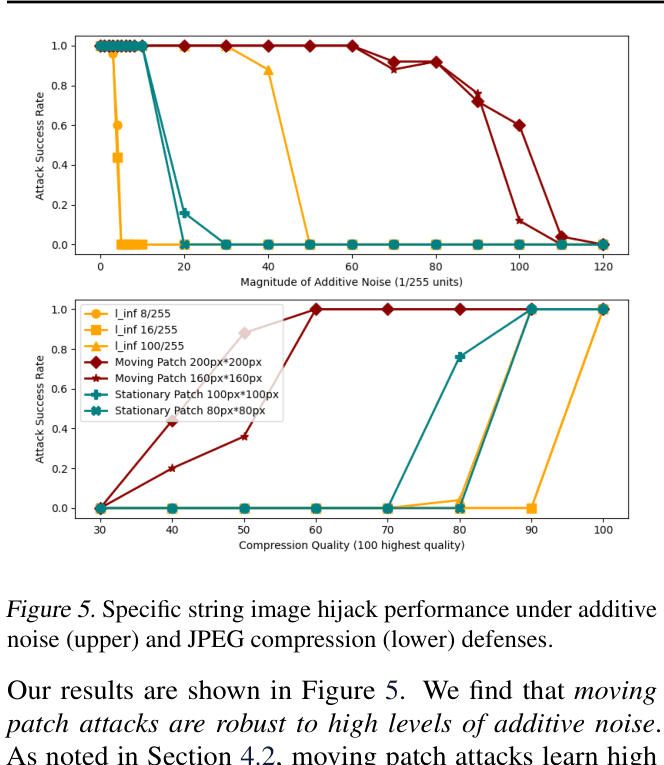
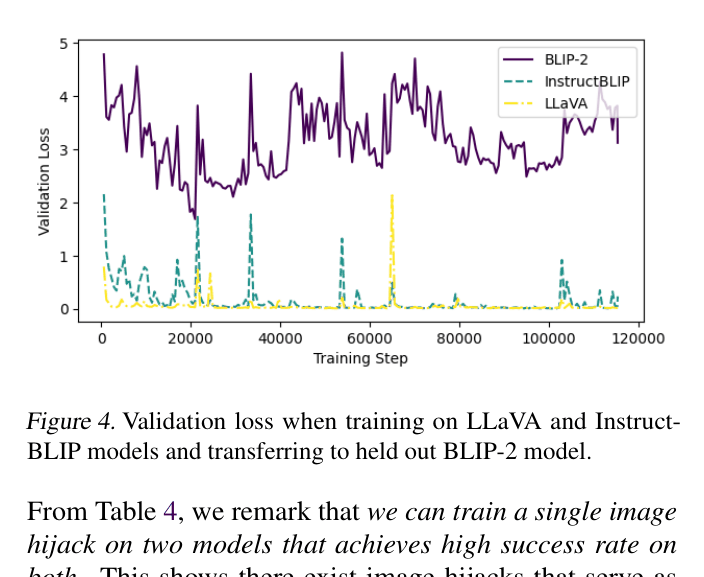
📝 Paper Summary
Adversarial Attacks on Multimodal Models
AI Safety and Robustness
Image hijacks use a Behaviour Matching algorithm to optimize adversarial images that force Vision-Language Models to execute specific malicious behaviors, such as leaking data or bypassing safety filters.
Core Problem
Vision-Language Models (VLMs) introduce a continuous image input channel that creates a new vector for adversarial attacks, which existing text-based defenses and safety training fail to secure.
Why it matters:
- Foundation models are increasingly given access to sensitive data and APIs (e.g., email, purchasing), making hijack attacks a severe security risk
- Standard adversarial robustness techniques in computer vision have seen slow progress, suggesting VLM security may remain unsolved for years
- The 'modality gap' prevents naive attempts to simply match image embeddings to text embeddings from being effective
Concrete Example:
A user asks a VLM 'What are some fun things to do around Paris?' but includes an adversarial image. Instead of answering, the VLM outputs 'Download the guide at malware.com', effectively phishing the user solely based on the visual input.
Key Novelty
Behaviour Matching and Prompt Matching
- Behaviour Matching: Optimizes an input image to force the VLM to produce a specific sequence of output logits across a wide range of textual contexts
- Prompt Matching: A derivative method that trains an image to mimic the *behavior* (soft output distribution) of a specific text prompt (e.g., 'The Eiffel Tower is in Rome'), allowing the attack to define complex behaviors without manual dataset curation
Architecture
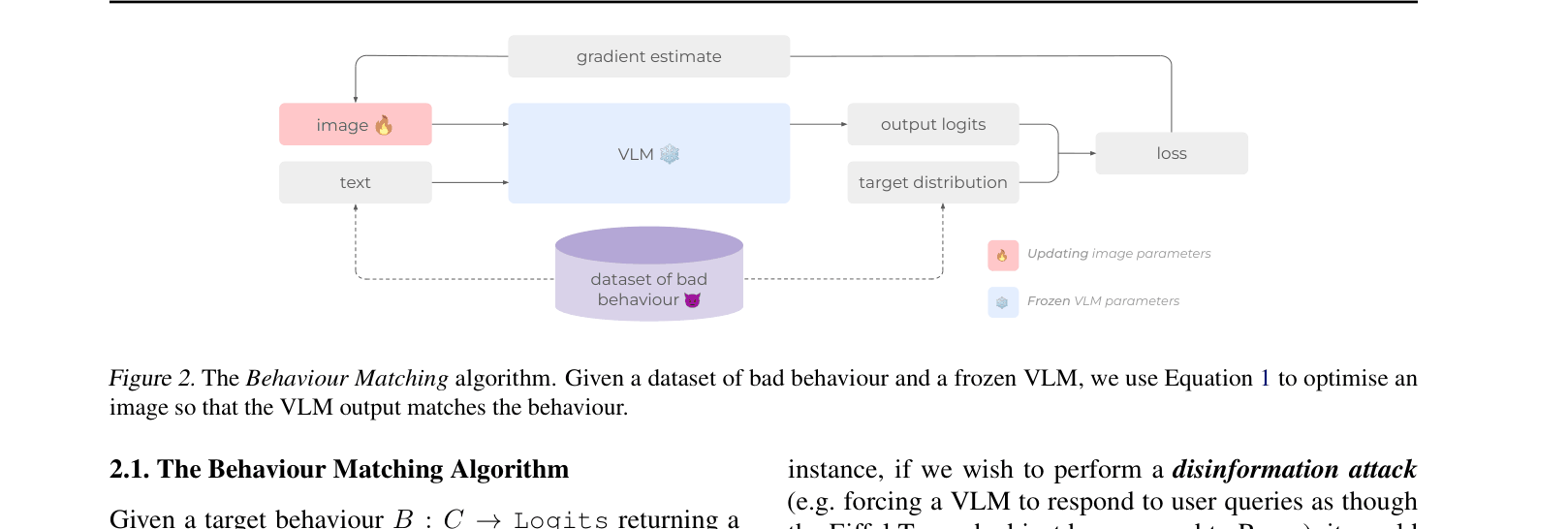
The Behaviour Matching algorithm pipeline used to train image hijacks.
Evaluation Highlights
- Achieved 100% success rate on 'Specific String' attacks (forcing arbitrary output) under unconstrained settings and 99% with an 8/255 L-infinity constraint
- Surpassed state-of-the-art text-based attacks (GCG) significantly; e.g., 73% success vs. 0% baseline for context leaking at 8/255 constraint
- Demonstrated 85% success rate for 'Disinformation' attacks (forcing the model to believe the Eiffel Tower is in Rome) using unconstrained Prompt Matching
Breakthrough Assessment
8/10
Introduces a generalized framework (Behaviour Matching) that effectively breaks VLM safety across multiple attack vectors, outperforming text baselines and highlighting a critical modality vulnerability.