📝 Paper Summary
Domain Adaptation
Financial Large Language Models
Post-training Strategies
FinDaP adapts LLMs to finance by jointly optimizing pre-training and instruction tuning to minimize forgetting, then refining reasoning via preference alignment using stepwise corrective signals.
Core Problem
Existing domain adaptation methods typically perform training stages (CPT, IT, PA) sequentially without optimizing for trade-offs, leading to catastrophic forgetting of general capabilities or poor reasoning on complex domain tasks.
Why it matters:
- Sequential training (CPT then IT) often causes the model to lose general instruction-following abilities gained during the base model's original training
- Current financial LLMs focus on simple tasks (sentiment analysis) but struggle with complex reasoning (e.g., CFA exams) due to sparse outcome-based supervision
- Exclusive reliance on in-domain data exacerbates the loss of general knowledge, creating 'idiot savant' models
Concrete Example:
A standard financial LLM trained sequentially might answer a financial concept question correctly but fail to follow a specific formatting instruction (e.g., 'answer in JSON'), whereas a general LLM follows the instruction but misses the domain nuance.
Key Novelty
FinDaP Framework (FinCap, FinRec, FinTrain, FinEval)
- **FinRec (Model):** Replaces sequential training with Joint CPT+IT (mixing raw text and masked instructions) to maintain general capabilities while learning domain concepts.
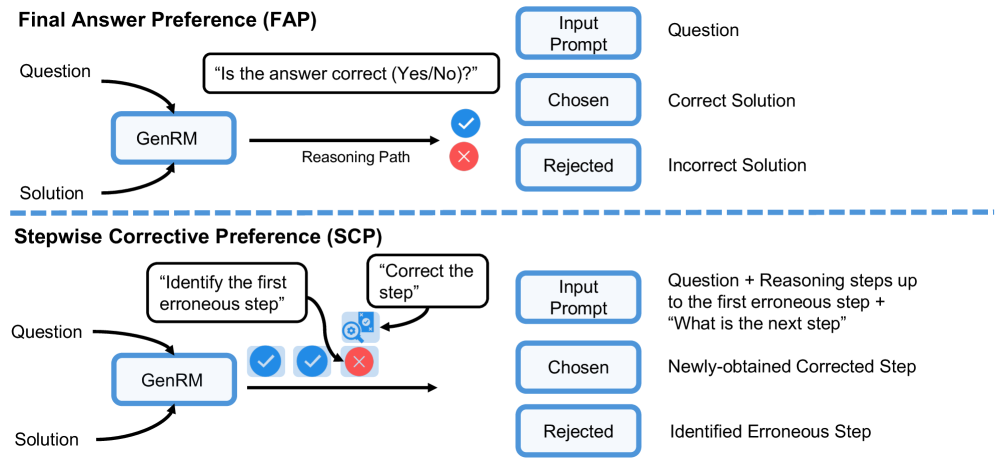
- **SCP (Stepwise Corrective Preference):** A novel preference alignment method where a Generative Reward Model identifies and corrects the *first* error in a reasoning chain, creating fine-grained (Error, Correction) training pairs.
- **Data Mixing:** Explicitly mixes general-domain and in-domain data across all stages to mitigate catastrophic forgetting.
Architecture
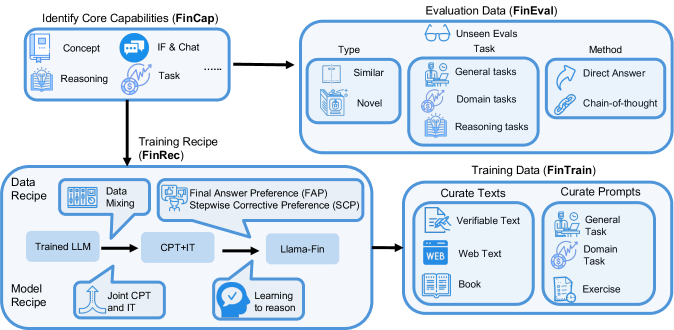
The FinDaP framework showing the four key components: FinCap (Capabilities), FinRec (Training Recipe), FinTrain (Data), and FinEval (Evaluation).
Evaluation Highlights
- 0.003% 10-gram contamination rate between FinTrain (training data) and FinEval (evaluation suite), ensuring rigorous testing on unseen data
Breakthrough Assessment
8/10
Offers a comprehensive, principled recipe for domain adaptation that addresses the critical 'forgetting vs. specializing' trade-off. The SCP method for reasoning alignment is a significant methodological contribution.