📝 Paper Summary
LLM Post-training analysis
Mechanistic Interpretability
Parameter Space Analysis
Post-training adapts LLMs not by reorganizing their internal geometry, but by applying uniform scaling to singular values and consistent orthogonal rotations to singular vectors, preserving the pre-trained semantic space.
Core Problem
While post-training (instruction tuning, reasoning distillation) is essential for LLM performance, its impact on the internal parameter structure remains a black box, with prior work focusing mostly on behavioral outputs or hidden states rather than weight matrices.
Why it matters:
- Current understanding of how models acquire new capabilities (like reasoning) is limited to observing outputs, lacking a structural explanation of how parameters evolve
- Treating weight matrices as black boxes hinders the development of more efficient fine-tuning or model merging techniques
- The lack of structural insight makes it difficult to distinguish between different types of post-training (e.g., standard instruction tuning vs. reasoning distillation) at the parameter level
Concrete Example:
When a base model is instruction-tuned, we know it follows commands better, but we don't know if this requires a complete rewiring of its internal connections. This paper shows it doesn't: the singular vectors of the fine-tuned model are just rotated versions of the base model's, meaning the fundamental semantic relationships are preserved rather than destroyed.
Key Novelty
Spectral Analysis of Post-Training Structural Invariants
- Discovers that post-training applies a near-uniform geometric scaling factor to all singular values within a layer, rather than altering the distribution shape
- Identifies that the output projection matrix (Wo) in attention layers exhibits anomalously high scaling factors specifically in reasoning models, distinguishing them from standard instruction-tuned models
- Proves that left and right singular vectors undergo coordinated orthogonal transformations (rotations), effectively preserving the semantic topology established during pre-training
Architecture
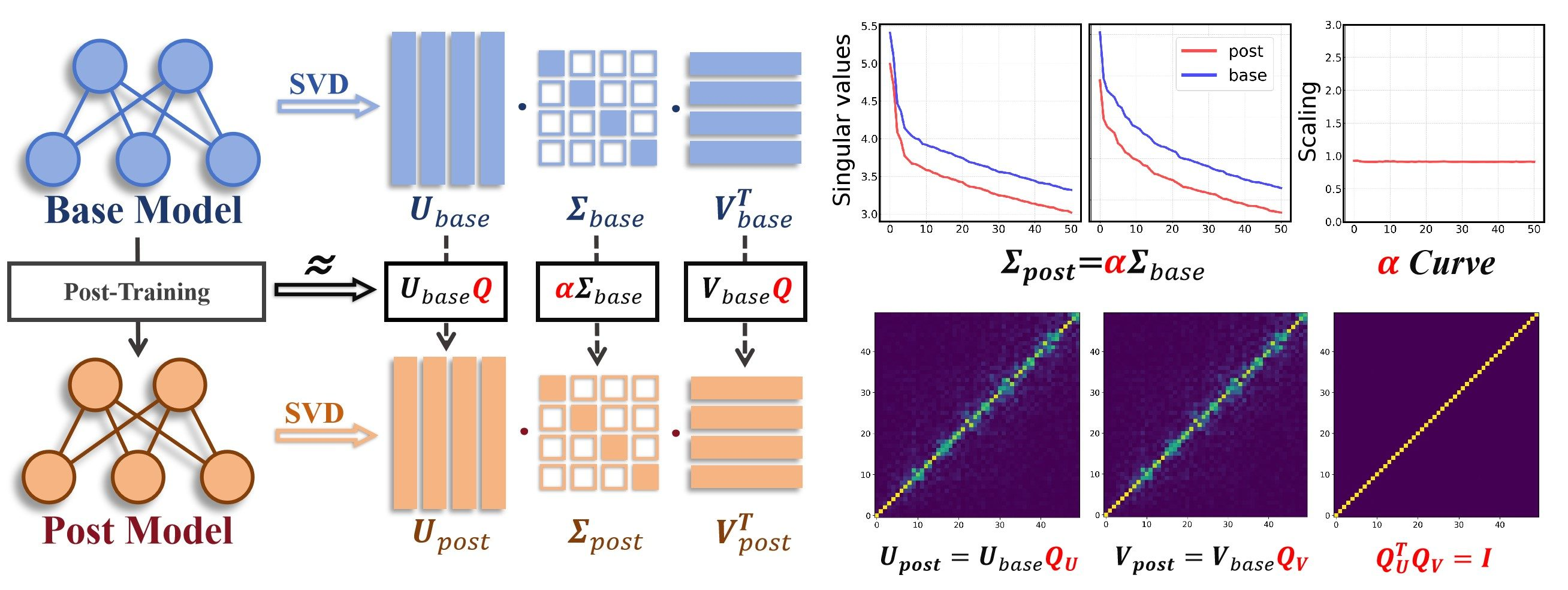
A conceptual framework illustrating the 'Coordinated Parametric Dynamics' discovered. It visualizes how a weight matrix W evolves from Base to Post via two operations: (1) Uniform Scaling of the singular value diagonal matrix Sigma, and (2) Coordinated Rotation of the singular vector matrices U and V.
Evaluation Highlights
- Demonstrates robust structural regularities across two distinct post-training regimes: Instruction Tuning (Qwen2.5-Instruct) and Long-CoT Distillation (DeepSeek-R1-Distill)
- Identifies a unique spectral signature for reasoning models: the Wo matrix in Self-Attention shows distinctively higher singular value scaling compared to instruction-tuned models
- Shows that the normalized Frobenius norm of the orthogonality gap between vector transformations is consistently low, proving the transformations are essentially rigid rotations
Breakthrough Assessment
7/10
Provides the first concrete mathematical laws (uniform scaling + coordinated rotation) describing post-training parameter evolution. While primarily analytical, it offers a strong theoretical foundation for understanding alignment mechanics.

