📊 Experiments & Results
Evaluation Setup
Curve fitting error evaluation on post-training loss trajectories
Benchmarks:
- SlimPajama (Loss) (Language Modeling)
Metrics:
- R^2 (Coefficient of determination)
- Huber Loss
- ASD (Average Slope Difference)
- Statistical methodology: Levenberg-Marquardt algorithm for non-linear least squares fitting
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Evaluation of different parameterization candidates for P2Law shows that L1 (the proposed form) provides the best fit across metrics. | ||||
| Llama-3 Depth Pruning | ASD | 4.67e-6 | 1.89e-6 | -2.78e-6 |
| Llama-3 Depth Pruning | R^2 | 0.8548 | 0.9922 | +0.1374 |
Experiment Figures
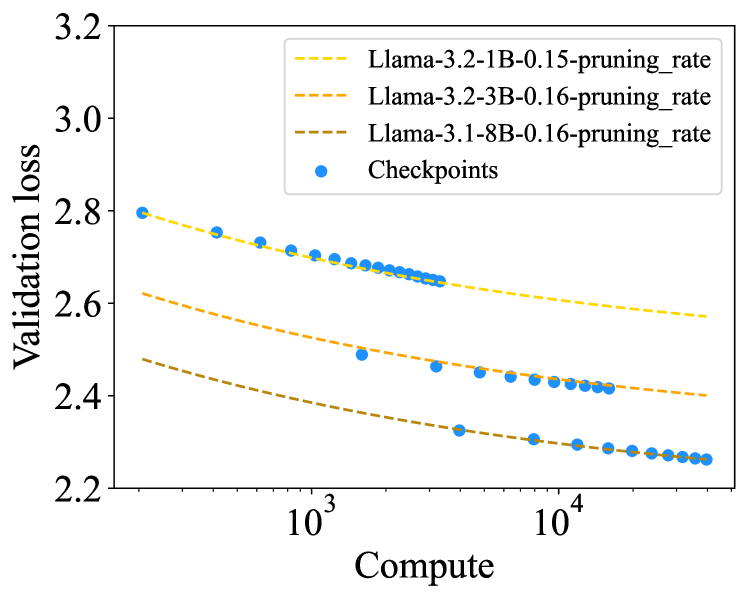
The fitted P2Law curves vs actual loss for Llama-3 models under depth pruning
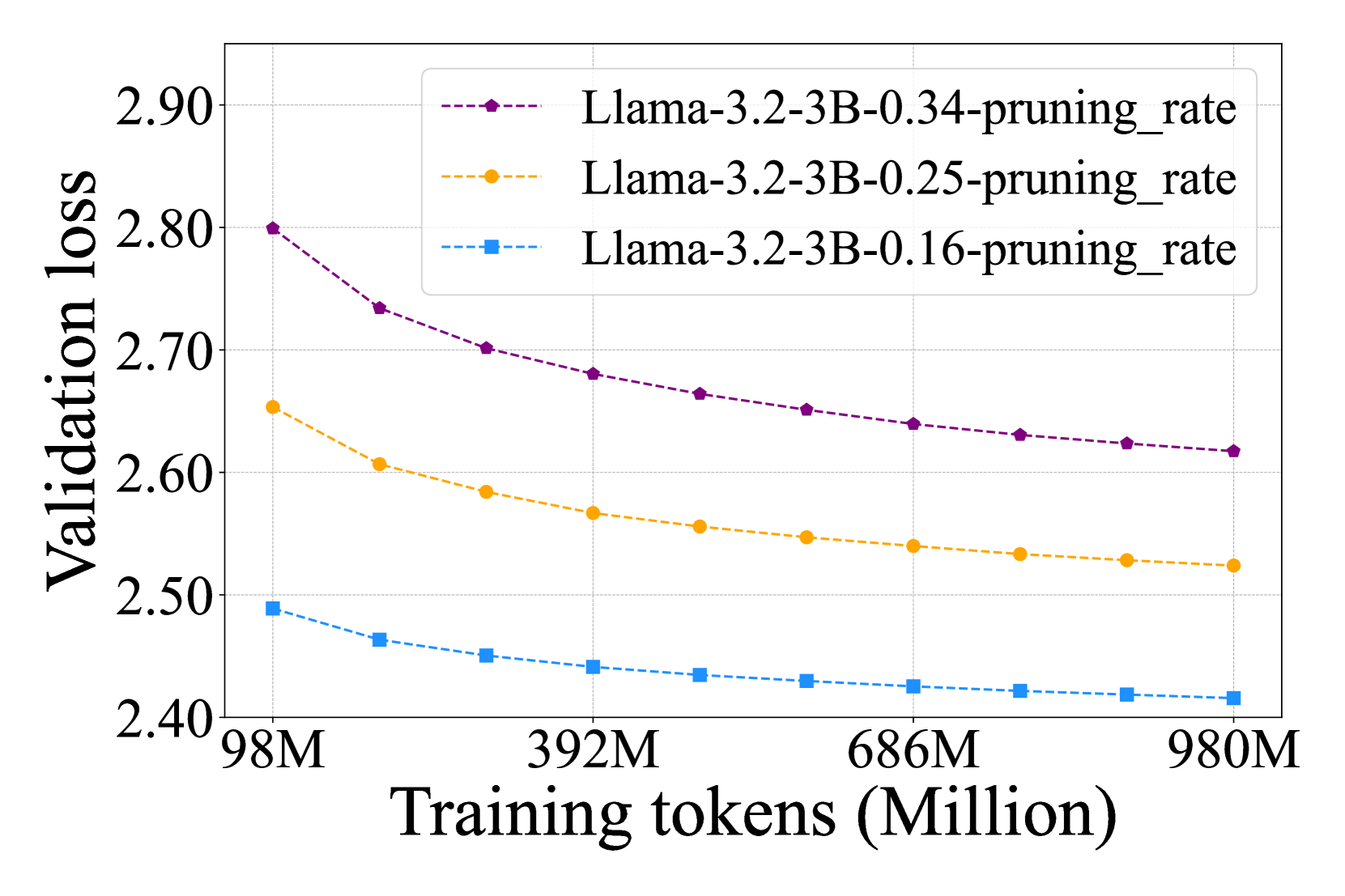
Normalized relative post-training loss curves for 2:4 semi-structured pruning
Main Takeaways
- Smaller LLMs exhibit faster convergence in post-training loss compared to larger LLMs given the same pruning rate
- Relative post-training loss follows a power-law relationship with the pruning rate
- The proposed P2Law (L1 parameterization) generalizes well to unseen model sizes (predicting 3B from <2B models) and larger datasets
- Width pruning on Llama-3.1-8B is an outlier where depth pruning is superior, contrary to trends in other models