📝 Paper Summary
Remote Sensing
Vision-Language Models (VLMs)
GRAFT trains open-vocabulary remote sensing models without text annotations by using geotagged ground-level internet images to bridge satellite imagery with CLIP's pre-trained text-image space.
Core Problem
Training open-vocabulary vision-language models for satellite imagery is difficult because massive paired text-image datasets (like those for internet images) do not exist for remote sensing.
Why it matters:
- Existing remote sensing models are specialized for pre-defined concepts, limiting flexibility for analysts who need to query novel objects (e.g., 'farmlands in Massachusetts') without retraining.
- Manual annotation of satellite imagery is expensive and requires expertise, resulting in datasets four orders of magnitude smaller than internet-scale data (10k vs 400 million pairs).
- Current methods relying on small captioned datasets or direct CLIP fine-tuning fail to generalize effectively to the diverse, unannotated nature of global satellite data.
Concrete Example:
An analyst wants to find 'baseball fields' in a city. A traditional supervised model trained only on 'buildings' and 'roads' cannot do this. A standard CLIP model fails because satellite viewpoints look nothing like ground photos. GRAFT solves this by learning that the satellite view of a field corresponds to ground photos of baseball games, which CLIP already understands.
Key Novelty
Ground images as a semantic bridge (GRAFT)
- Uses geotagged internet images (ground view) as an intermediary to connect satellite images (overhead view) to language, avoiding the need for direct satellite-text pairs.
- Aligns a satellite image encoder to the CLIP image space by pulling satellite embeddings closer to the embeddings of ground images taken at the same location.
- Extends alignment to the pixel level by mapping specific ground image locations to corresponding patches in the satellite view, enabling localization and segmentation.
Architecture
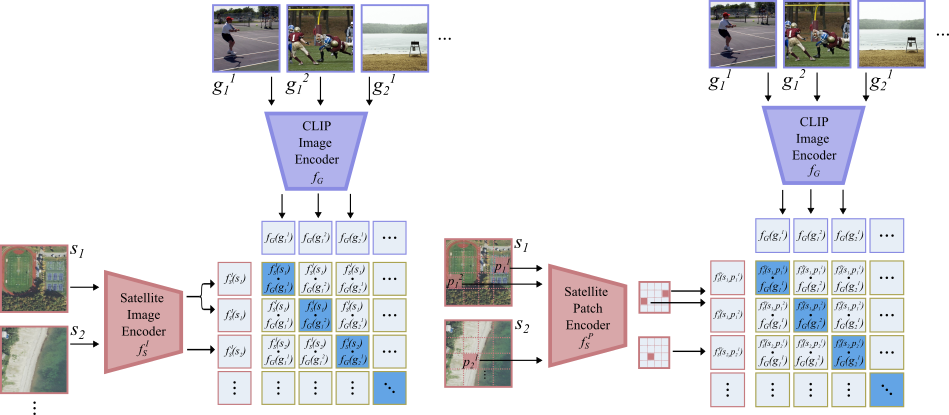
The training pipeline for GRAFT showing how satellite images are aligned with ground images.
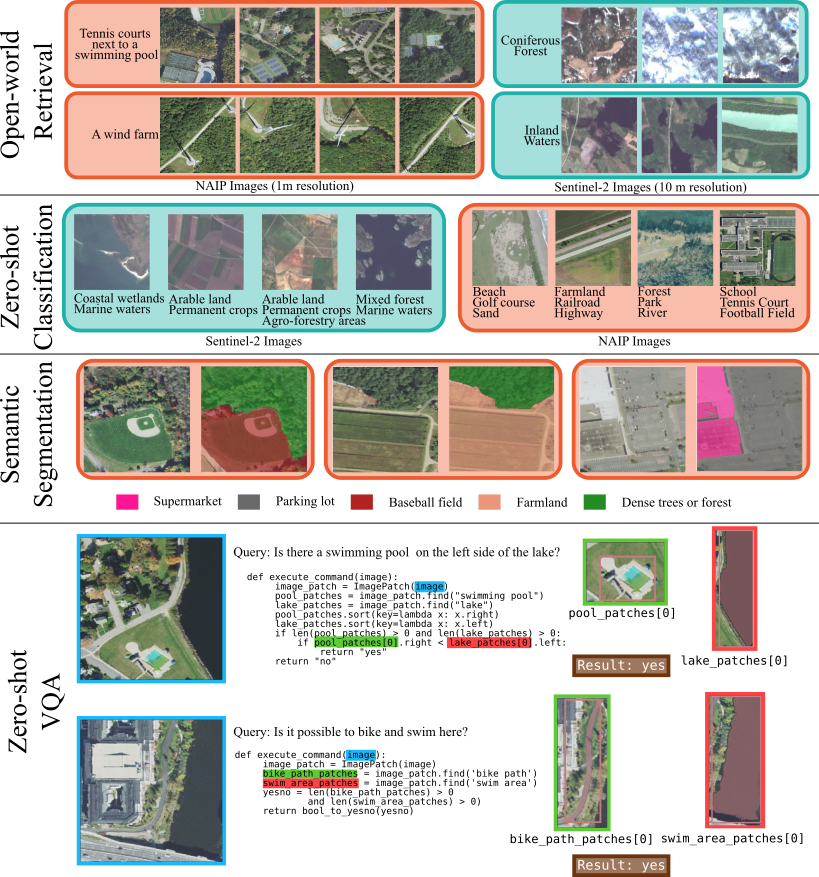
Evaluation Highlights
- Outperforms supervised VLMs by up to 20% on zero-shot image classification tasks.
- Achieves >80% relative improvement over baselines on text-to-segmentation benchmarks.
- Demonstrates state-of-the-art zero-shot performance on various text-to-image retrieval benchmarks for satellite imagery.
Breakthrough Assessment
8/10
Significantly shifts the paradigm for remote sensing by removing the bottleneck of textual annotations. The massive performance gains (+80% segmentation) and scalable data collection method suggest high impact.