📝 Paper Summary
Agricultural Vision-Language Benchmarks
Crop and Disease Identification
AgroBench is a large-scale, expert-annotated benchmark for evaluating Vision-Language Models on diverse agricultural tasks, revealing that even state-of-the-art models struggle with fine-grained identification like weed detection.
Core Problem
Existing agricultural VLM benchmarks rely on synthetic data generated by models like GPT-4, lack expert validation, and cover limited categories, making it difficult to reliably assess real-world applicability.
Why it matters:
- Reliable automated disease and pest identification is critical for sustainable food production and minimizing economic losses.
- Synthetically generated benchmarks often contain hallucinations or inaccuracies that black-box models cannot verify, misleading researchers about true model performance.
- Farmers need integrated systems that handle diverse tasks (from diagnosis to machinery usage), but current evaluations are narrow and fragmented.
Concrete Example:
In weed identification, open-source VLMs perform near random guess levels (e.g., ~24-30% accuracy) because they lack fine-grained training on specific weed species, a failure obscured by simpler, less rigorous benchmarks.
Key Novelty
AgroBench (Agronomist AI Benchmark)
- Comprehensive expert annotation: Unlike synthetic datasets, all 4,342 QA pairs are verified by human agronomists to ensure factual correctness.
- State-of-the-art coverage: spans 7 distinct tasks (including Disease Management and Machine Usage) and covers 682 disease categories and 203 crop types—significantly more than prior work.
- Real-world focus: Prioritizes images from real farm settings over lab conditions and includes complex reasoning tasks like 'Machine Usage' and 'Traditional Management' often ignored in vision-only datasets.
Architecture

Overview of AgroBench statistics and scope compared to previous datasets
Evaluation Highlights
- GPT-4o achieves the highest overall accuracy of 79.26%, outperforming human baselines (36.79% on a subset) and open-source models.
- Weed Identification (WID) is the hardest task: Open-source models like LLaVA-Next-8B score only 30.05%, barely above random chance (17.90%).
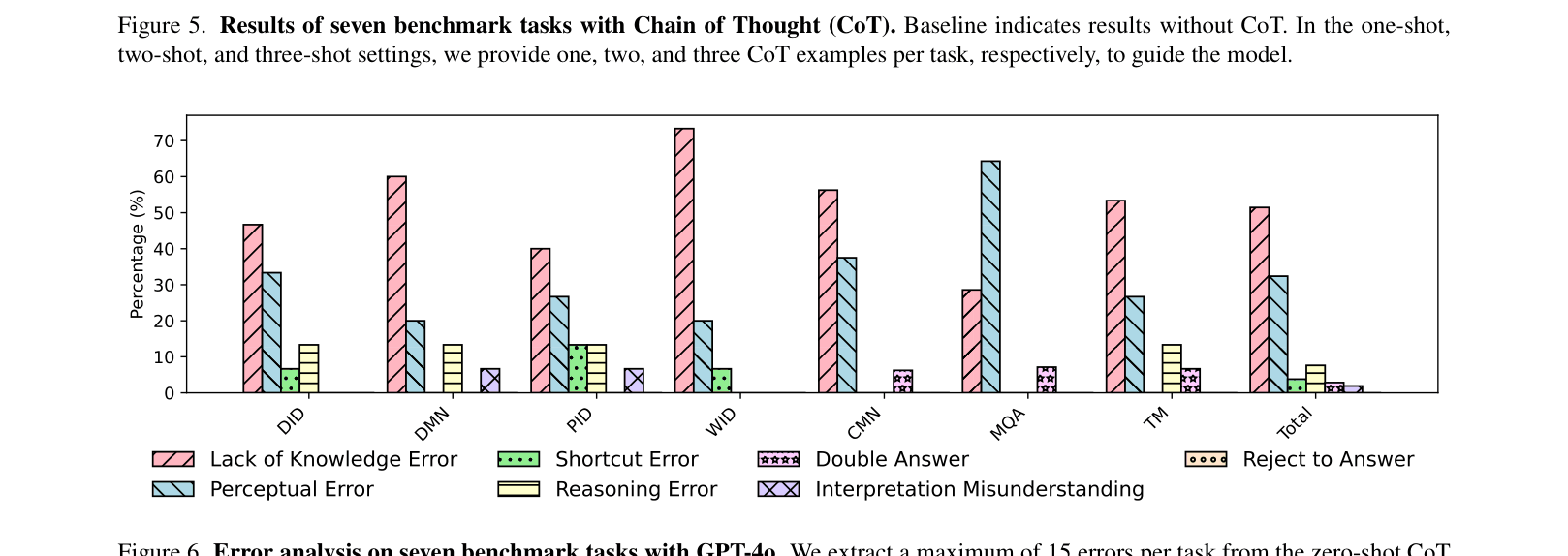
- Chain-of-Thought (CoT) prompting provides marginal gains, boosting overall accuracy from 70.57% to 73.71% in one-shot settings but saturating quickly.
Breakthrough Assessment
9/10
Sets a new standard for agricultural VLM benchmarking with expert-verified data and massive category coverage, exposing significant gaps in current model capabilities.