📊 Experiments & Results
Evaluation Setup
Pre-training and instruction-tuning small transformers with mixed symbolic data
Benchmarks:
- PlatinumBench (Reliability in math, logic, and table understanding)
- General Language Modeling (Test Sets) (Next-token prediction on FineWeb/Dolci/SYNTH test splits)
Metrics:
- Negative Log Likelihood (NLL) on answers
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Mixing Reasoning Core data consistently improves reasoning performance (lower NLL) on PlatinumBench across different base datasets. | ||||
| PlatinumBench (FineWeb) | NLL (Lower is better) | 0.86 | 0.78 | -0.08 |
| PlatinumBench (SYNTH) | NLL (Lower is better) | 0.76 | 0.70 | -0.06 |
| PlatinumBench (Dolci) | NLL (Lower is better) | 0.68 | 0.62 | -0.06 |
Experiment Figures
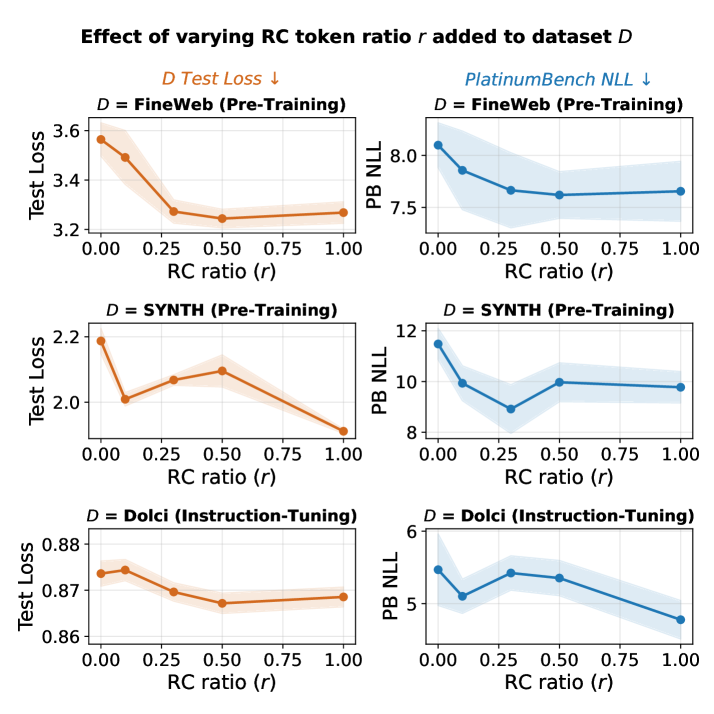
Impact of mixing Reasoning Core data (ratio r) on PlatinumBench NLL and General Validation Loss
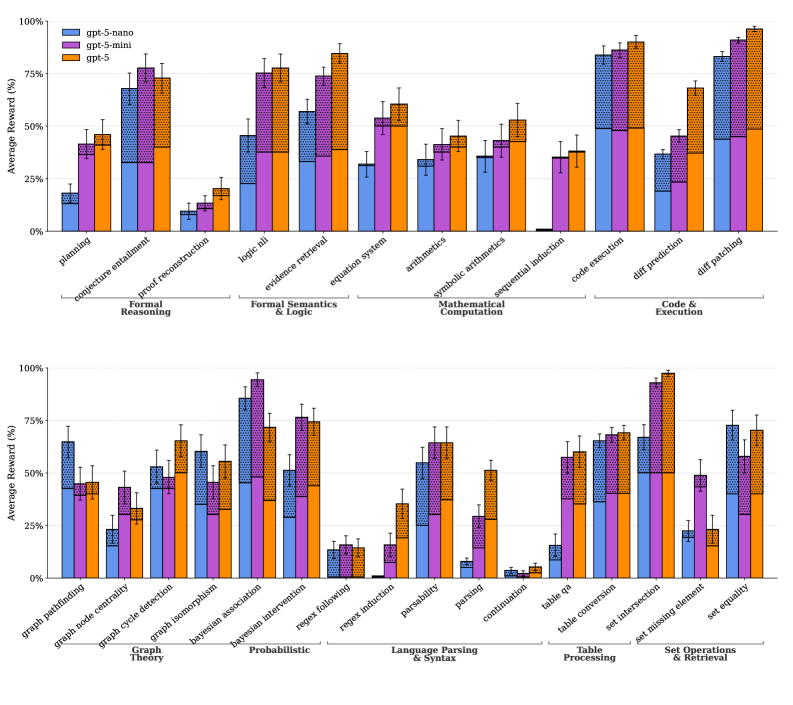
Zero-shot average reward of GPT-5 on Reasoning Core tasks at Easy (lvl 0) vs Hard (lvl 5) difficulty
Main Takeaways
- Optimal mixing ratio appears to be r=0.5 (adding 50% symbolic tokens relative to original data size), minimizing reasoning NLL.
- Symbolic data injection does not degrade general language modeling performance; in some cases (e.g., FineWeb), validation loss slightly improves.
- Procedural generation allows creating pre-training scale data (billions of tokens) at negligible marginal cost compared to web scraping.
- Zero-shot probing confirms the generated tasks are non-trivial, with significant performance drops for GPT-5 when moving from difficulty level 0 to 5.