📝 Paper Summary
3D Vision-Language Models
Zero-shot 3D Scene Understanding
Agentic AI
Agent3D-Zero enables standard 2D Vision-Language Models to understand 3D scenes zero-shot by treating them as agents that actively select informative viewpoints and use coordinate-grid visual prompts.
Core Problem
Current 3D understanding methods rely on fine-tuning Large Language Models with scarce, labor-intensive 3D-text paired data, limiting their scalability and generalization.
Why it matters:
- Collecting 3D data requires expensive specialized equipment (LiDAR, depth cameras) and reconstruction algorithms, making it hard to scale compared to 2D data
- Annotating 3D data with text is significantly more labor-intensive than 2D annotation
- Existing 3D datasets are limited in diversity (mostly CAD models or indoor scans), restricting model generalization in open-world scenarios
Concrete Example:
When a VLM tries to navigate or answer questions about a 3D room using only a raw Bird's-Eye View (BEV) image, it struggles to estimate distances or propose meaningful camera angles because it lacks inherent 3D spatial awareness.
Key Novelty
Active Multi-View Perception with Visual Prompting
- Reconceptualizes 3D understanding as an agentic process where a VLM iteratively selects 2D viewpoints to observe, simulating human exploration rather than processing raw 3D data directly
- Introduces Set-of-Line Prompting (SoLP): superimposing a Cartesian grid and ticks on Bird's-Eye View images to give the VLM a reference system for precise location and orientation planning
Architecture
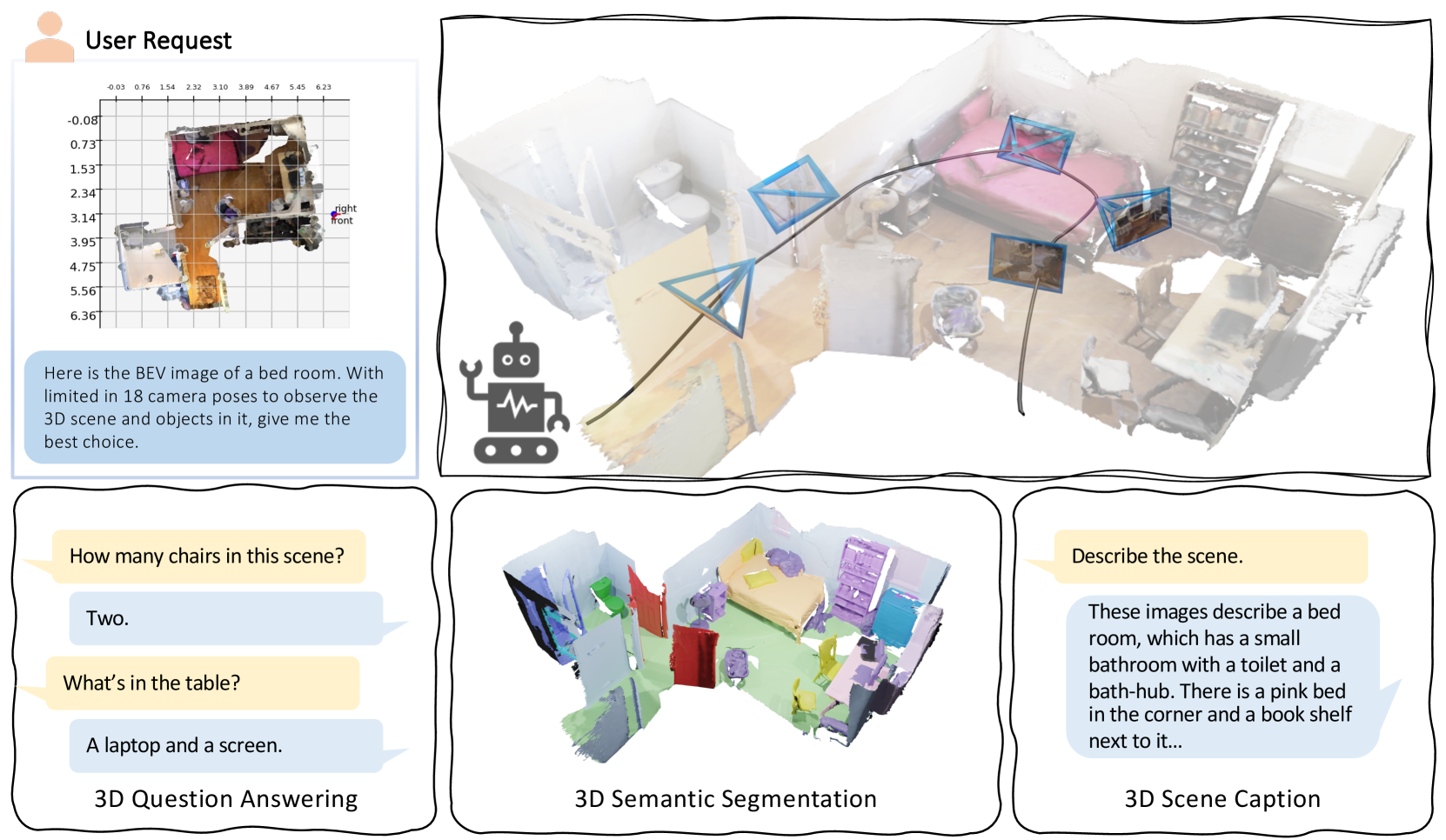
The complete workflow of Agent3D-Zero, illustrating the cycle of Bird's-Eye View processing, visual prompting, viewpoint selection, and final reasoning.
Evaluation Highlights
- Surpasses fully supervised methods on ScanQA (validation set) with 71.8 CIDEr (vs 69.4 for ScanQA baseline) without using any 3D-text training data
- Outperforms 3D-LLM (a fine-tuned method) on 3D-assisted dialog tasks, achieving 50.7 ROUGE-L vs 46.2
- Demonstrates zero-shot 3D semantic segmentation capability by projecting 2D segmentations (via SAM) into 3D space
Breakthrough Assessment
8/10
Strong breakthrough in enabling zero-shot 3D understanding without 3D training data. It outperforms supervised baselines on specific metrics, proving that intelligent viewpoint selection can replace explicit 3D training.