📝 Paper Summary
Remote Sensing Image Captioning (RSIC)
Visual Question Answering (VQA)
Mixture of Experts (MoE) in Vision-Language Models
RS-MoE adapts the Mixture of Experts framework to remote sensing by using an Instruction Router to direct sub-tasks (theme, object, relationship) to specialized lightweight Large Language Models.
Core Problem
Standard Vision-Language Models (VLMs) fine-tuned for remote sensing struggle to capture the complex, diverse geographic objects and their relationships found in large-scale aerial imagery.
Why it matters:
- Remote sensing images cover larger areas with more diverse objects than natural images, requiring specialized interpretation.
- Existing methods often produce simple, repetitive captions that lack detailed relationship understanding.
- Applying MoE to this domain is challenging due to sparsity-induced degradation when transferring from natural image pre-training.
Concrete Example:
Traditional models might caption an image simply as 'A residential area.' RS-MoE aims to produce detailed captions like 'A dense residential area with green rooftops, where roads intersect near a park,' by routing object recognition and relationship inference to different experts.
Key Novelty
RS-MoE (Remote Sensing Mixture of Experts)
- Replaces the standard feed-forward network in MoE with multiple lightweight Large Language Models (LLMs) acting as experts.
- Introduces an Instruction Router that dynamically generates tailored prompts for each expert based on the input image and global instructions.
- Decomposes the captioning task into three explicit sub-tasks: theme comprehension, object recognition, and relationship inference.
Architecture
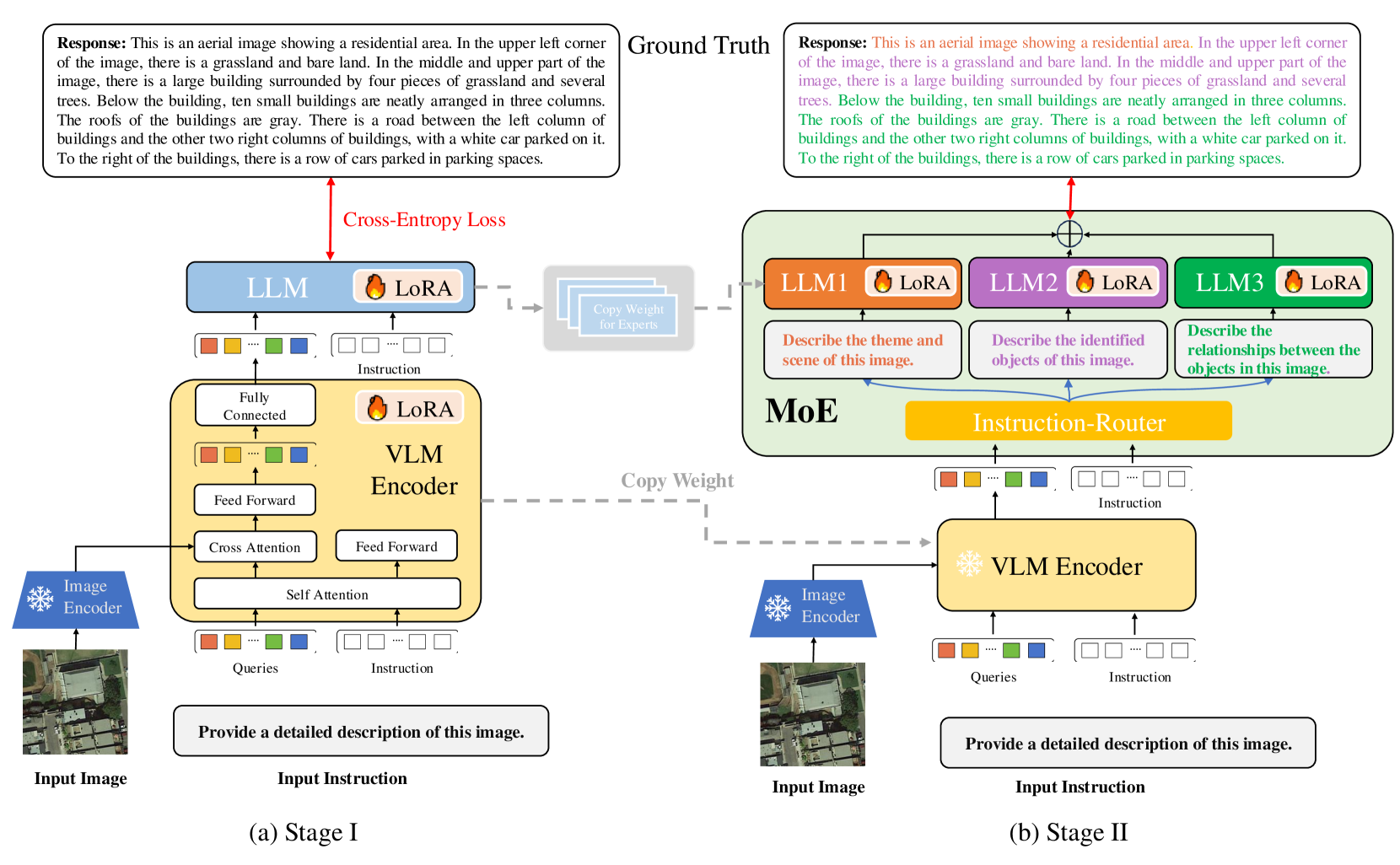
The overall architecture of RS-MoE, showing the flow from Image Encoder to VLM Encoder, and finally to the MoE Block with the Instruction Router and multiple LLM experts.
Evaluation Highlights
- RS-MoE-1B (lightweight variant) achieves performance comparable to 13B parameter VLMs on captioning tasks.
- Achieves state-of-the-art results on five remote sensing image captioning datasets (RSICap, UCM-Captions, Sydney-Captions, RSICD, NWPU-Captions).
- Demonstrates strong generalization on Remote Sensing Visual Question Answering (RSVQA) tasks without specific architectural changes.
Breakthrough Assessment
8/10
First application of MoE specifically for multimodal remote sensing. The use of LLMs as experts and the instruction router is a novel architectural shift for this domain, yielding efficiency and SOTA results.