📝 Paper Summary
Remote Sensing
Vision-Language Models (VLMs)
SkyScript is a large-scale dataset created by automatically linking satellite imagery with OpenStreetMap tags via geo-coordinates, enabling a remote sensing VLM that outperforms baselines in zero-shot classification.
Core Problem
Remote sensing lacks large, semantically diverse image-text datasets because satellite imagery cannot be crawled from the web like natural images, and manual annotation is expert-intensive and limited in scale.
Why it matters:
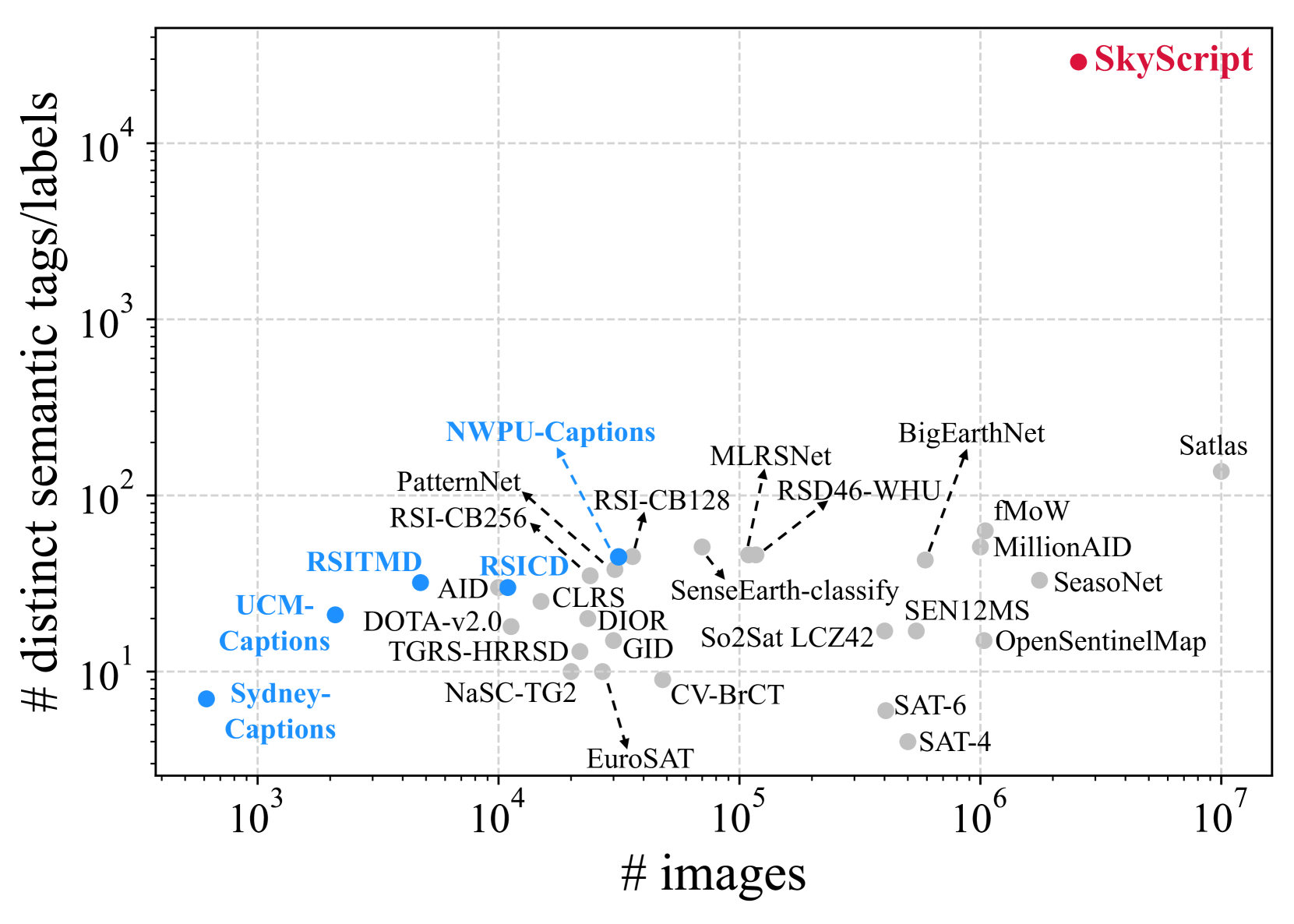
- Existing remote sensing datasets are small (<1 million images) and cover few classes (<150), limiting the development of versatile foundation models
- Standard web-crawling methods (used for LAION) fail because satellite images are proprietary and rarely surrounded by relevant descriptive text on the internet
- The lack of diverse training data hinders the application of VLMs to critical tasks like climate change mitigation and infrastructure monitoring
Concrete Example:
A 'power pole' might be identifiable in a 0.1m resolution image but not in a 10m image; existing datasets lack the fine-grained metadata to distinguish visually groundable attributes from non-visual ones, leading to noisy or sparse training signals.
Key Novelty
Geo-Coordinate Data Mining from OpenStreetMap (OSM)
- Constructs image-text pairs by matching open satellite imagery (Google Earth Engine) with crowdsourced geographic tags (OSM) based on exact location coordinates rather than web text crawling
- Implements a 'visual groundability' filter that uses a logistic regression model on CLIP embeddings to determine if a semantic tag (e.g., 'road surface: asphalt') is visible at the image's specific resolution
Architecture
The data construction pipeline: linking GEE images with OSM tags via geo-coordinates
Evaluation Highlights
- Achieves +6.2% average accuracy gain in zero-shot scene classification across seven benchmark datasets compared to baseline CLIP models
- Constructs a dataset of 2.6 million filtered image-text pairs covering 29,000 distinct semantic tags (two orders of magnitude richer than prior datasets)
- Demonstrates zero-shot transfer capabilities for fine-grained object attribute classification (e.g., road surface materials) and cross-modal retrieval
Breakthrough Assessment
8/10
Significantly addresses the data scarcity bottleneck in remote sensing by proposing a scalable, automated pipeline that generates 2.6M pairs with rich semantics, unlocking effective zero-shot capabilities.
