📝 Paper Summary
3D Vision-Language Pretraining
Point Cloud Understanding
CLIP2 achieves open-world 3D recognition by creating large-scale proxy datasets from unlabeled real-world scenes and aligning point cloud features directly with pretrained text and image spaces.
Core Problem
Adapting 2D Vision-Language Models to 3D is difficult due to scarce text-3D data pairs, forcing methods to use 2D projections that lose geometric information.
Why it matters:
- Safety-critical applications like autonomous driving require recognizing long-tail objects beyond predefined categories (e.g., debris, specialized vehicles)
- Existing 3D representations trained on closed vocabularies cannot generalize to open-world scenarios without massive labor-intensive annotation
- Current projection-based methods (e.g., converting points to depth maps) sacrifice 3D structural integrity for compatibility with 2D models
Concrete Example:
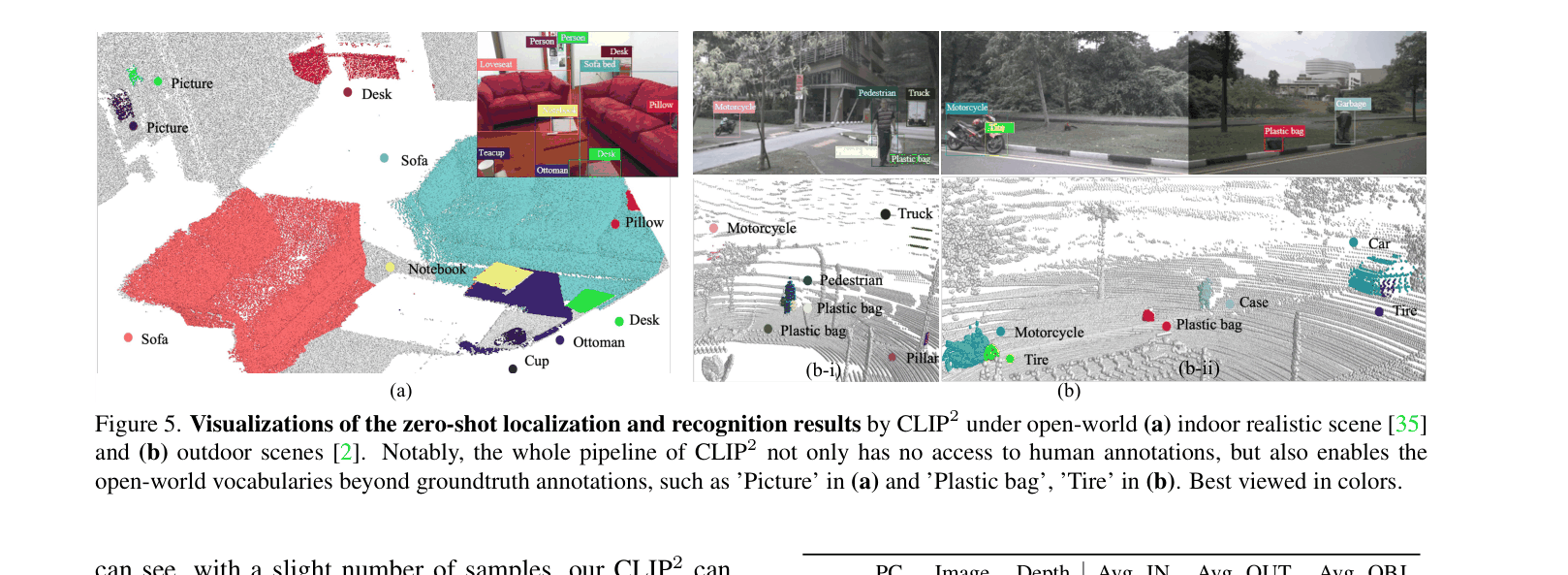
In an outdoor driving scene, a 'plastic bag' or 'tire' on the road might be missed by a standard detector trained on 'car/pedestrian', and projection-based methods might fail to distinguish its 3D geometry from a flat road patch.
Key Novelty
Triplet Proxy Collection & Cross-Modal Alignment
- Leverage a pretrained 2D detector and geometric transformations to automatically mine 'proxies' (triplets of text, image crop, and 3D point crop) from unlabeled real-world scans
- Train a 3D encoder to align with *both* the semantic space (text) and instance space (image) of a frozen 2D VLM, bridging the data gap without human labels
Architecture
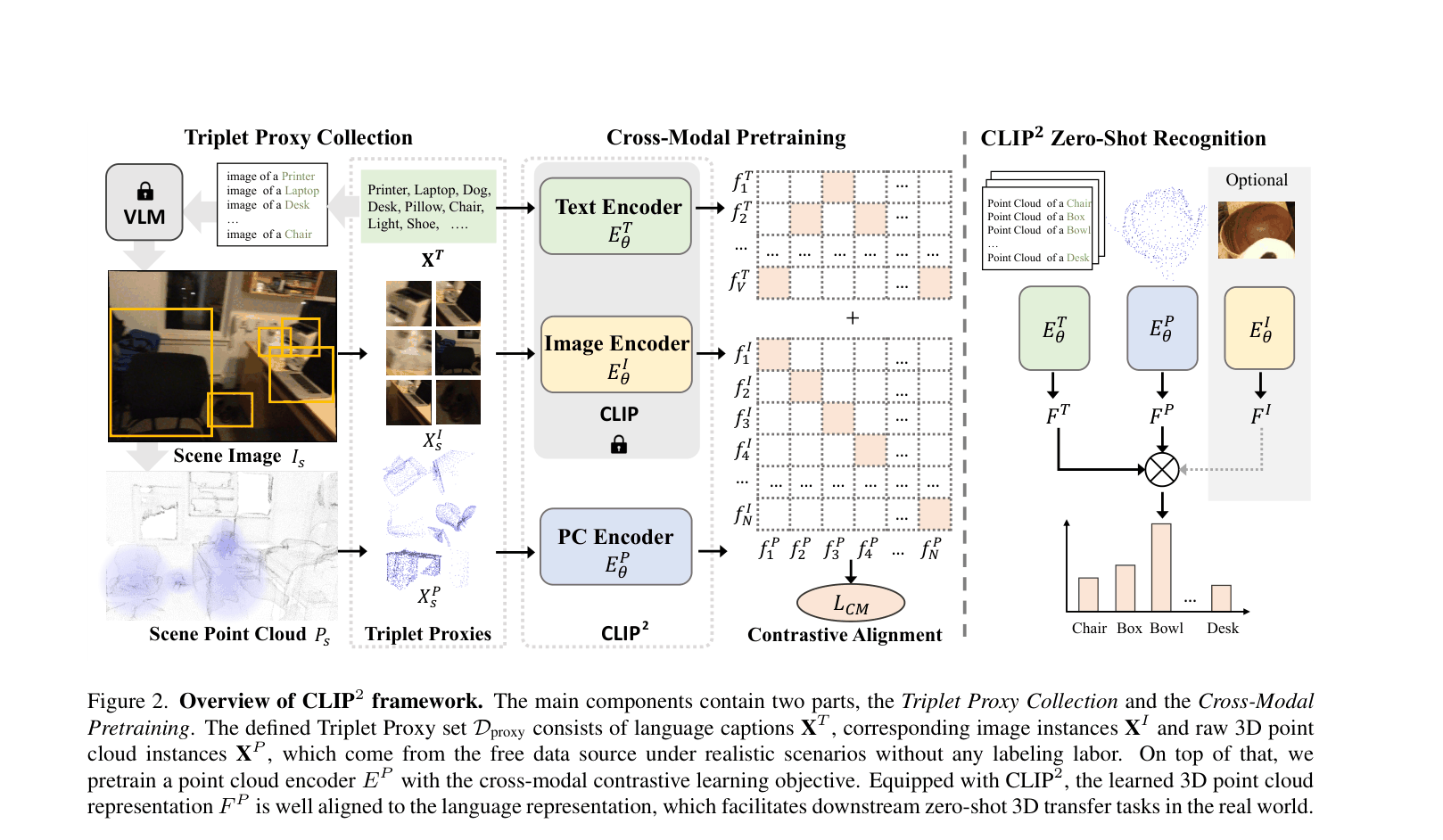
The CLIP2 framework consisting of Triplet Proxy Collection and Cross-Modal Pretraining.
Evaluation Highlights
- +253% relative improvement (37.8% vs 11.7%) on zero-shot recognition in outdoor nuScenes dataset compared to PointCLIP
- +229% relative improvement (61.3% vs 18.6%) on zero-shot recognition in indoor SUN RGB-D dataset compared to Clip2Point
- Achieves 16.1% relative improvement on zero-shot classification for single objects (ScanObjectNN) over state-of-the-art
Breakthrough Assessment
8/10
Significantly outperforms existing projection-based methods by training directly on point clouds using a clever automated data curation strategy. Moves 3D pretraining from synthetic objects to real-world scenes.