📝 Paper Summary
Parameter-Efficient Fine-Tuning (PEFT)
Visual Prompt Tuning
Self-Prompt Tuning (SPT) initializes visual prompts using downstream token prototypes or samples to maximize mutual information with patch tokens, significantly improving adaptation of self-supervised models.
Core Problem
Standard Visual Prompt Tuning (VPT) suffers from sensitivity to initialization/prompt length and performs poorly when adapting self-supervised pre-trained models (like MAE) compared to supervised ones.
Why it matters:
- VPT is a key parameter-efficient alternative to full fine-tuning for massive ViT models (e.g., ViT-H, ViT-22B), where full tuning is computationally prohibitive.
- Self-supervised pre-training (e.g., MAE) scales better with unlabeled data than supervised pre-training, but current prompt tuning methods fail to effectively unlock this potential.
- Existing random initialization strategies for prompts lead to slow convergence and instability, hindering practical deployment.
Concrete Example:
When adapting an MAE pre-trained ViT-B to a downstream task using standard VPT with random initialization, accuracy lags significantly behind full fine-tuning. The prompts struggle to align with the patch token distribution, resulting in suboptimal contextualization.
Key Novelty
Self-Prompt Tuning (SPT)
- Initializes learnable prompt tokens using prototypes (clustered centers) or simple samples (random/mean/max pooling) of the downstream data's patch tokens.
- Leverages the discovery that high mutual information between prompts and patch tokens at initialization accelerates convergence and boosts final performance.
- Optimizes the computationally expensive clustering step with a random sampling strategy that incurs negligible cost while maintaining performance gains.
Architecture
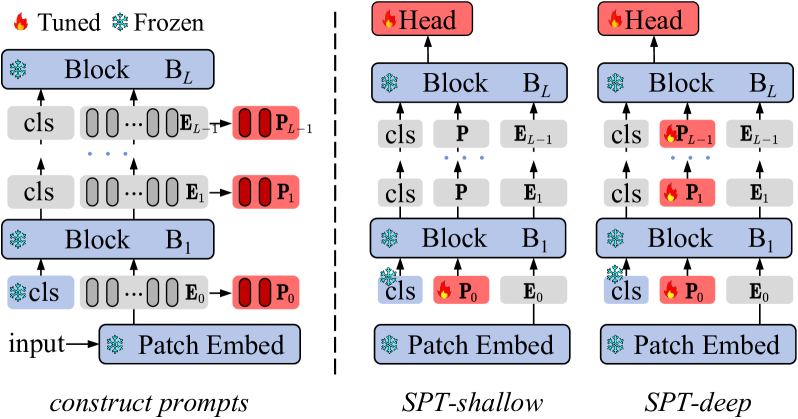
Conceptual illustration of Self-Prompt Tuning (SPT). It shows the process of feeding training images into the pre-trained backbone, obtaining patch tokens, clustering them into prototypes, and using these prototypes to initialize the prompt tokens P.
Evaluation Highlights
- Improves average accuracy by up to 10%~30% relative to standard VPT after MAE pre-training on benchmark datasets.
- Outperforms Full Fine-tuning in 19 out of 24 evaluated cases while updating less than 0.4% of the model's parameters.
- Random sampling initialization reduces setup time from ~27 days (clustering) to ~43 seconds while matching the accuracy benefits.
Breakthrough Assessment
8/10
Significantly closes the gap between PEFT and full fine-tuning for self-supervised models. The finding that simple sampling works as well as clustering makes it highly practical.
