📊 Experiments & Results
Evaluation Setup
Mathematical reasoning and code generation tasks
Benchmarks:
- GSM8K (Grade school math reasoning)
- MATH (Challenging math problems)
- MBPP+ (Python code generation)
- Game-of-24 (Mathematical reasoning game)
- AIME 2024 (High-difficulty math competition)
Metrics:
- pass@k
- Verifier Efficiency (AUC of pass@k vs k)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Inference-time experiments demonstrate that selecting responses via representation-based exploration (RepExp) yields higher pass rates for lower k budgets compared to random sampling. | ||||
| Various (GSM8K, MATH, MBPP+, Game-of-24) | Verifier Efficiency Improvement | 0 | 50 | +50 |
| Post-training experiments show RepExp significantly improves sample efficiency and prevents performance degradation at high k (diversity collapse). | ||||
| AIME 2024 | pass@80 equivalent | See Note | See Note | 3x efficiency |
| MATH | Sample Efficiency | See Note | See Note | >2x |
Experiment Figures
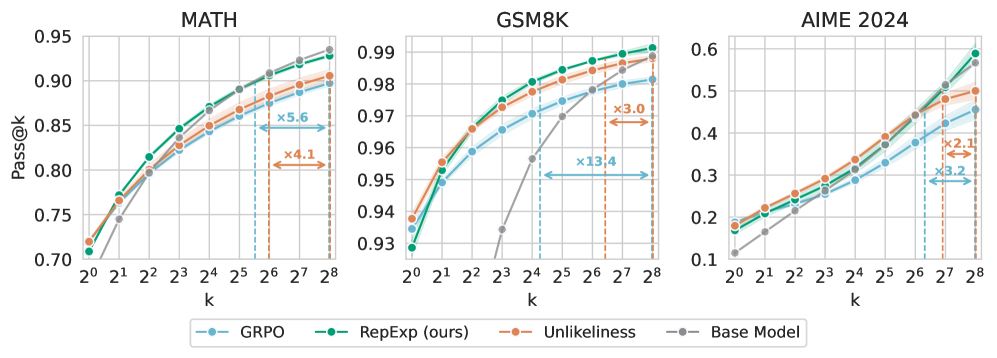
Pass@k curves for Base Model, GRPO, and RepExp (Ours) on AIME 2024.
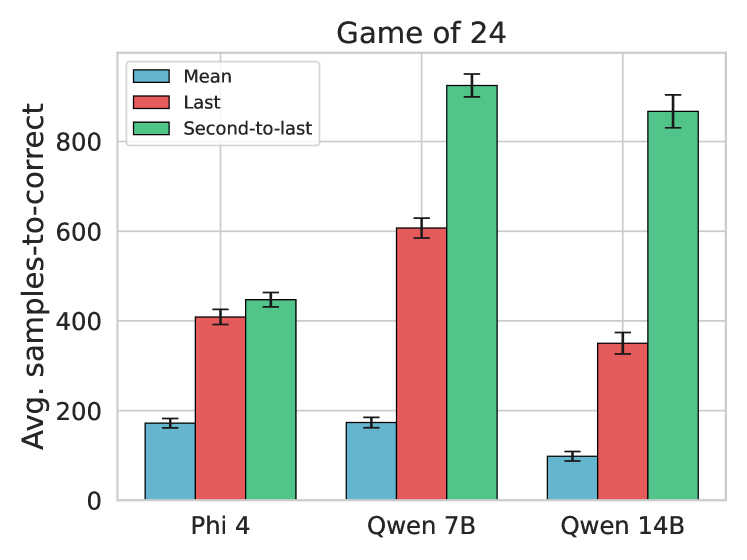
Ablation of representation choices (Average vs Last Token vs Penultimate Token).
Main Takeaways
- Representation-based exploration (RepExp) consistently improves verifier efficiency across diverse models and tasks (GSM8K, MATH, MBPP+).
- Integrating RepExp into RL post-training (GRPO) prevents 'diversity collapse,' allowing models to maintain high pass@k rates where baselines degrade.
- Averaging representations across all tokens captures better diversity information than using just the final token embedding.
- The method is effective both as a static inference-time filter and as a dynamic reward signal during training.