📝 Paper Summary
Theoretical Machine Learning
Data Augmentation
This paper models synthetic data generation as a Markov chain and uses a reverse-bottleneck framework to theoretically explain how synthetic data improves Large Language Model generalization.
Core Problem
Synthetic data is widely used in Large Language Model (LLM) post-training due to sparse real data, but there is a significant theoretical gap regarding why and how it improves generalization.
Why it matters:
- Without a formal theoretical framework, predicting the effectiveness of synthetic data across different downstream applications remains largely empirical and inconsistent
- Current generation methods vary wildly in quality, potentially carrying over biases or failing to address real-world complexities
- A rigorous understanding is required to optimize generative models for more targeted and efficient data synthesis
Concrete Example:
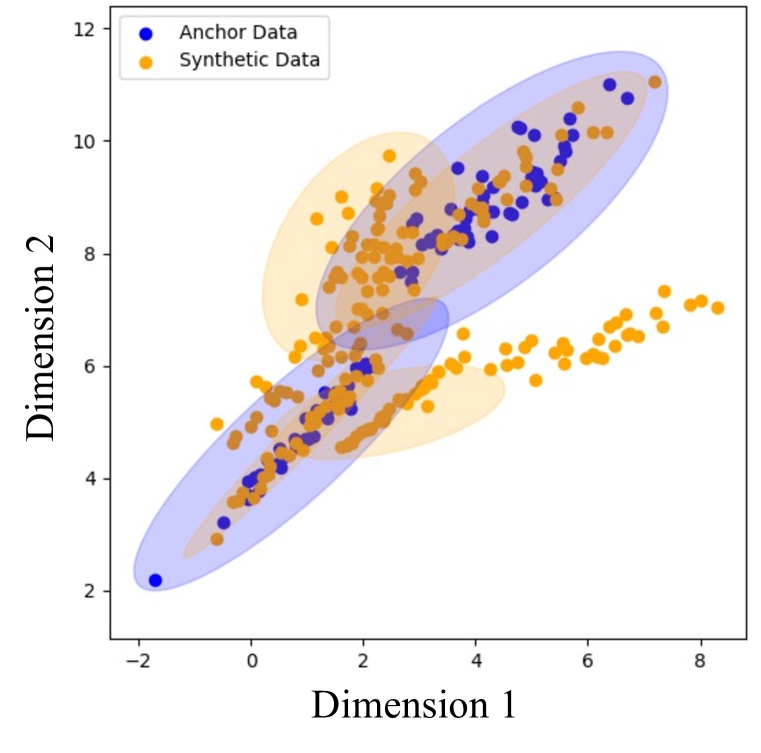
If an LLM is post-trained on synthetic data generated without strict prompt engineering, the generation divergence becomes too high; the synthetic distribution broadens excessively beyond the target task, causing the post-trained LLM to generalize poorly.
Key Novelty
Reverse-Bottleneck Perspective for Synthetic Data
- Models data generation as a Markov chain where anchor data is transformed into a prompt, conditioning a generative model to produce synthetic outputs
- Proposes a reverse-bottleneck framework linking the post-trained model's generalization capabilities directly to the information gain supplied by the generative model
- Introduces Generalization Gain via Mutual Information (GGMI) to quantify how distribution matching limits generalization error
Architecture
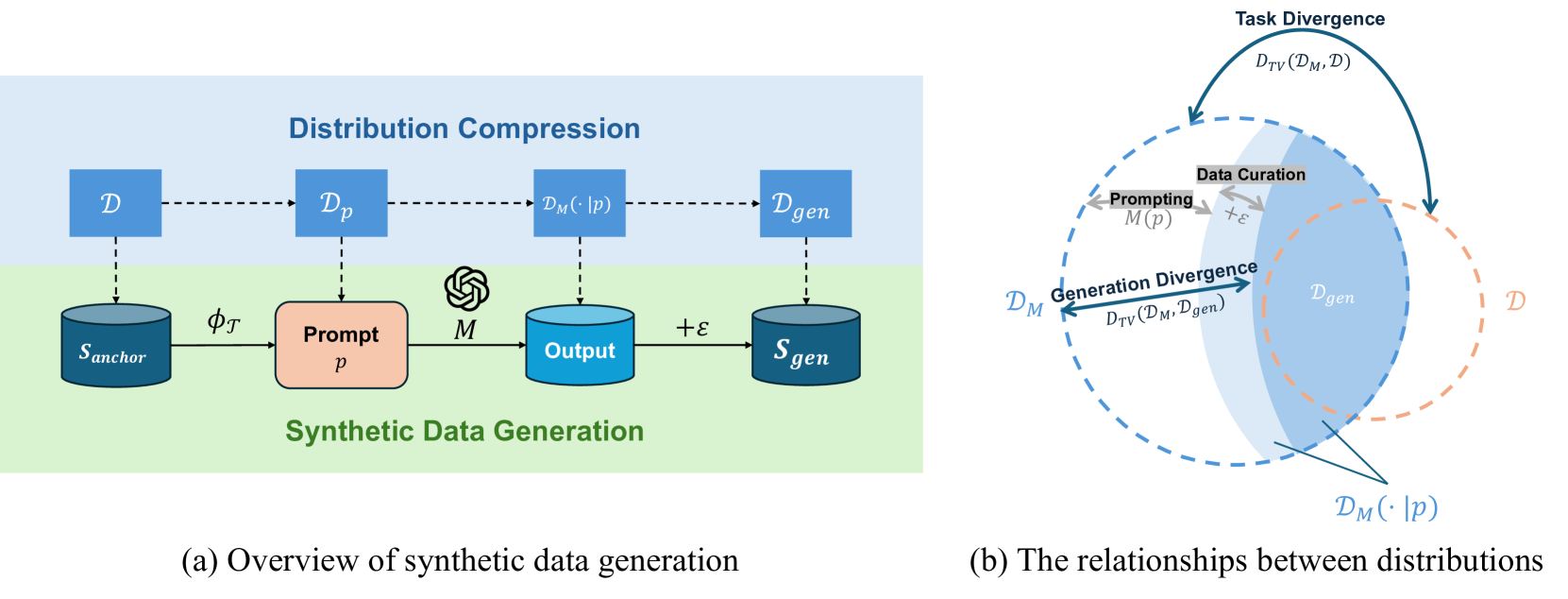
The overall synthetic data generation process and its corresponding theoretical distribution shifts.
Breakthrough Assessment
7/10
Provides a much-needed formal mathematical framework for the highly empirical practice of synthetic data post-training, establishing provable bounds based on distribution divergences.