📊 Experiments & Results
Evaluation Setup
Math reasoning evaluation on in-domain and out-of-domain datasets
Benchmarks:
- DAPO-Math-17k (English subset) (Math reasoning)
- IFEval (Instruction following (OOD))
- Connect4 (GAMEBoT) (Strategic reasoning (OOD)) [New]
Metrics:
- Accuracy
- IFEval Score
- Statistical methodology: Not explicitly reported in the paper
Experiment Figures
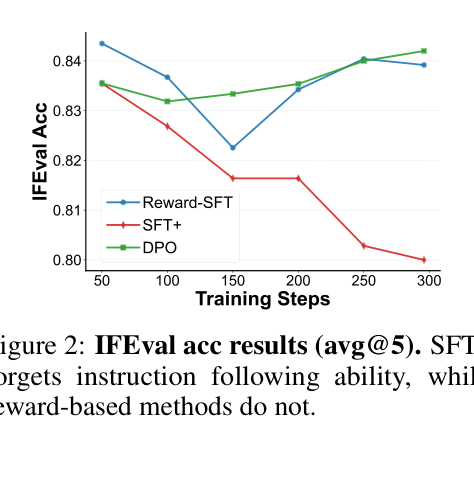
IFEval performance (OOD generalization) over training steps for SFT+, DPO, and Reward-SFT.
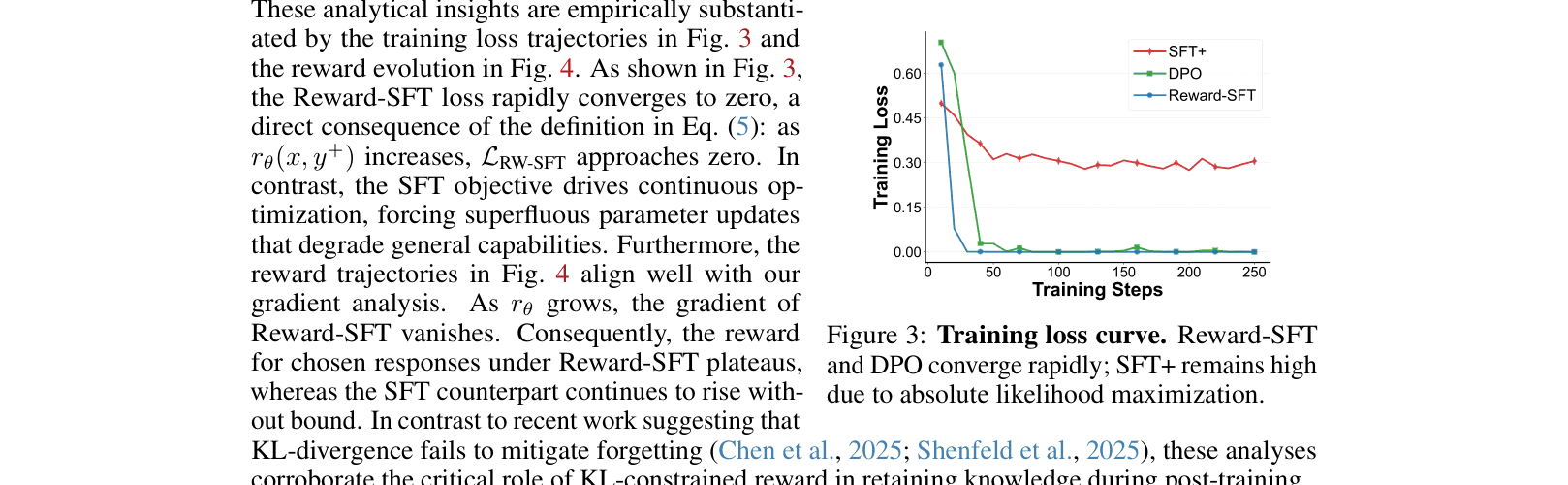
Training loss trajectories and reward evolution for SFT vs. Reward-SFT.
Main Takeaways
- Data proximity (rectified data) is necessary but insufficient to prevent forgetting; SFT on rectified data still forgets.
- The implicit reward formulation in DPO and SPoT acts as a regularizer ('Elastic Tether') that naturally stops updates on well-learned samples, preserving prior knowledge.
- Positive-only training (SFT) suffers from the 'pull-up' effect, increasing probabilities of both correct and incorrect responses; negative supervision is crucial for sharp reasoning boundaries.
- SPoT achieves significant accuracy gains (+6.2%) with minimal data (4k pairs) and training time (28 mins) by combining surgical data with a tethered binary objective.