📝 Paper Summary
Distributed Training Systems
LLM Post-Training Efficiency
ODC adapts the Parameter Server model into Fully Sharded Data Parallel training by replacing collective communication with point-to-point transfers, enabling asynchronous progress and better handling of imbalanced LLM workloads.
Core Problem
Standard collective communication (all-gather, reduce-scatter) in FSDP enforces fine-grained synchronization barriers at every layer, causing significant device idle time when training sequences have highly variable lengths.
Why it matters:
- LLM post-training datasets (SFT, RL) contain sequences of widely varying lengths, creating persistent computational imbalance
- Existing packing strategies cannot fully remove skew due to memory constraints and microbatch splitting
- Under imbalanced workloads, faster GPUs must wait for the slowest GPU at every layer, leading to up to 50% idle time in long-sequence training
Concrete Example:
In a minibatch split into microbatches, if Device A processes a short sequence and Device B processes a long sequence, Device A finishes its layer computation early but must wait for Device B to complete its layer before proceeding to the next layer's all-gather, stalling the entire cluster.
Key Novelty
On-Demand Communication (ODC)
- Replaces layer-level collective communication barriers with asynchronous point-to-point primitives (gather/scatter-accumulate), allowing devices to fetch parameters and push gradients independently
- Reframes FSDP as a decentralized Parameter Server where server and worker roles are colocated on each GPU, preserving memory efficiency while gaining tolerance for stragglers
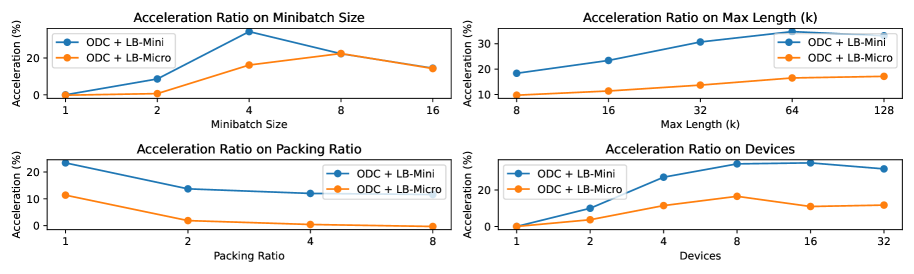
- Shifts load balancing from the microbatch level to the coarser minibatch level, simplifying packing and reducing waste
Architecture

Comparison between FSDP (Collective) and ODC (On-Demand) execution timelines.
Evaluation Highlights
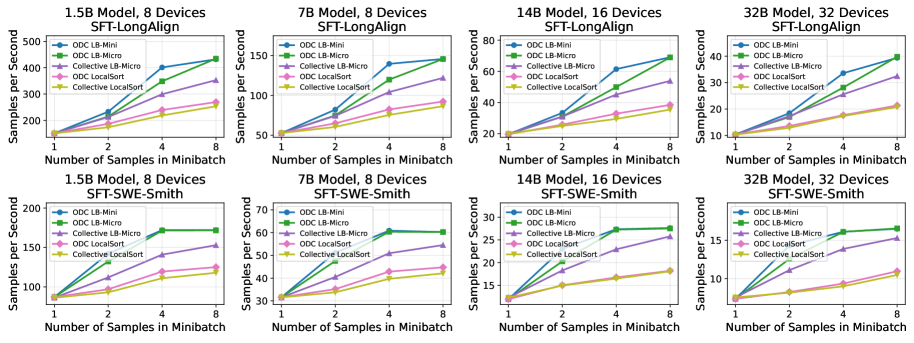
- Up to 36% speedup in training throughput over standard FSDP on Supervised Fine-Tuning (SFT) tasks with LongAlign and SWE-Smith datasets
- Up to 10% speedup on Reinforcement Learning (RL) tasks using GRPO on AIME prompts
- Reduces synchronization barriers from once per layer to once per minibatch, significantly lowering device idle time caused by workload imbalance
Breakthrough Assessment
7/10
Offers a strong systems-level optimization for a specific but critical problem (imbalanced LLM post-training). The shift back to PS-style communication within FSDP is a clever, practical insight yielding significant gains.