📝 Paper Summary
Earth Observation (EO)
Vision-Language Models (VLMs)
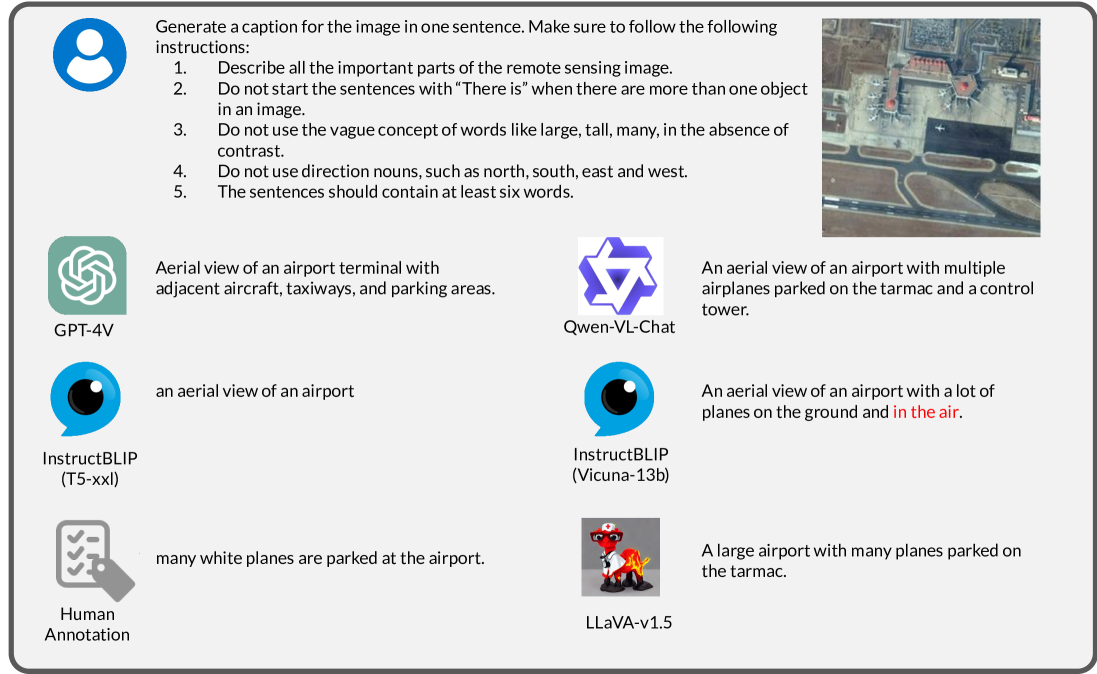
State-of-the-art VLMs like GPT-4V excel at high-level scene understanding and captioning of Earth observation data but fail systematically at fine-grained spatial tasks like counting, localization, and change detection.
Core Problem
It is unclear how well Large Vision-Language Models (VLMs) trained on natural images transfer to Earth Observation (EO) tasks, which involve unique aerial/satellite viewpoints and specialized domain requirements.
Why it matters:
- Analyzing satellite imagery typically requires deep learning expertise or manual annotation, creating barriers for non-experts like disaster relief analysts
- VLMs could democratize EO data access via natural language interfaces, but their actual reliability on geospatial tasks is unknown due to a lack of comprehensive benchmarks
- Current benchmarks focus on natural images (e.g., MMMU, SEED-Bench), leaving a gap in understanding VLM performance on remote sensing data
Concrete Example:
If an analyst asks a VLM to count damaged buildings in a disaster zone using 'before' and 'after' satellite images, GPT-4V might describe the damage qualitatively but fail to output an accurate count or bounding boxes, rendering it useless for quantitative damage assessment.
Key Novelty
Comprehensive EO Benchmark for VLMs
- Constructs a multi-task benchmark spanning scene understanding, localization/counting, and change detection using diverse datasets (landmark recognition, RSICD, xBD, etc.)
- Evaluates both closed-source (GPT-4V) and open-source (LLaVA, InstructBLIP) models on specialized geospatial tasks rather than generic visual reasoning
Architecture
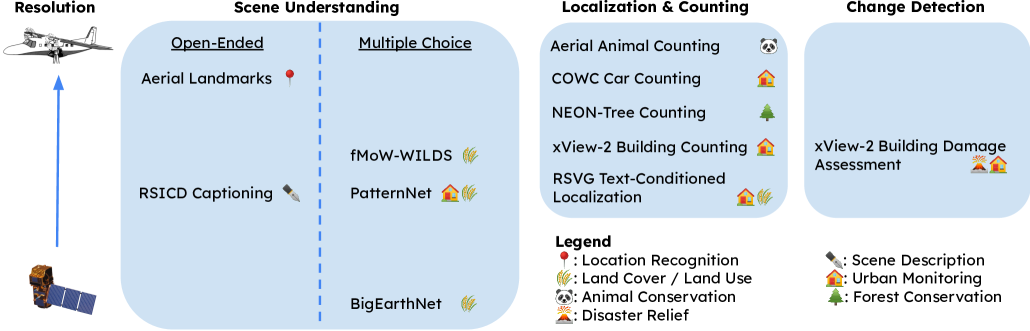
Overview of the benchmark tasks categorized into Scene Understanding, Localization & Counting, and Change Detection.
Evaluation Highlights
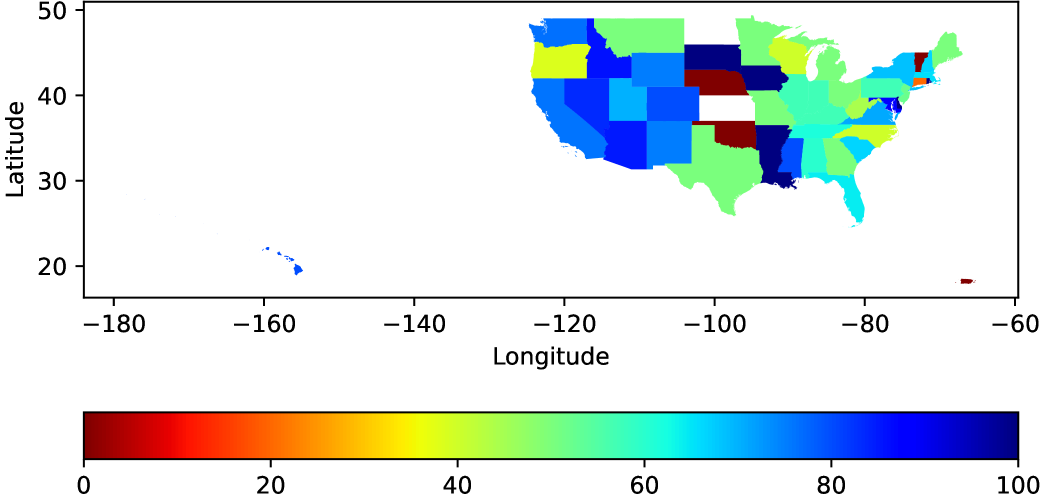
- GPT-4V achieves 67% accuracy on a new aerial landmark recognition task, significantly outperforming open-source models
- On object counting tasks, GPT-4V fails significantly: R² = 0.08 for aerial animal detection and R² = 0.20 for tree counting
- For change detection on disaster imagery, GPT-4V scores R² = 0.10 for counting destroyed buildings, showing a systematic failure to reason about temporal changes
Breakthrough Assessment
7/10
Provides a critical reality check for the application of general-purpose VLMs to scientific domains. While not proposing a new model, the benchmarking methodology and findings are valuable for the EO community.