📝 Paper Summary
Financial NLP
Domain Adaptation
Low-Resource Language NLP
This paper releases the first dedicated Indonesian financial language models and evaluation datasets, showing that post-training generic IndoBERT on financial texts improves performance on downstream tasks like sentiment analysis.
Core Problem
Existing Indonesian language models (IndoBERT) are trained on general domain text, lacking the specific vocabulary and nuances required for accurate financial analysis.
Why it matters:
- Financial institutions in Indonesia increasingly rely on unstructured text data for decision-making, but general models may misinterpret technical financial jargon.
- Most financial NLP research focuses on English (e.g., FinBERT), leaving a gap for specialized models in low-resource languages like Indonesian.
Concrete Example:
A general model might interpret a phrase like 'share buyback' neutrally, whereas a financial model understands it as a potentially positive signal for stock value.
Key Novelty
Indonesian Financial Post-Training & Benchmark Suite
- Continual pre-training of IndoBERT using a newly constructed corpus of Indonesian financial news and corporate reports to adapt the model to the financial domain.
- Creation of the first comprehensive Indonesian financial NLP benchmark, including a native sentiment dataset (IndoFinSent) and translated versions of standard English financial datasets.
Architecture
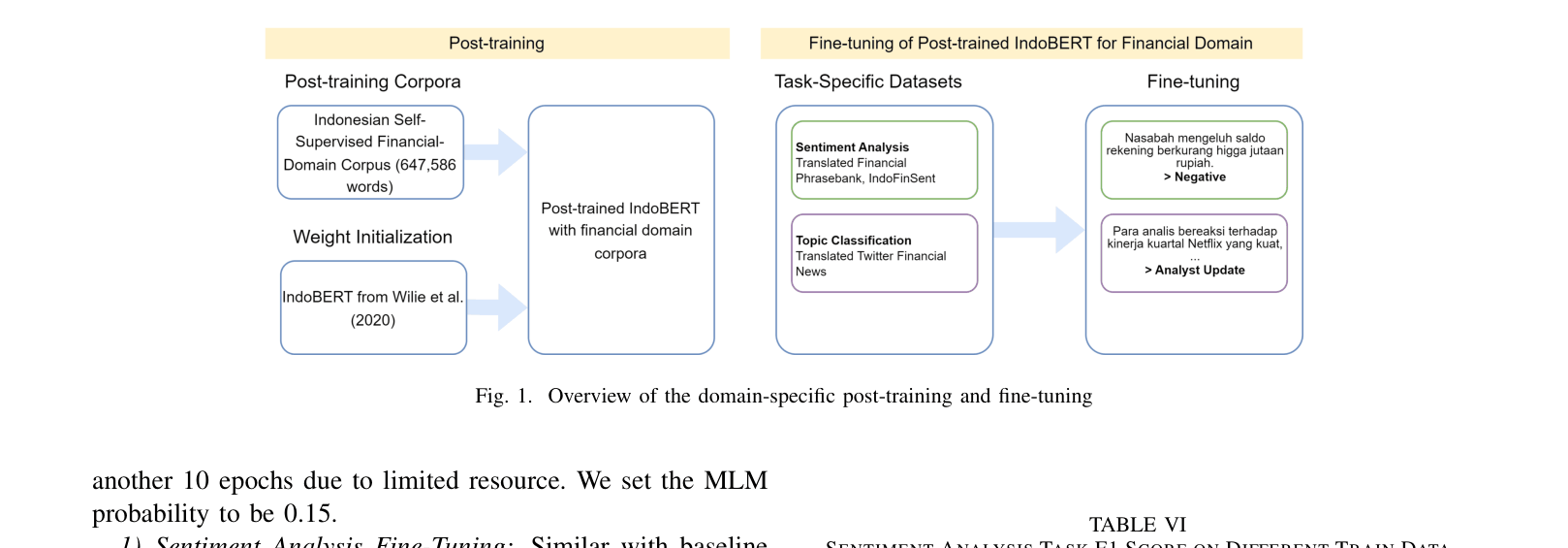
Overview of the domain-specific post-training and fine-tuning workflow.
Evaluation Highlights
- Post-trained Base model achieves 0.81 F1 (+26% improvement over baseline) on sentiment analysis when fine-tuned on only 30% of training data.
- Achieves 0.94 F1 on sentiment analysis with full training data, outperforming the generic IndoBERT baseline (0.91 F1).
- Demonstrates that domain-specific post-training is particularly effective for smaller model architectures (Base) compared to Larger ones.
Breakthrough Assessment
7/10
Significant contribution to low-resource financial NLP by releasing datasets and models. While the methodology (post-training BERT) is standard, the resource creation for Indonesian is novel and valuable.