📝 Paper Summary
Post-Training Quantization (PTQ)
Neural Scaling Laws
Efficient Inference
This study establishes empirical scaling laws for post-training quantization and proposes a Random Forest regressor that accurately predicts the inference loss of quantized LLMs using features of the local loss landscape.
Core Problem
While pre-training follows predictable scaling laws, the quality of Large Language Models (LLMs) after post-training quantization (PTQ) is highly unpredictable and often requires expensive trial-and-error validation.
Why it matters:
- PTQ introduces significant uncertainty, obscuring the return on investment for deploying compressed models
- Finding the optimal quantization format and model size under fixed constraints is time and compute intensive due to the vast search space
- Current approaches lack practical guidance on how model size, data format, and optimization algorithms interact to affect final model quality
Concrete Example:
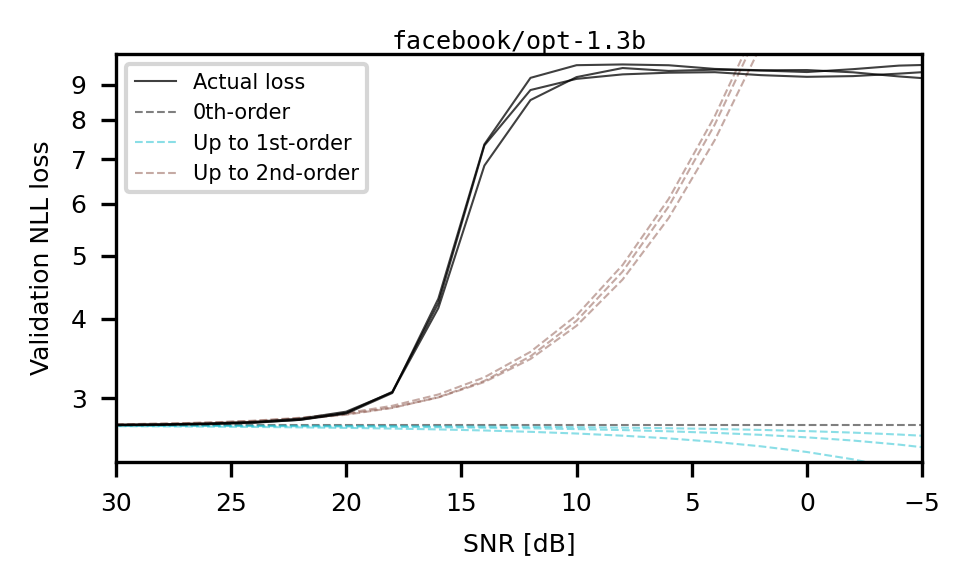
A developer attempting to compress opt-1.3b might find that GPTQ optimization greatly improves performance for the mxint3_128 format, but only marginally improves 6-bit, 4-bit, or 2-bit formats, a non-monotonic behavior that is difficult to predict without running the full process.
Key Novelty
Predictive Statistical Model for PTQ Quality
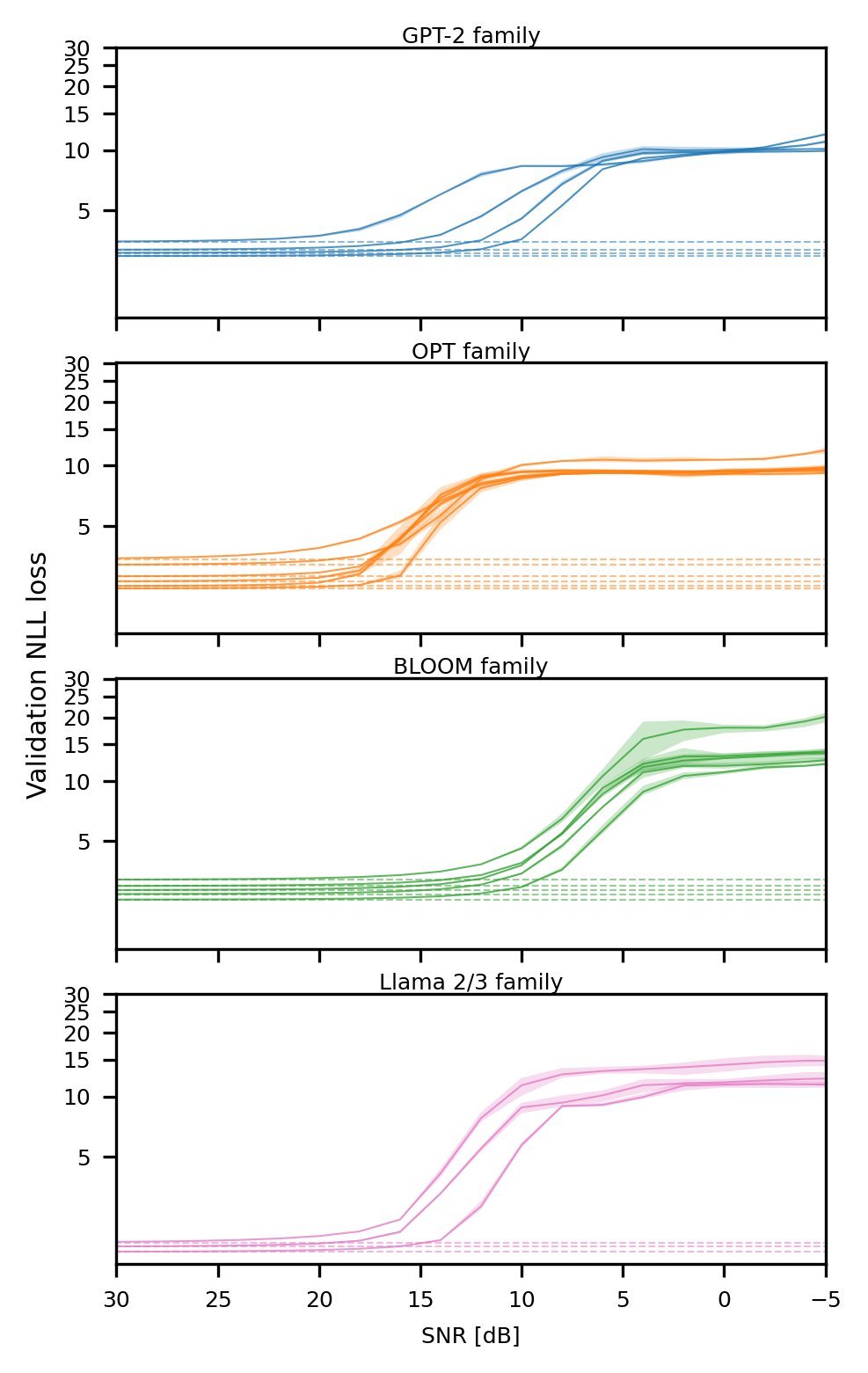
- Identifies that larger models have systematically flatter local loss landscapes, which dictates their sensitivity to quantization noise
- Constructs a statistical regressor (Random Forest) that inputs model properties (size, pre-trained loss) and quantization specifics (SQNR, format) to predict the final quantized loss without full evaluation
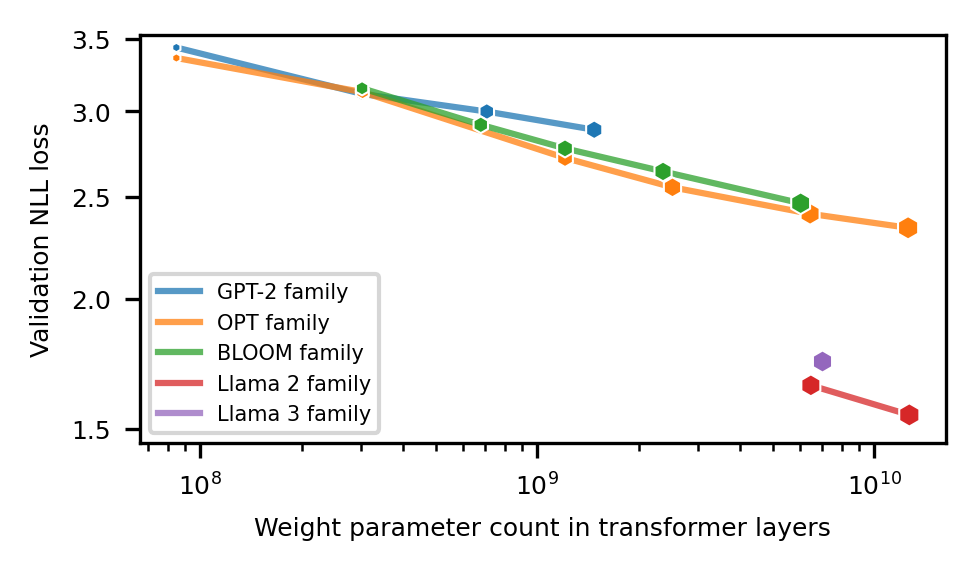
- Establishes a 'Pareto frontier' quantifying the trade-off between model size and bit precision across multiple LLM families
Architecture
Visualization of scaling laws (Left) and the typical local loss landscape (Right).
Evaluation Highlights
- Demonstrates that the Random Forest model can predict post-quantization loss for unseen model families (Pythia-1b, MPT-7b) using scaling laws derived from separate families (GPT-2, Llama, etc.)
- Identifies a specific Signal-to-Noise Ratio (SNR) window (~20 dB) where the GPTQ algorithm is most effective due to the 'step-like' nature of radial loss profiles
- Validates scaling laws across 5 diverse LLM families (GPT-2, OPT, BLOOM, Llama 2, Llama 3) and 36 distinct Microscaling (MX) data formats
Breakthrough Assessment
7/10
Provides a significant methodological advance by turning PTQ from a trial-and-error process into a predictable one governed by scaling laws, though specific performance improvements on benchmarks are not the primary focus.