📊 Experiments & Results
Evaluation Setup
Lexical alignment evaluation using cosine similarity of word embeddings
Benchmarks:
- Custom Swahili-English Word Pair Dataset (Cross-lingual lexical alignment) [New]
Metrics:
- Average Cosine Similarity
- Statistical methodology: Paired t-test
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| TLI significantly improves alignment for trained word pairs compared to the base model. | ||||
| Trained Set (623 pairs) | Average Cosine Similarity | 0.3211 | 0.4113 | +0.0902 |
| Improvements generalize to unseen control words, indicating mechanism learning rather than memorization. | ||||
| Control Set (63 unseen pairs) | Average Cosine Similarity | 0.3143 | 0.4033 | +0.0890 |
Experiment Figures
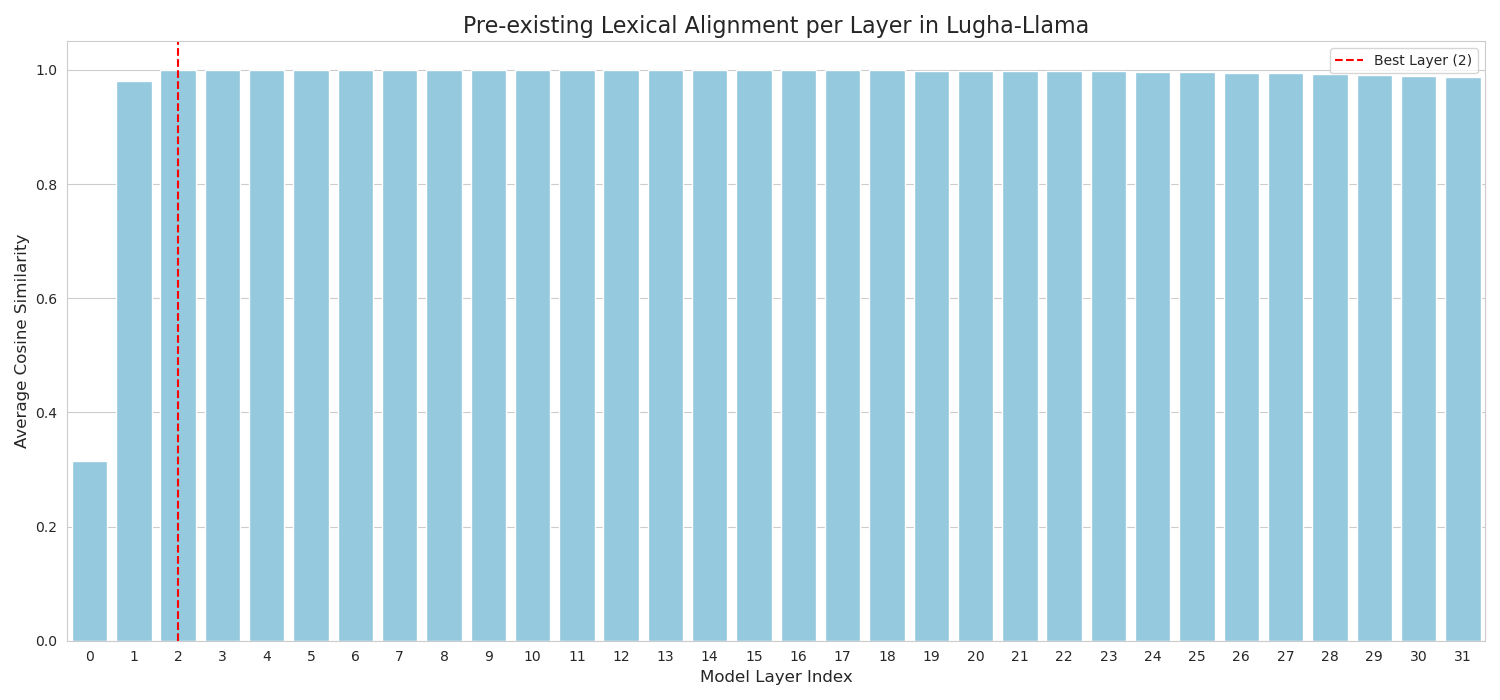
Layer-wise average cosine similarity for Swahili-English pairs in the base model (Pre-TLI)
Main Takeaways
- Base model (Lugha-Llama) has near-perfect lexical alignment in early layers (Layer 2) which degrades significantly by the output layer.
- TLI successfully injects this early-layer knowledge into the final representations, improving output alignment by ~28%.
- The method generalizes to unseen words, suggesting it refines the model's internal processing pathways rather than just memorizing the training set.