📝 Paper Summary
Post-training quantization (PTQ)
Training dynamics of Large Language Models
The degradation of Large Language Models during post-training quantization is driven by sharp learning rate decays and loss landscape curvature, rather than dataset size or training duration.
Core Problem
Existing studies claim that training LLMs on larger datasets inherently increases their susceptibility to quantization errors, suggesting a conflict between model scaling and deployment efficiency.
Why it matters:
- Discourages training models for longer durations if they are intended for low-bit deployment
- Current scaling laws for quantization (e.g., Kumar et al., 2024) may be confounding training duration with optimization dynamics (learning rate decay)
- Quantization brittleness limits the deployment of high-performance models on commodity hardware
Concrete Example:
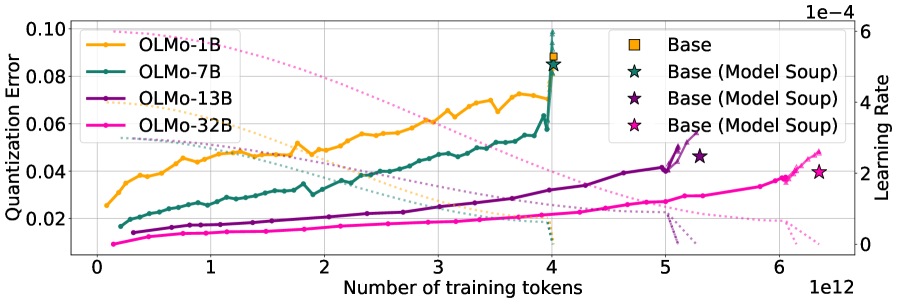
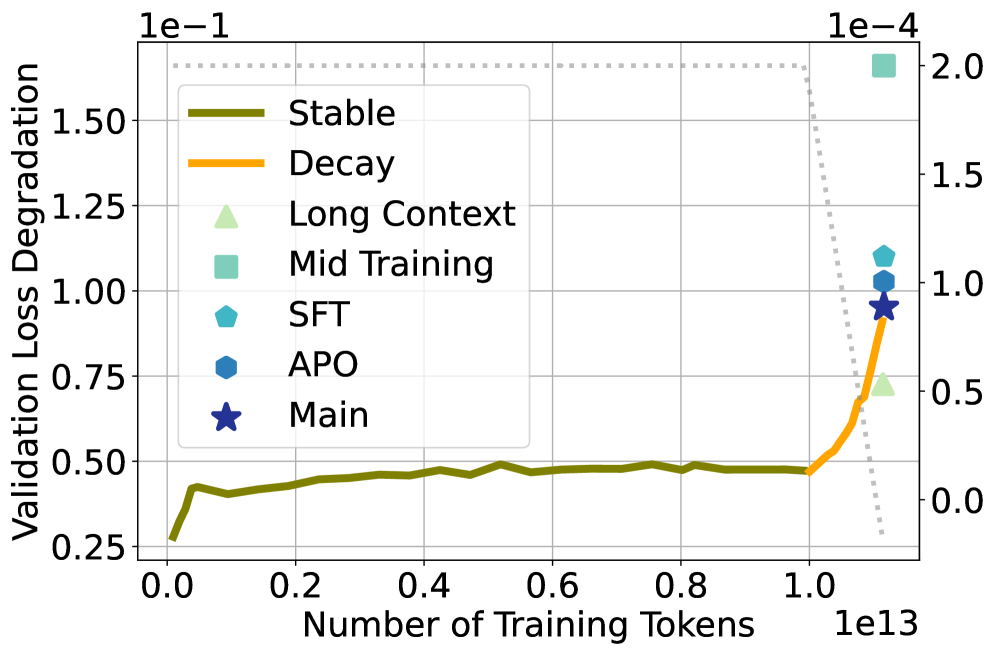
In the SmolLM3 training run, quantization error remains low and stable for 11 trillion tokens of training, but spikes abruptly only when the learning rate begins to decay, contradicting the idea that token count alone drives degradation.
Key Novelty
Learning Rate Decay as the Driver of Quantization Brittleness
- Disentangles 'training duration' from 'optimization dynamics' by showing that quantization error spikes specifically during the learning rate annealing phase (decay), not simply as more data is seen
- Demonstrates that maintaining a higher learning rate (via Warmup-Stable-Decay schedules) keeps quantization error low compared to Cosine schedules
- Identifies 'Model Soups' (weight averaging) as a technique to reverse quantization degradation, yielding lower errors than individual checkpoints
Architecture
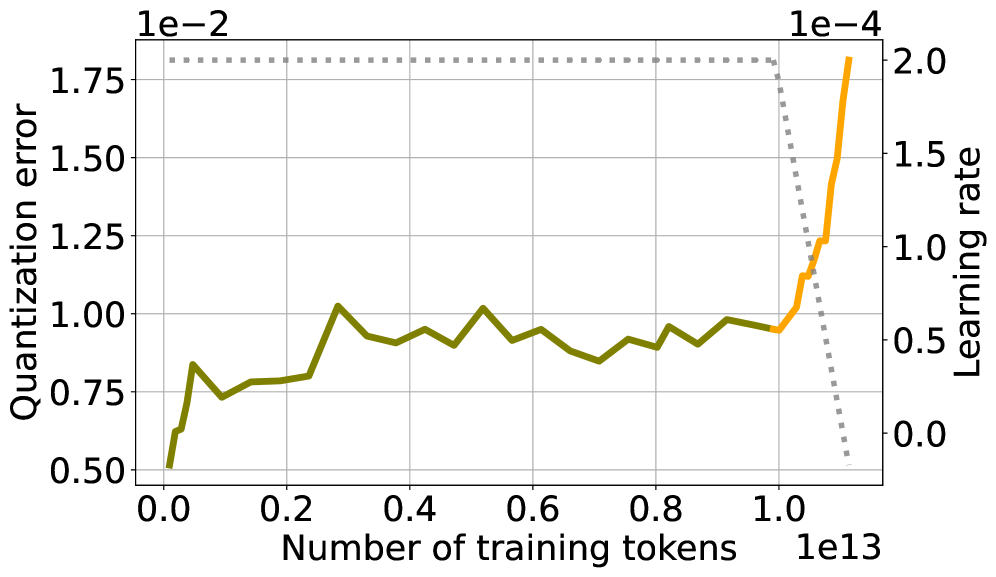
Trajectories of Quantization Error and Validation Loss overlayed with Learning Rate schedule for SmolLM3.
Evaluation Highlights
- Comprehensive analysis of quantization error across training trajectories of 6 open-source model families (up to 32B parameters and 15T training tokens)
- Controlled experiments up to 100B tokens isolate learning rate effects, refuting prior claims that data scale inherently causes degradation
- Demonstrates that Model Soups (averaging checkpoints) consistently reduce post-training quantization error compared to constituent models in OLMo2 and SmolLM3 families
Breakthrough Assessment
8/10
Significantly challenges the prevailing wisdom on quantization scaling laws. By identifying learning rate schedules as the true cause of brittleness, it offers actionable recipes (WSD schedules, soups) to improve deployment efficiency.