📊 Experiments & Results
Evaluation Setup
Comparing performance gaps between clean and contaminated models on math and coding benchmarks across different training life-cycle stages
Benchmarks:
- GSM8K (Contaminated math reasoning benchmark)
- MBPP (Contaminated Python coding benchmark)
- GSMPlus (Uncontaminated math reasoning benchmark)
- HumanEval (Uncontaminated Python coding benchmark)
Metrics:
- Accuracy (Math)
- Pass@1 (Coding)
- Statistical methodology: Standard error propagation assuming independent estimates for the (Contaminated–Clean) difference, yielding 95% confidence intervals
Experiment Figures
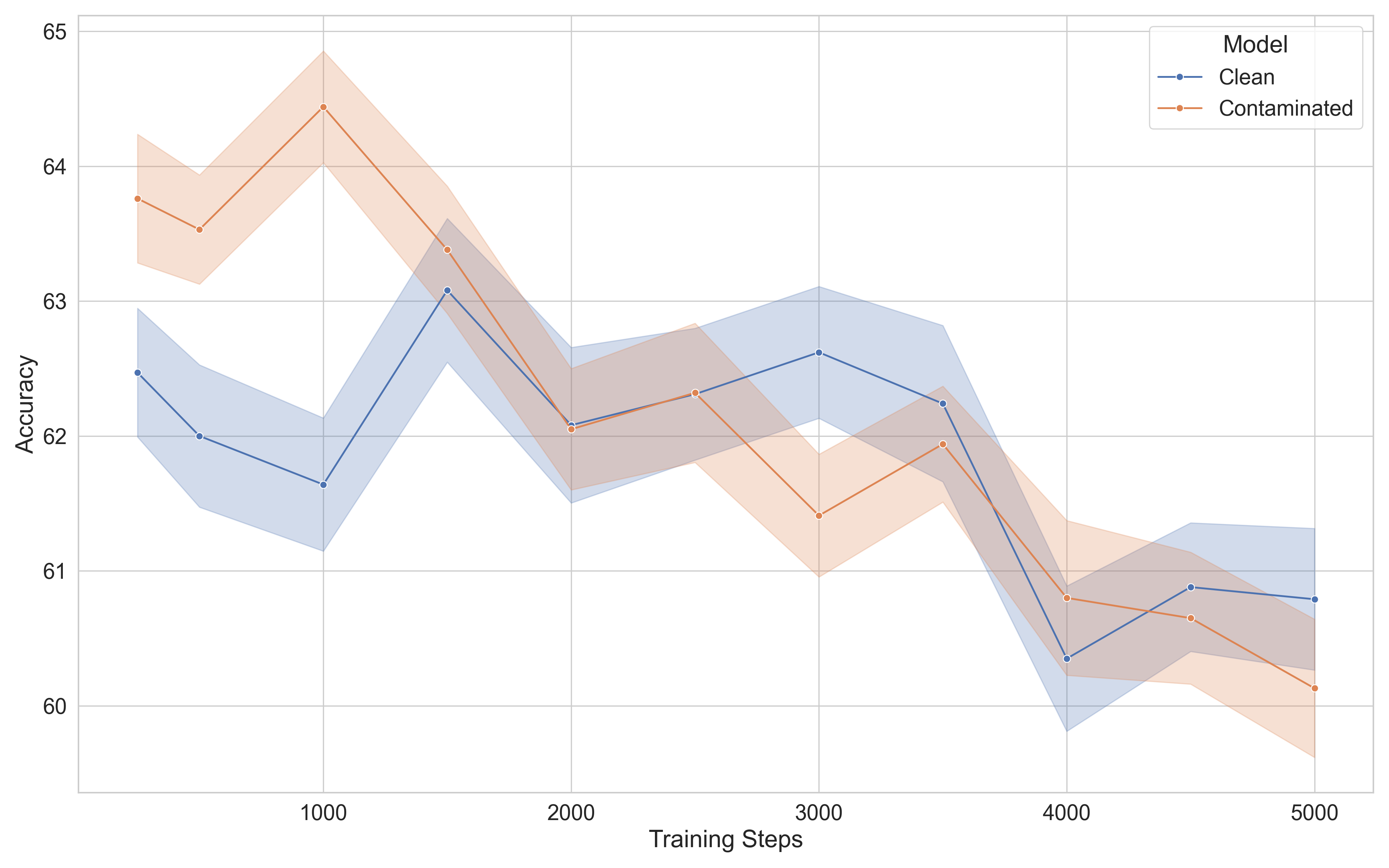
Contaminated vs. clean model performance on GSM8K during the pre-training process for Qwen2.5-1.5B
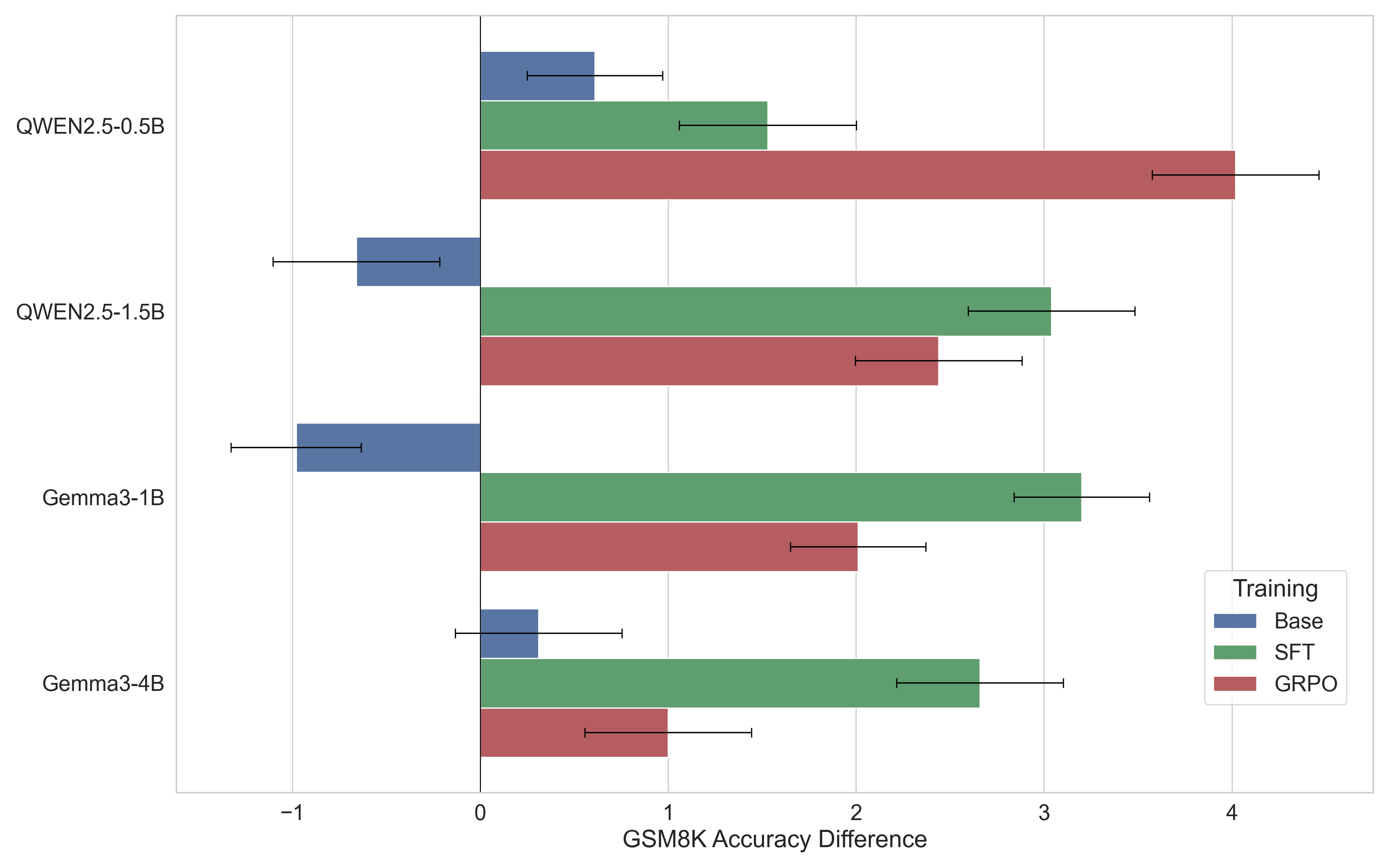
Performance movement mapped across contaminated vs. uncontaminated benchmarks comparing Base, SFT, and GRPO models
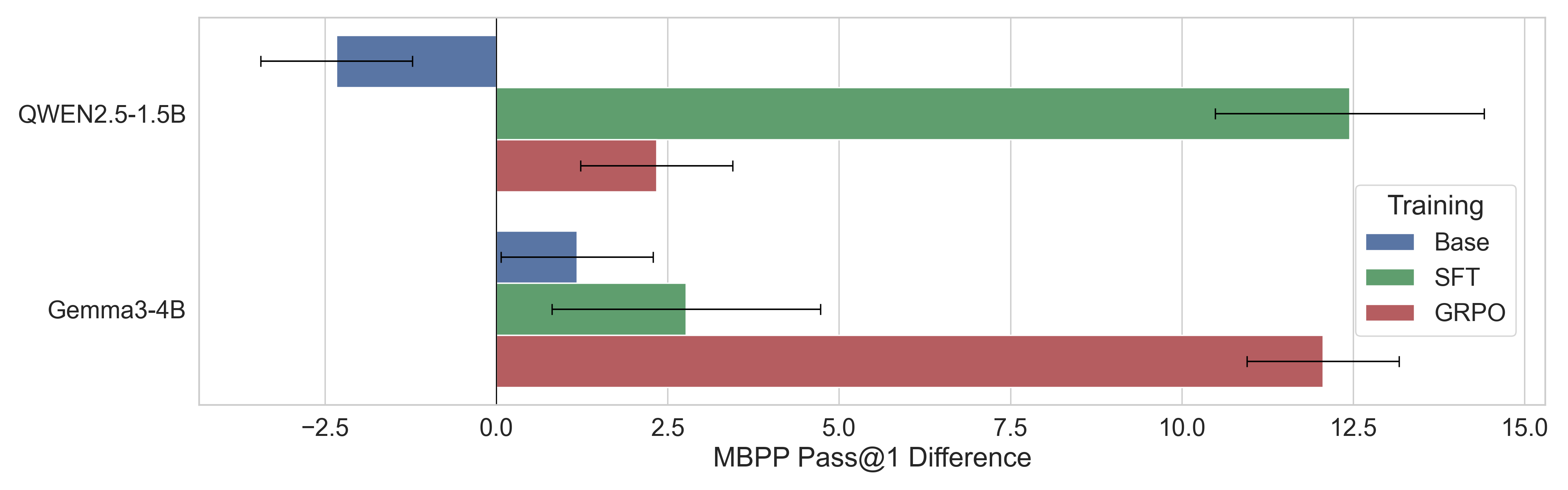
The impact of model scale on the contamination-gap difference across different training recipes (Base, SFT, GRPO)
Main Takeaways
- Continued pre-training on clean data successfully masks the advantage of a contaminated model, driving the apparent performance gap close to zero (confirming prior work).
- Post-training resurrects hidden contamination, yielding a performance gap of over 2% (up to 4%) in favor of the contaminated model.
- SFT (Supervised Fine-Tuning) uncovers pre-training contamination more strongly than GRPO (Group Relative Policy Optimization) for most models, but its gains are purely local to the contaminated benchmark, signifying pure over-estimation.
- GRPO improves performance on both contaminated and uncontaminated benchmarks, suggesting it successfully extracts generalizable reasoning patterns from the leaked data.
- As model scale increases, SFT models suffer from progressively larger over-estimation, while larger GRPO models convert leakage into broader generalization, thereby diluting the relative over-estimation.