📝 Paper Summary
Vision-Language Model Evaluation
Benchmarking Frameworks
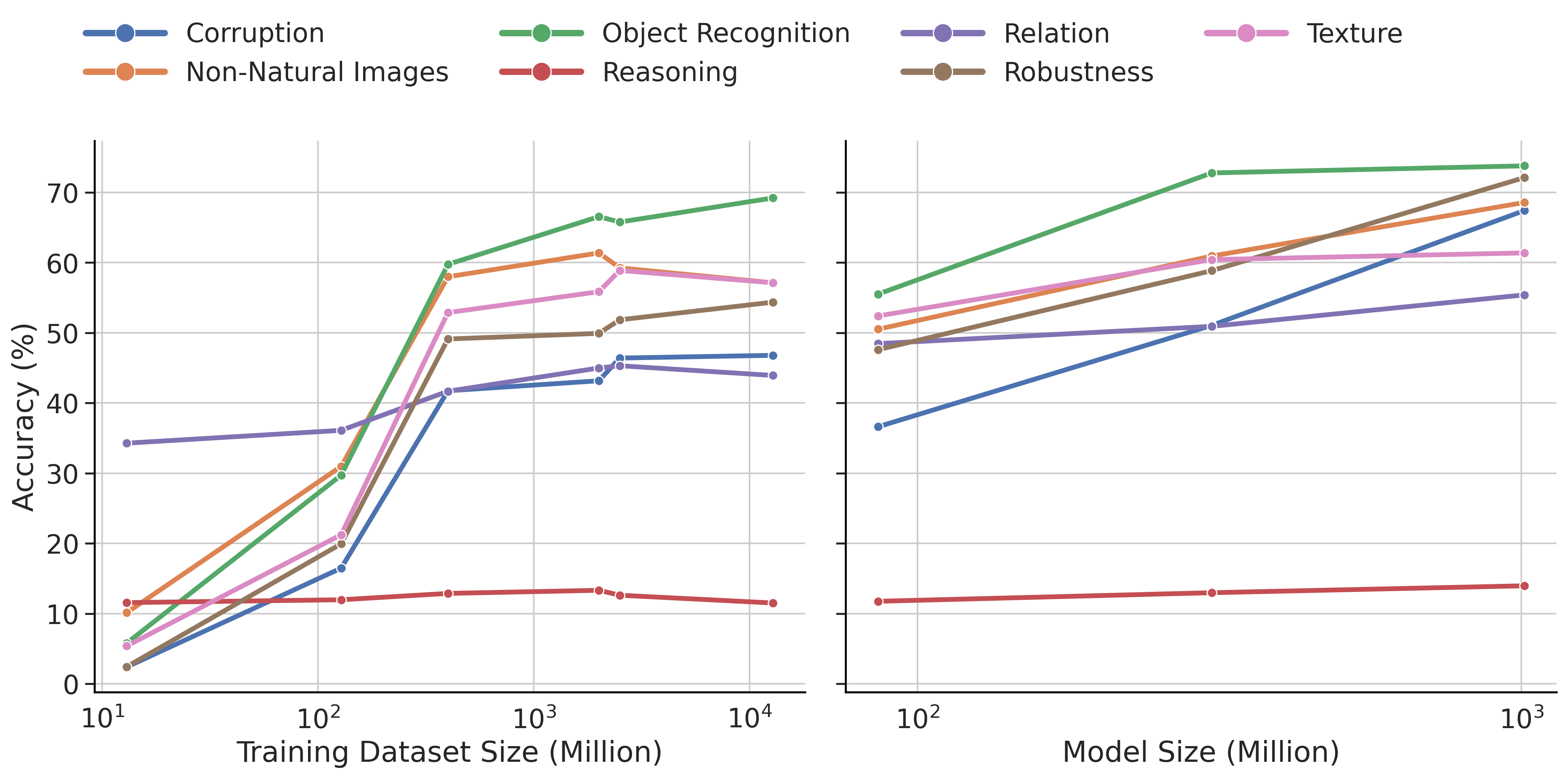
UniBench reveals that while scaling data and model size boosts object recognition, it offers little benefit for visual reasoning and relations, where tailored learning objectives and data quality matter more.
Core Problem
The fragmented landscape of VLM benchmarks forces researchers to implement dozens of protocols individually, often leading to partial evaluations that obscure blind spots in model capabilities, particularly in reasoning.
Why it matters:
- Selective evaluation hides model weaknesses; many new models are tested on only a subset of tasks, making cross-model comparison impossible
- The assumption that scaling solves all problems is untested across diverse capabilities; researchers need to know where scale fails to prioritize new methods
- Computational burden of running 50+ diverse benchmarks prevents systematic analysis of progress axes like counting, spatial awareness, and relations
Concrete Example:
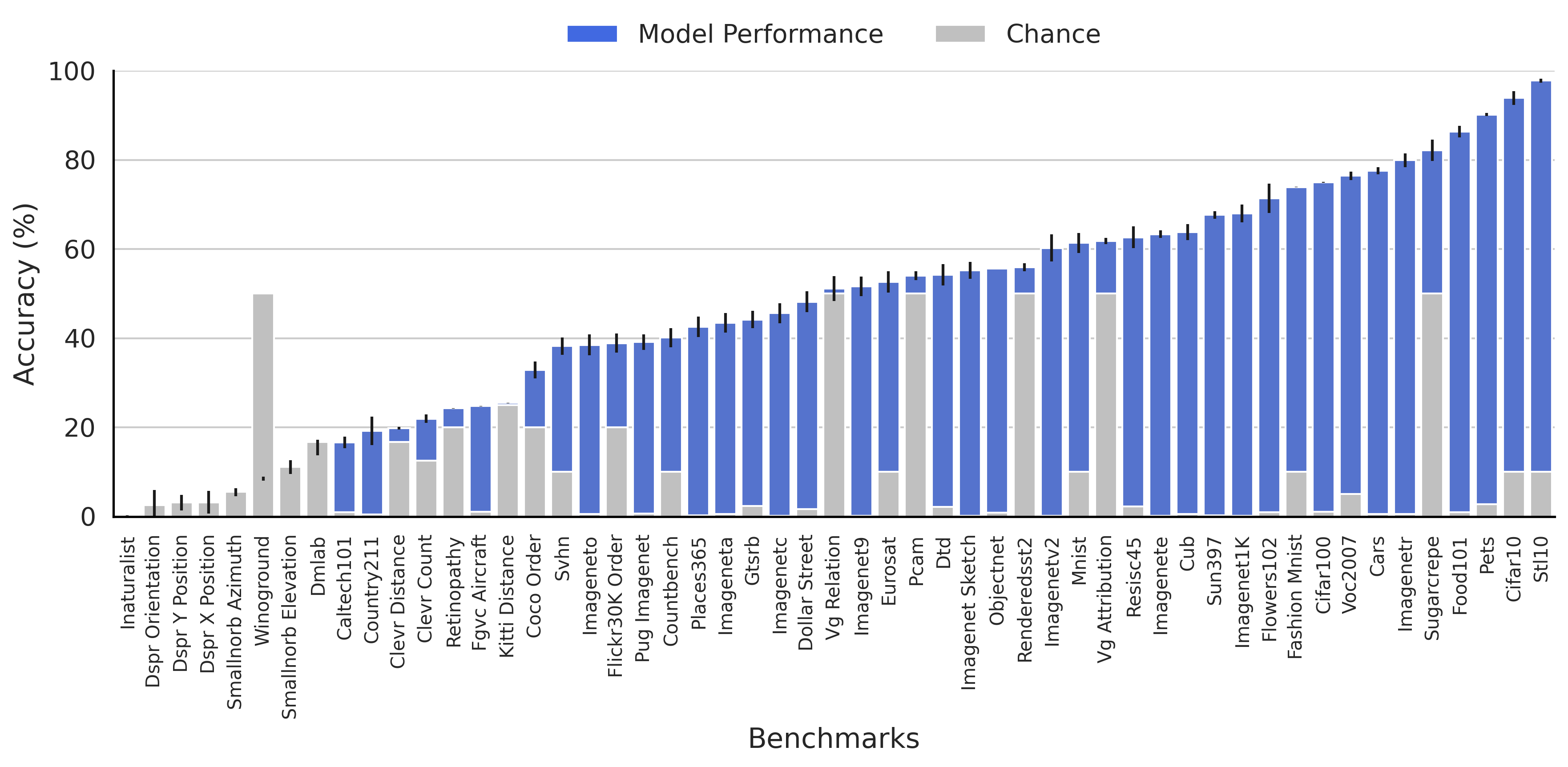
Despite training on billions of samples, state-of-the-art VLMs struggle on MNIST (simple digit recognition), a task solvable by a 2-layer MLP. A VLM might classify a '3' incorrectly even with detailed prompts, showing a fundamental gap in numerical comprehension that scale hasn't fixed.
Key Novelty
Unified Multi-Axis VLM Benchmark (UniBench)
- Consolidates 53 distinct vision-language benchmarks into a single unified codebase, categorizing them into seven high-level types (e.g., Reasoning, Relations, Object Recognition) to enable apples-to-apples comparison
- Provides a 'distilled' evaluation subset that runs in under 5 minutes on a single GPU, facilitating rapid prototyping and consistent reporting across the community
- Systematically evaluates 59 models to decouple the effects of scaling data/parameters from architecture and learning objectives, revealing that reasoning capabilities do not scale linearly like recognition does
Architecture
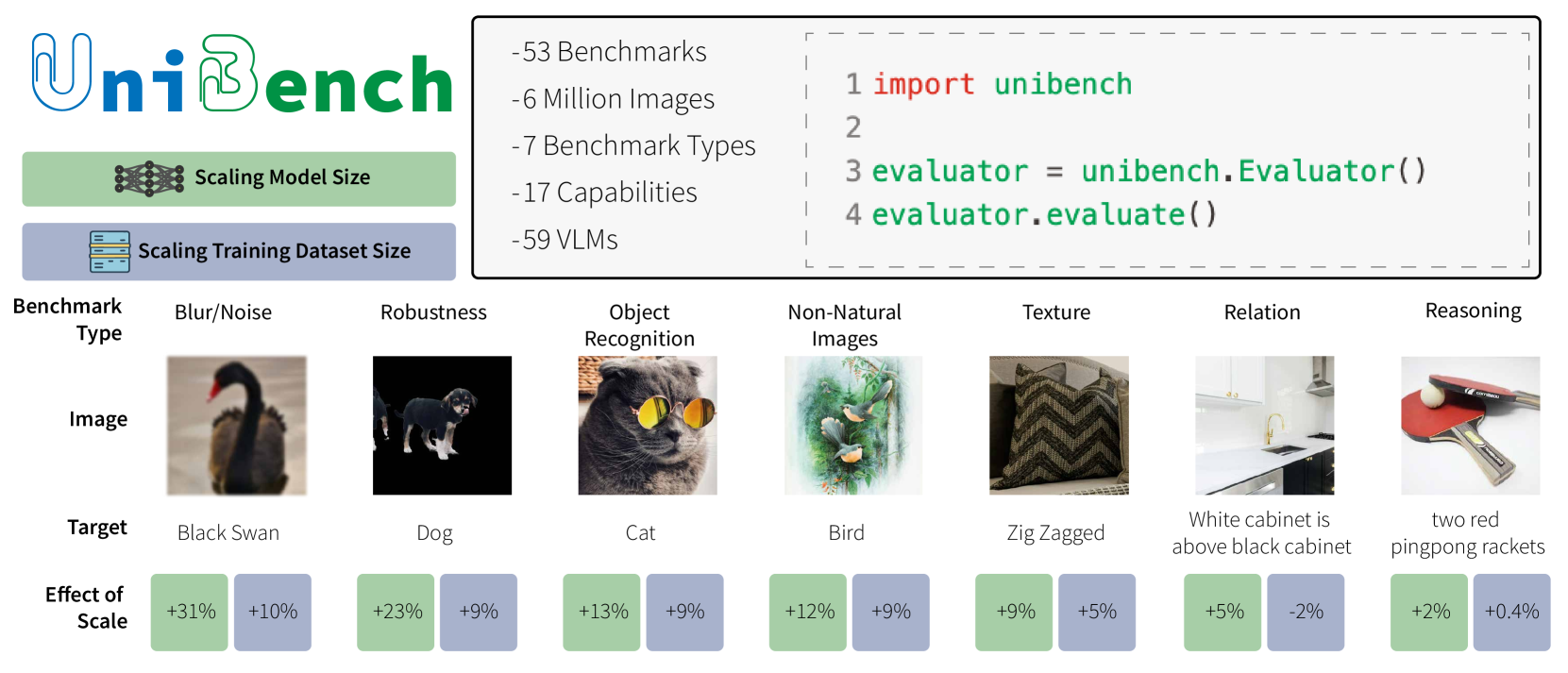
Taxonomy of UniBench benchmarks categorized into 7 types and 17 capabilities.
Evaluation Highlights
- Scaling training data by 1000x improves object recognition but yields flat performance curves for reasoning and relation tasks
- Specialized model NegCLIP (86M parameters) outperforms EVA ViT-E/14 (4.3B parameters) by ~20% on relation benchmarks, proving objective function > scale for specific skills
- Simple digit recognition remains unsolved: complex VLMs fail to reach the 99% accuracy on MNIST that basic networks achieved decades ago, even with top-5 relaxation
Breakthrough Assessment
8/10
Provides a critical reality check on VLM scaling laws and a highly practical unified tool. The finding that scale fails for reasoning is a significant signal to the field.