📝 Paper Summary
Multimodal Reinforcement Learning
RLHF / Post-training
MAPLE improves multimodal RL post-training by conditioning policy optimization and curriculum on the minimal required modality subset for each task, rather than treating all input signals as uniformly relevant.
Core Problem
Existing multimodal RL post-training treats all inputs (video, audio, text) as equally relevant, ignoring that many tasks only require a subset of signals.
Why it matters:
- Treating all modalities as a single joint distribution inflates policy-gradient variance due to heterogeneous reward scales across modality subsets
- Modality-blind training degrades robustness in real-world deployments where signals may be missing or noisy (e.g., audio-only queries)
- Omni-modal models suffer from 'missing-at-test' failures when trained on redundant full-signal batches but evaluated on partial inputs
Concrete Example:
A model trained always receiving video+audio+text might fail a 'describe this sound' query if the video feed drops at test time, because it learned to over-rely on visual cues rather than solving the audio-specific reasoning.
Key Novelty
Modality-Aware Policy Optimization (MAPO)
- Stratifies training batches by 'Required Modality Tags' (RMTs) so that rewards are normalized only against other examples requiring the same signal subset (e.g., audio-tasks vs. audio-tasks)
- Uses an adaptive curriculum that prioritizes harder modality combinations based on KL divergence history, ensuring the model learns weak signal patterns before dominant ones
Architecture
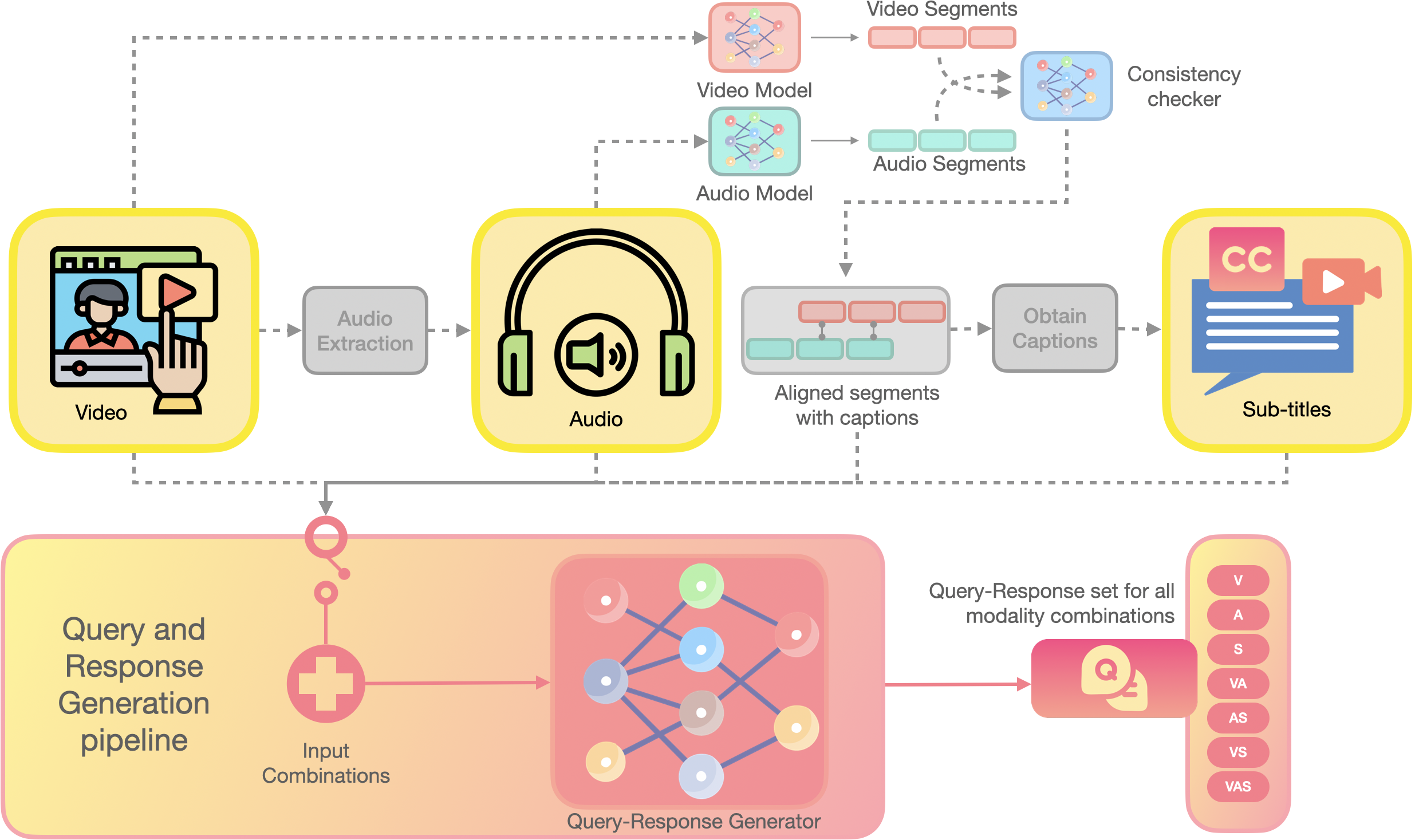
The data curation and training pipeline for MAPLE, showing how seed videos are processed into modality-annotated samples (RMTs) which then guide the stratified policy optimization.
Evaluation Highlights
- Narrows the accuracy gap between uni-modal and multi-modal performance regimes by 30.24% compared to modality-blind baselines
- Converges 3.18x faster in wall-clock time than full-signal training by reducing gradient variance
- Reduces policy gradient variance by 12.89% on MAPLE-QA compared to the Modality-Unaware Policy Optimization (MUPO) baseline
Breakthrough Assessment
8/10
Addresses a fundamental inefficiency in multimodal post-training (heterogeneous signal relevance) with a theoretically grounded solution (stratified advantages) and a new dedicated benchmark.