different objects (e.g., a specific dog and a specific cat) often fails to preserve both identities due to interference. Spectral Adapter assigns non-overlapping singular vector columns to different concepts, acting like frequency division in communications to fuse them cleanly.
Key Novelty
Fine-tuning in Spectral Space (Spectral Adapter)
- Decompose pretrained weights using SVD and fine-tune only the top singular vectors (the most 'energetic' directions) rather than adding random low-rank matrices
- Two variants: Additive (Spectral Adapter_A) updates singular vectors directly, while Rotational (Spectral Adapter_R) multiplies them by orthogonal rotation matrices
- Provides a natural mechanism for multi-adapter fusion by allocating distinct columns of the singular space to different tasks/concepts
Architecture
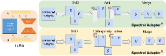
Diagram of the Spectral Adapter architecture. It shows the decomposition of the pretrained weight W into U, S, V, and the application of trainable parameters (A_U, A_V) to the top-r components (U1, V1).
Evaluation Highlights
- Spectral Adapter_A outperforms LoRA and DoRA on GSM8K with Mistral 7B (38.82% vs 35.86% for LoRA)
- Achieves higher average GLUE score (88.03) than LoRA (86.47) and DoRA (86.57) with DeBERTaV3-base using equal parameter budget
- Theoretically proves double the rank capacity of LoRA for the same number of trainable parameters
Breakthrough Assessment
7/10
Strong theoretical grounding (rank capacity) and empirical improvements over LoRA/DoRA. The specific application to multi-adapter fusion via orthogonal column allocation is a clever, distinct contribution.