📝 Paper Summary
Vision-and-Language Navigation (VLN)
Embodied AI
Hierarchical Planning
DualVLN decouples navigation into two asynchronous systems: a slow VLM that reasons about global goals and a fast diffusion policy that executes agile, obstacle-aware local control.
Core Problem
Existing Vision-Language-Action (VLA) models use tightly coupled end-to-end pipelines that map inputs directly to discrete actions, causing high latency, jerky motion, and poor dynamic obstacle avoidance.
Why it matters:
- High latency in VLA models (often >1s) makes them unsafe for real-world robots interacting with moving people
- Entangling high-level reasoning with low-level control prevents models from reacting quickly to immediate collision threats
- Discrete action spaces (e.g., 'move forward 0.25m') produce unnatural, fragmented robot movement compared to continuous control
Concrete Example:
In a dynamic hallway, a standard VLA might freeze while processing the instruction 'go to the bedroom' and fail to dodge a pedestrian walking into its path because its inference cycle is too slow (e.g., 1.1s) to update the trajectory in time.
Key Novelty
Asynchronous Dual-System Architecture (System 2 Planner + System 1 Controller)
- Decouples reasoning from execution: System 2 (VLM) 'grounds slowly' by identifying mid-term pixel goals, while System 1 (Diffusion Policy) 'moves fast' by generating smooth trajectories at high frequency
- Connects systems via latent queries: Instead of just passing coordinates, System 2 passes rich latent embeddings to System 1, preserving semantic context for the local controller
- Asynchronous execution: The local controller runs at 30Hz using the most recent available plan from the slower global planner, ensuring real-time responsiveness
Architecture
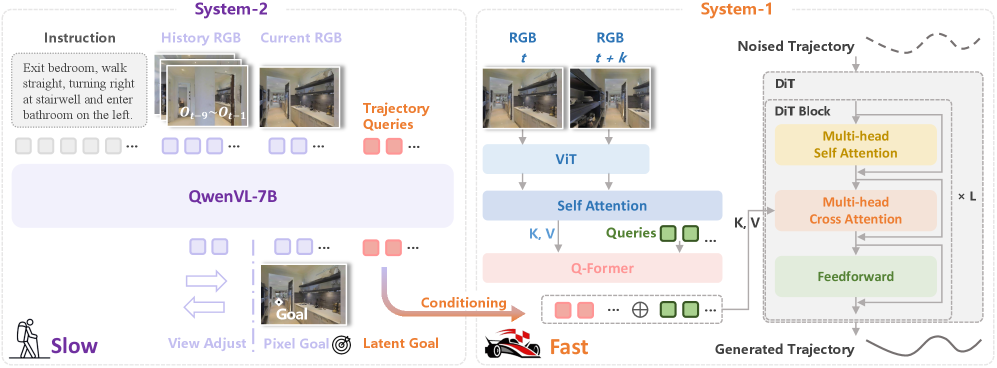
The dual-system architecture. Top: System 2 (VLM) processing instructions and history to output pixel/latent goals. Bottom: System 1 (DiT) taking these goals + current RGB to output trajectory.
Evaluation Highlights
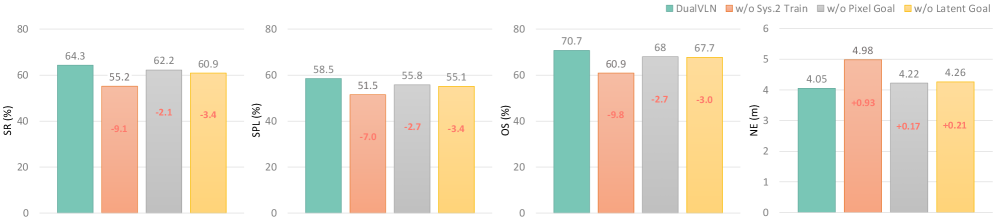
- System 1 achieves 0.03s inference latency (approx. 30Hz), enabling real-time continuous control, compared to 0.7s+ for the VLM planner
- Optimizations reduce System 2's trajectory token inference time from 1.1s to 0.7s using KV-cache reuse
- On the new Social-VLN benchmark, DualVLN maintains higher task completion rates than StreamVLN (though both suffer ~26-27% drops compared to static settings)
Breakthrough Assessment
8/10
Strong engineering of a dual-system approach that practically addresses the latency/control bottleneck of large VLMs in robotics. The introduction of the Social-VLN benchmark is also a valuable contribution.