📝 Paper Summary
Remote Sensing Vision-Language Models
Multimodal Large Language Models (MLLMs)
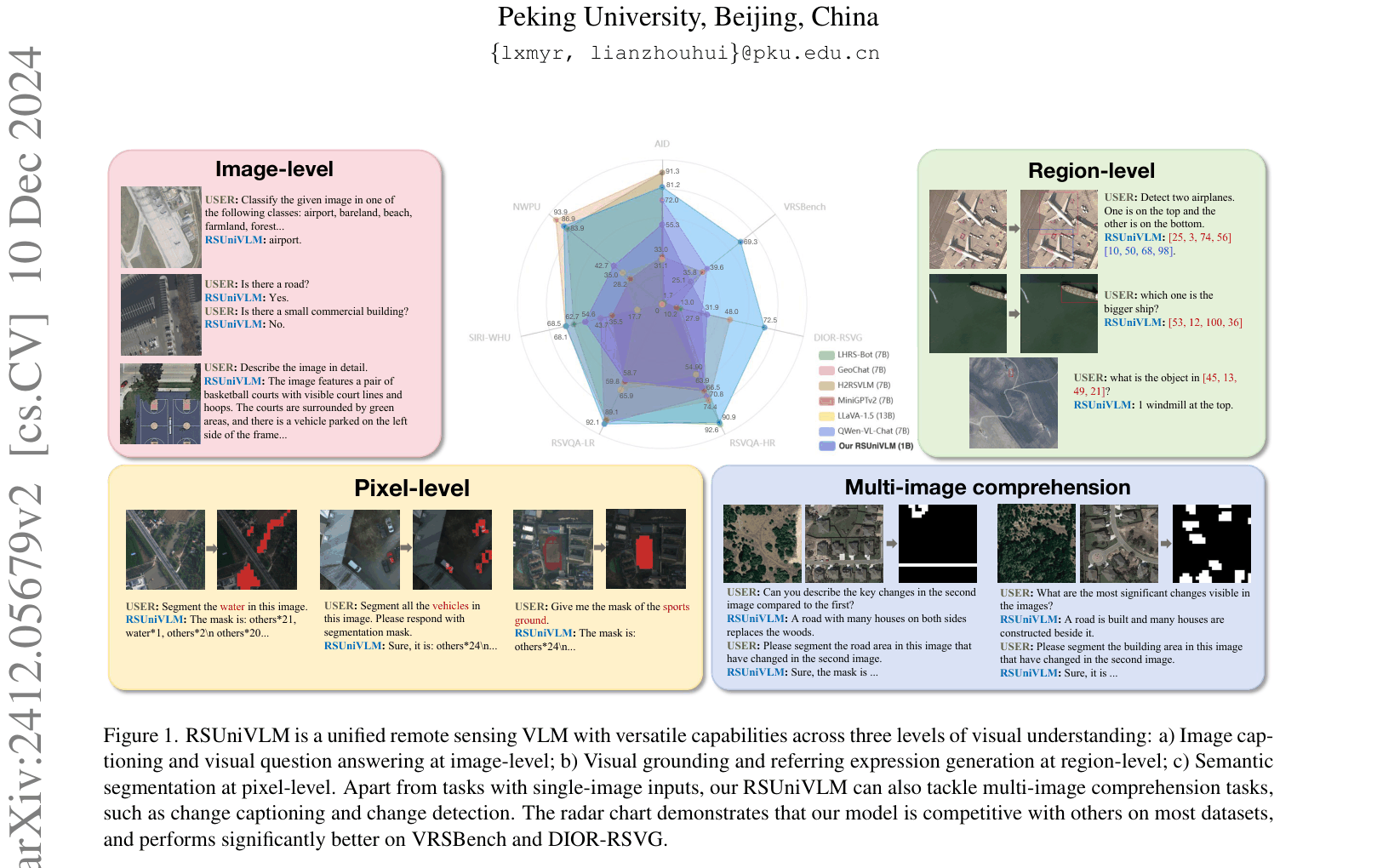
RSUniVLM is a 1B-parameter remote sensing model that unifies image-level, region-level, and pixel-level tasks into a single text-generation framework using a granularity-oriented mixture of experts.
Core Problem
Existing remote sensing VLMs lack pixel-level understanding (segmentation) and struggle with multi-image inputs (change detection), limiting them to coarse image or region-level tasks.
Why it matters:
- Fine-grained understanding is critical for practical applications like land-cover mapping and environmental monitoring where precise boundaries matter.
- Current models require separate specialized architectures for segmentation vs. captioning, preventing unified reasoning across different granularities.
- Change detection requires reasoning across multiple images, which most single-image VLMs cannot handle effectively.
Concrete Example:
A user asks to 'Segment the road area in this image that have changed in the second image.' Existing models like GeoChat can only provide bounding boxes or text descriptions, failing to generate the precise pixel-level mask required for the task.
Key Novelty
Granularity-oriented Mixture of Experts (G-MoE)
- Decouples the LLM's reasoning into three specific experts: Image-level (global semantics), Region-level (localization), and Pixel-level (segmentation/fine details).
- Uses a training-free task router to dynamically assign inputs to the correct expert based on the task type, preventing interference between different visual granularities.
- Unifies all outputs, including segmentation masks, into a text-only format using semantic descriptors, enabling end-to-end training without task-specific heads.
Architecture
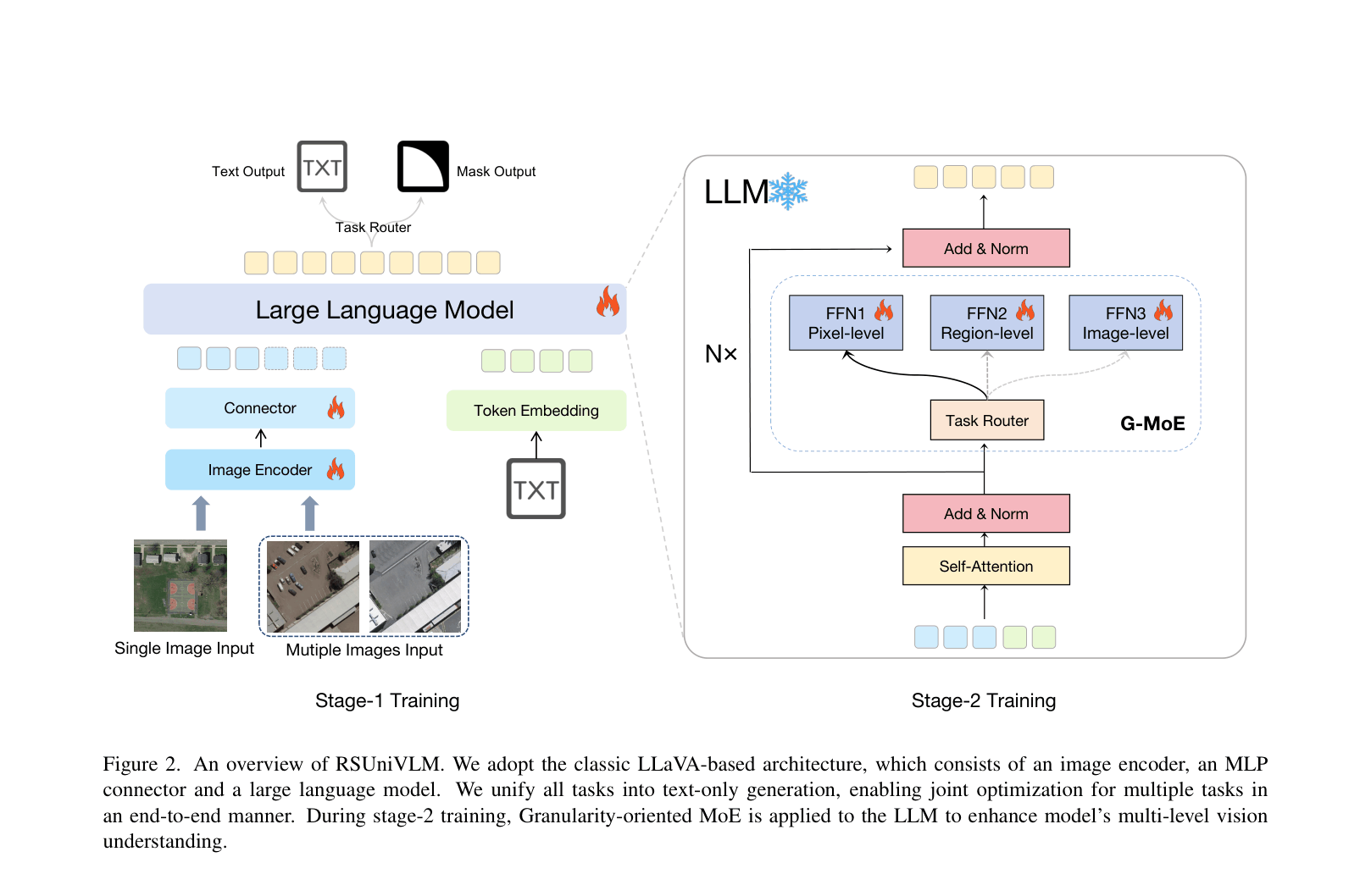
Overview of RSUniVLM architecture and the Granularity-oriented Mixture of Experts (G-MoE).
Evaluation Highlights
- +29.7% accuracy improvement on VRSBench-Ref visual grounding compared to GeoChat (69.31% vs 39.6%).
- Achieves 86.86% accuracy on SIRI-WHU scene classification, outperforming LHRS-Bot-7B (83.94%) and GeoChat-7B (43.67%).
- Competitive zero-shot change detection on WHU-CD (F1 71.38%) compared to supervised methods trained on 5% labeled data.
Breakthrough Assessment
8/10
First RS-specialized VLM to unify pixel-level segmentation with high-level reasoning and multi-image change detection in a single model, significantly outperforming larger baselines.