📝 Paper Summary
Medical Foundation Models
ECG Analysis
Model Adaptation
A two-stage post-training strategy combining linear probing initialization and stochastic depth regularization significantly improves ECG foundation models, enabling them to outperform specialized architectures on diagnostic benchmarks.
Core Problem
Despite large-scale pre-training, ECG foundation models often underperform compared to smaller, task-specific architectures when fine-tuned on downstream clinical tasks.
Why it matters:
- Current fine-tuned foundation models lag behind specialized models (e.g., multi-scale CNNs) on benchmarks like PTB-XL, limiting clinical adoption
- Naive fine-tuning fails to address the inherent information redundancy in ECG signals, leading to suboptimal generalization
- Standard random initialization of classification heads during fine-tuning can destabilize the adaptation of pre-trained weights
Concrete Example:
When the foundation model HuBERT-ECG is fine-tuned on the PTB-XL dataset, it performs worse than specialized models like Chimera. Similarly, a standard fine-tuned Transformer-FM achieves only 0.893 AUROC on the all-label classification task, lagging behind task-specific baselines.
Key Novelty
Two-Stage Post-Training Strategy (Initialization + Regularization)
- Stage 1 (Initialization): Uses linear probing (freezing the backbone and training only the head) to align the final layer with pre-trained representations before full fine-tuning
- Stage 2 (Regularization): Employs stochastic depth during full fine-tuning to randomly drop layers, reducing redundancy inherent in repetitive ECG heartbeats and preventing overfitting
Architecture
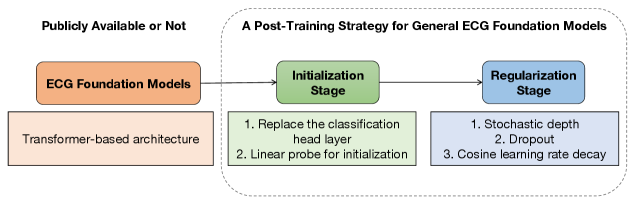
The two-stage post-training framework: Initialization Stage and Regularization Stage.
Evaluation Highlights
- +5.2% macro AUROC improvement on the PTB-XL all-label classification task compared to the standard fine-tuning baseline
- +34.9% macro AUPRC improvement on the same PTB-XL all-label task, significantly boosting precision-recall performance
- Outperforms state-of-the-art specialized architectures (e.g., MULTIRESNET, Chimera) on 3 out of 4 PTB-XL tasks
Breakthrough Assessment
7/10
Simple but highly effective strategy that fixes a known weakness of ECG foundation models. While not a new architecture, it establishes a strong post-training recipe that closes the gap with specialized models.