📝 Paper Summary
Supervised Fine-Tuning (SFT)
Parameter-Efficient Fine-Tuning (PEFT)
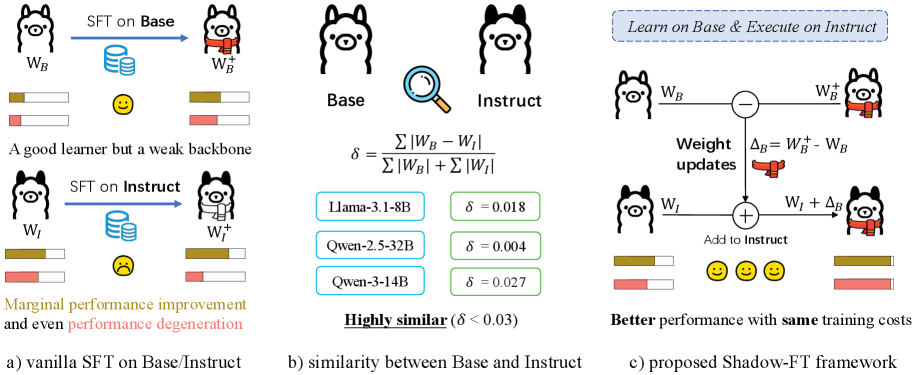
Shadow-FT mitigates performance degradation during fine-tuning by training the Base model (the 'shadow') instead of the Instruct model, then grafting the weight updates directly onto the Instruct model.
Core Problem
Directly fine-tuning instruction-tuned (Instruct) models often yields marginal gains or causes catastrophic forgetting and performance degeneration on downstream tasks.
Why it matters:
- Users frequently need to adapt powerful Instruct models to specific domains without losing their general instruction-following capabilities.
- The standard practice of tuning Instruct models breaks their carefully aligned internal representations, leading to worse reasoning and coding performance.
- Current methods force a trade-off between learning new domain knowledge and retaining the robust alignment of the Instruct model.
Concrete Example:
When fine-tuning Qwen-3-4B-Instruct on the BAAI-2k dataset using conventional LoRA, the model suffers a drop of 6.8 points on the Code-3 benchmark (from 66.4 to 59.6) instead of improving.
Key Novelty
Shadow-FT (Shadow Fine-Tuning)
- Leverages the high weight similarity between paired Base and Instruct models to use the Base model as a stable 'shadow' for training.
- Calculates weight updates (deltas) by fine-tuning the Base model on the target data, avoiding the rigid optimization resistance often found in Instruct models.
- Directly adds these learned deltas to the frozen Instruct model's weights, effectively transferring new knowledge without disrupting existing alignment.
Architecture
Conceptual workflow of Shadow-FT vs Traditional Tuning. Note: The paper describes this in Section 3 text and equations rather than a single explicit architecture diagram, but the logic is clear.
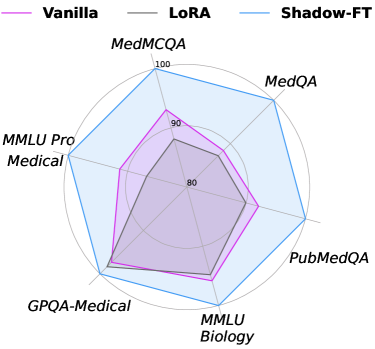
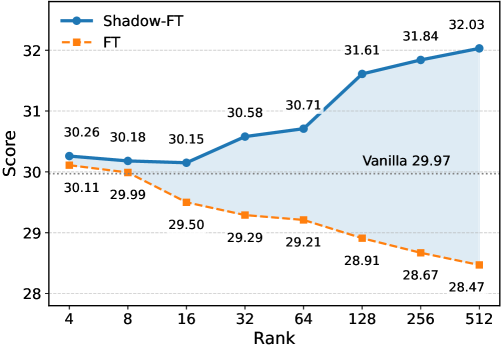
Evaluation Highlights
- Outperforms conventional LoRA by +10.1 points on Code-3 benchmark when tuning Qwen-3-4B (69.7 vs 59.6).
- Achieves +6.2 points improvement on Math-7 with Qwen-3-8B on Code-Z1 dataset compared to standard LoRA (77.4 vs 71.2).
- Scales effectively to Multimodal LLMs, boosting Gemma-3-27B performance on ChartQA by +3.52 points over vanilla LoRA.
Breakthrough Assessment
8/10
Simple yet highly effective method that solves a pervasive problem (tuning degradation) with zero inference cost. The insight about weight similarity and gradient dynamics between Base/Instruct is significant.