📝 Paper Summary
Vision-Language Models (VLMs)
Image Captioning
Search and Planning in Language Generation
TDSR reframes image captioning as a coarse-to-fine planning problem, using an efficient, visually-guided Monte Carlo Tree Search to balance global narrative coherence with rich local details.
Core Problem
Standard VLMs use greedy autoregressive generation ('myopic' decision-making), forcing a trade-off between generic safe descriptions and detailed but hallucinated captions.
Why it matters:
- Lack of global planning leads to factual errors and logical breaks when models attempt to generate long, detailed descriptions.
- Existing 'bottom-up' methods that stitch together regional descriptions result in semantic fragmentation and lack a unified narrative structure.
- Current VLMs struggle with complex scene descriptions where multiple details must serve a coherent whole.
Concrete Example:
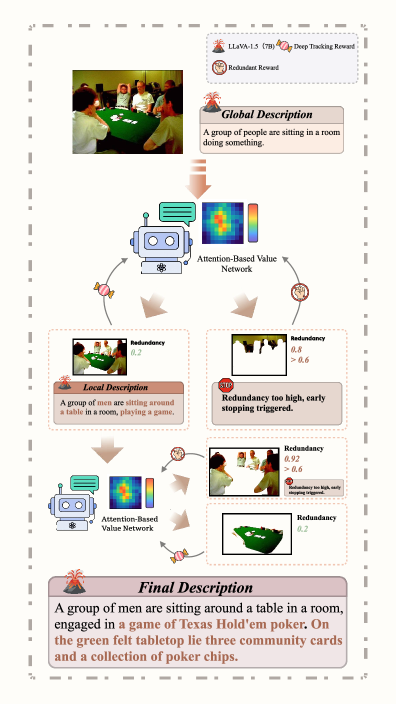
When describing a poker scene, a standard VLM might list cards and chips incoherently. TDSR first plans 'people playing cards', then refines it to 'men sitting around a table playing Texas Hold'em', ensuring the chips and cards mentioned later fit this specific game context.
Key Novelty
Top-Down Semantic Refinement (TDSR) Framework
- Reframes captioning as a hierarchical planning process: generates a high-level 'blueprint' first, then progressively fills in details using MCTS.
- Introduces Visual-Guided Parallel Expansion: uses VLM cross-attention to identify salient regions and prompts the model to explore multiple details simultaneously.
- Employs a Lightweight Value Network: replaces expensive VLM rollouts with a fast, specialized network to estimate the quality of partial captions.
Architecture
Conceptual illustration of the Top-Down Semantic Refinement process compared to human cognition.
Evaluation Highlights
- Reduces call frequency to the expensive base VLM by an order of magnitude compared to standard search methods via the lightweight value network.
- Achieves state-of-the-art or highly competitive results on DetailCaps, COMPOSITIONCAP, and POPE benchmarks (specific numeric scores not contained in provided text snippet).
- Significantly enhances performance of LLaVA-1.5 and Qwen2.5-VL in fine-grained description and hallucination suppression.
Breakthrough Assessment
8/10
Addresses the fundamental 'myopia' of autoregressive VLMs by successfully integrating planning (MCTS) with efficiency optimizations (value net), making search-based generation computationally feasible.