📝 Paper Summary
Mobile UI Agents
Vision-Language Models (VLMs)
MobileVLM enhances mobile agents by pre-training a Vision-Language Model on a new massive graph-structured dataset to explicitly learn both individual screen elements and the transition logic between screens.
Core Problem
General Vision-Language Models lack exposure to mobile UI data, causing them to miss fine-grained element details (intra-UI) and fail to understand how different app pages logically connect (inter-UI).
Why it matters:
- Existing VLMs trained on general images (like LAION-5B) struggle with the dense text and specific layout patterns of mobile interfaces
- Current mobile datasets are often static screenshots or simple chains, failing to capture the complex graph structure of real-world app interactions
- Without understanding inter-UI relationships, agents cannot effectively plan multi-step navigation tasks across different app screens
Concrete Example:
In a multi-step navigation task like 'find the edit profile button,' a general VLM might miss a small icon (intra-UI failure) or fail to predict that clicking 'Settings' is the necessary prerequisite step to reach the profile page (inter-UI failure).
Key Novelty
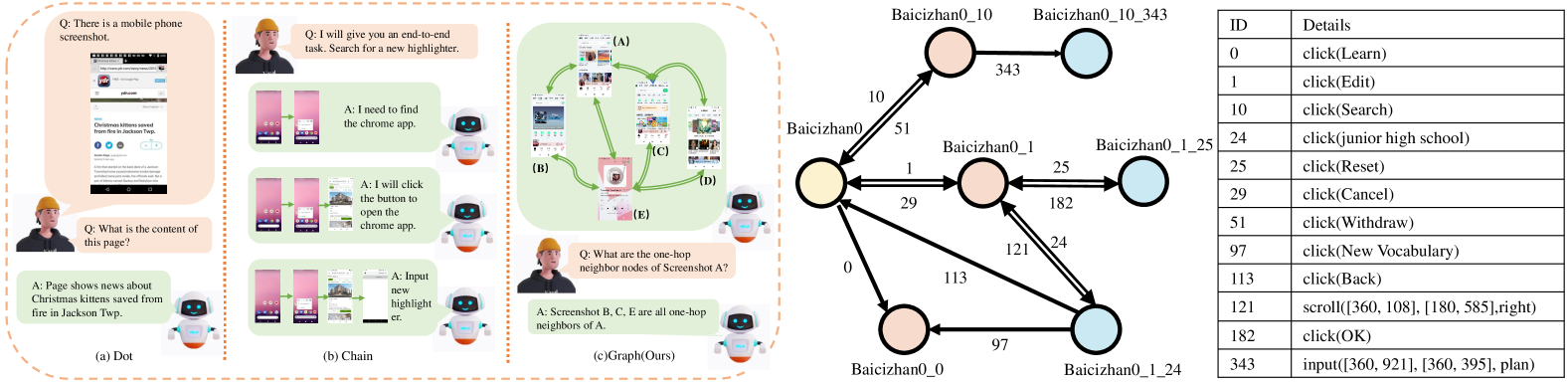
Graph-structured Mobile Pre-training
- Constructs Mobile3M, a dataset where apps are represented as directed graphs (nodes=pages, edges=actions), enabling the model to learn transition logic rather than just static interpretation
- Implements a multi-stage training strategy that explicitly separates learning 'what is on the screen' (element grounding) from 'where does this action go' (action prediction) before final instruction tuning
Architecture
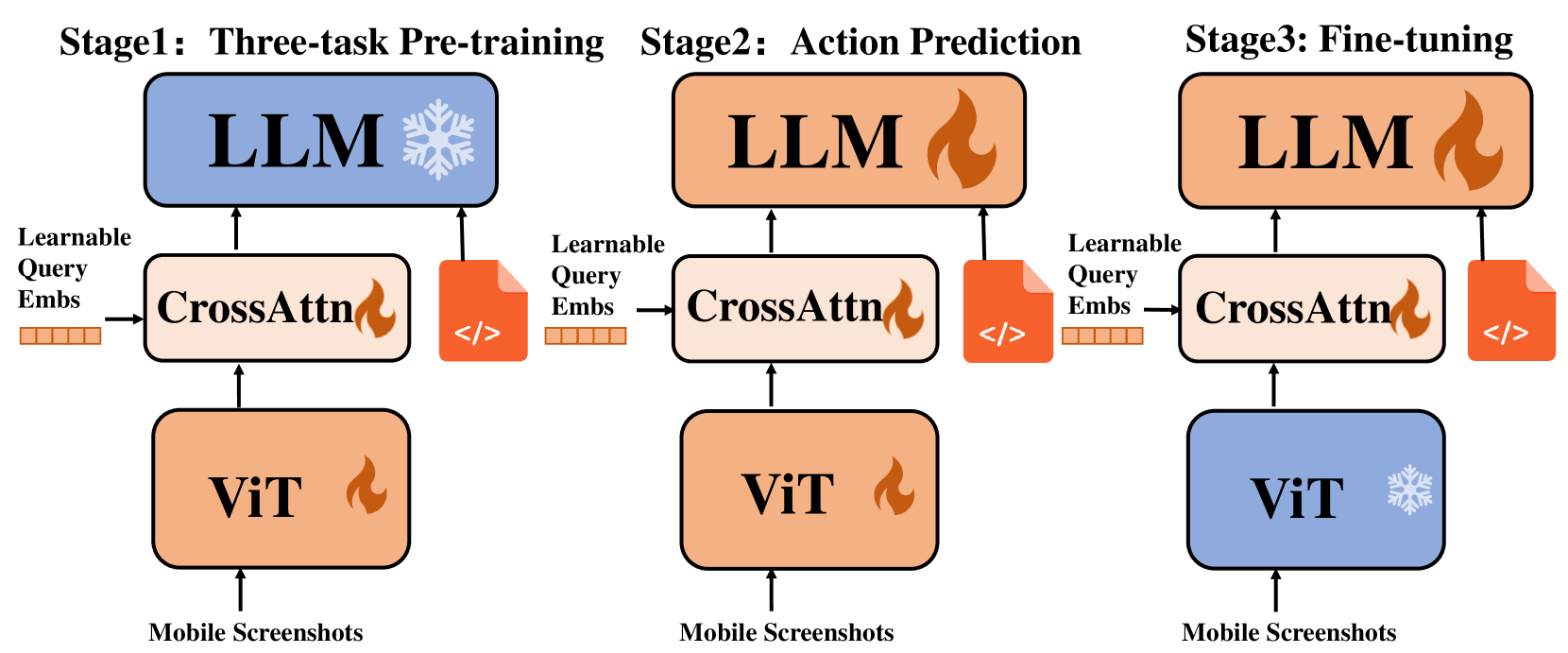
The three-stage training pipeline of MobileVLM.
Evaluation Highlights
- +14.34% improvement on ScreenQA compared to Qwen-VL-Max, demonstrating superior understanding of screen content
- +34.18% improvement on Self-Navigation tasks compared to Qwen-VL-Max, showing the benefit of learning inter-UI graph structures
- Outperforms the Auto-UI state-of-the-art model by 2.78% on the Auto-UI benchmark despite translation overheads
Breakthrough Assessment
7/10
Significant contribution in dataset construction (graph-based vs. sequence-based) and a logical pre-training curriculum. Strong empirical results on domain-specific tasks, though the underlying architecture is standard.