📝 Paper Summary
Multimodal Agents
Data Science Benchmarks
GUI Automation
Spider2-V is a benchmark evaluating multimodal agents on professional data science workflows, revealing that current SOTA models achieve only 14% success due to complex GUI and coding requirements.
Core Problem
Existing agents are evaluated on simple API-based or daily tasks, failing to capture the complexity of real-world data science workflows that require orchestrating enterprise software via both Code and GUI.
Why it matters:
- Data workflows rely on complex enterprise tools (BigQuery, Airbyte) where API access is often insufficient or requires GUI interaction
- Current benchmarks ignore the 'data engineering' and 'data orchestration' stages, focusing only on analysis or coding in isolation
- Automating these workflows could democratize large-scale data analysis, but current models struggle with the necessary fine-grained visual grounding
Concrete Example:
A task requires saving the top 20 dramatic movies from a Snowflake database to a CSV. The agent must navigate the Snowflake Web GUI to create a worksheet, write SQL, execute it, and then use the OS GUI to rename the downloaded file—a hybrid workflow current agents fail.
Key Novelty
Full-Stack Data Science Agent Benchmark in Executable OS
- Constructs 494 real-world tasks covering the entire data pipeline (warehousing, ingestion, transformation, orchestration) within a live Virtual Machine
- Integrates 20 professional enterprise applications (e.g., dbt, Airflow, Dagster) requiring authentic interaction rather than mock APIs
- Combines visual GUI control (clicking, dragging) with text-based coding (SQL, Python) in a single evaluation framework
Architecture
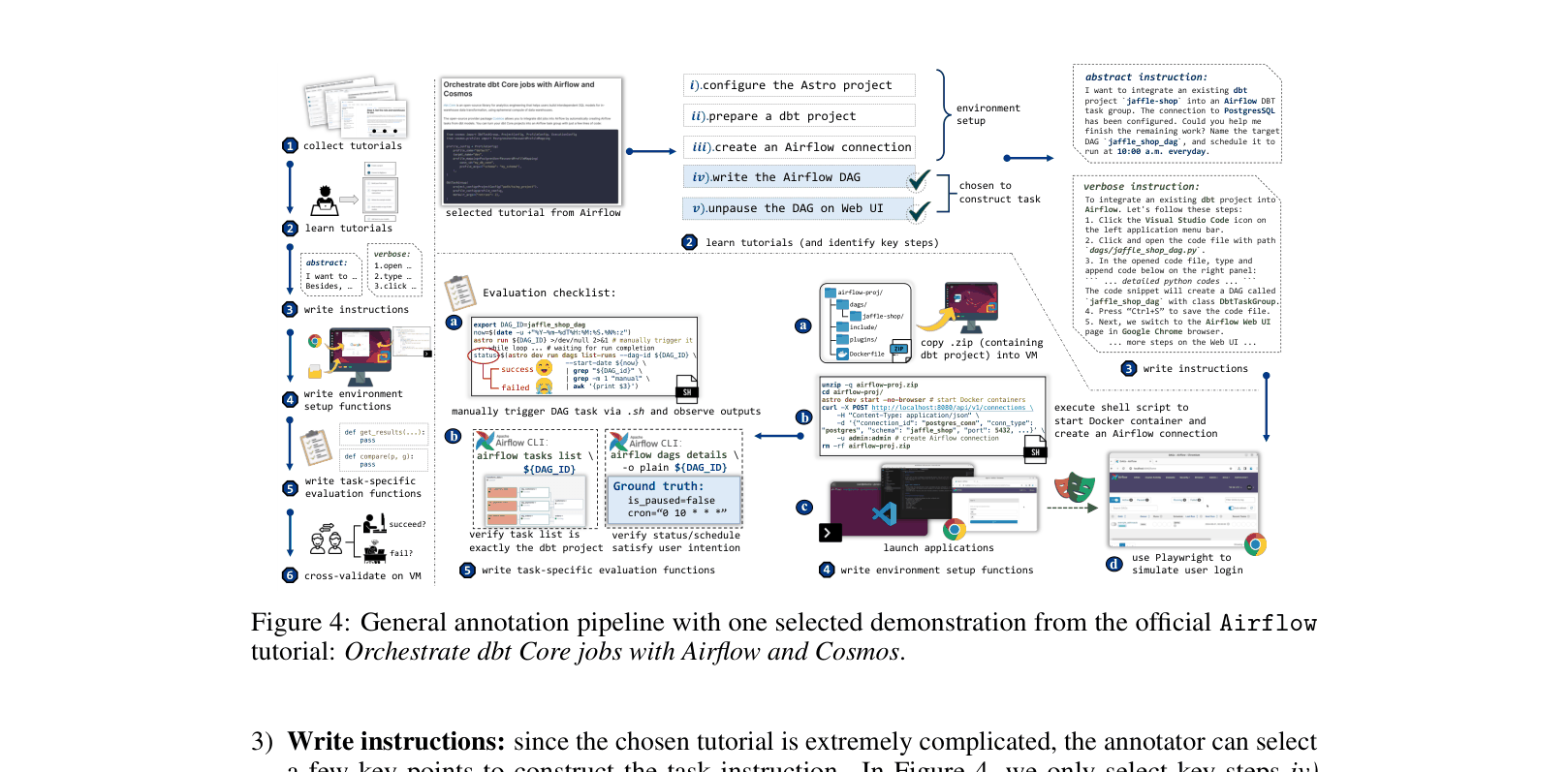
The annotation and task construction pipeline, illustrating how tasks are derived from official tutorials and implemented in the VM.
Evaluation Highlights
- State-of-the-art VLM (GPT-4V) achieves only 14.0% success rate across the full benchmark
- Performance on 'Hard' tasks (requiring >15 steps) drops to 1.2% for GPT-4o, indicating an inability to handle long-horizon workflows
- Providing verbose, step-by-step instructions only improves GPT-4o performance from 11.3% to 16.2%, showing that execution grounding remains a bottleneck
Breakthrough Assessment
9/10
A highly rigorous, realistic benchmark that exposes a massive gap in current agent capabilities. The integration of enterprise tools and executable environments sets a new standard for data agent evaluation.
