📊 Experiments & Results
Evaluation Setup
Zero-shot and Few-shot evaluation on 9 psychometric tests covering 5 spatial abilities
Benchmarks:
- Mental Rotation Test (MRT) (3D block rotation recognition)
- Money Road-Map Test (MRMT) (Left/right direction sense (Spatial Orientation))
- Santa Barbara Solids Test (SBST) (Geometric cross-section visualization)
- Differential Aptitude Test: Space Relation (2D to 3D folding (Spatial Relation))
Metrics:
- Accuracy (percentage of fully correct answers)
- Pearson correlation (between different spatial abilities)
- Statistical methodology: Pearson correlation analysis to test independence of BSAs; Standard deviation across 3 runs for stability
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Main comparison showing the significant gap between average VLM performance and human benchmarks across spatial tasks. | ||||
| Overall BSA Average | Accuracy | 68.38 | 24.95 | -43.43 |
| Overall BSA Average | Accuracy | 19.6 | 30.82 | +11.22 |
| Intervention experiments measuring the impact of prompting strategies on spatial reasoning. | ||||
| SBST (Geometric Cutting) | Accuracy Gain | 0.00 | 0.100 | +0.100 |
| SBST (Geometric Cutting) | Accuracy Gain | 0.00 | 0.259 | +0.259 |
Experiment Figures
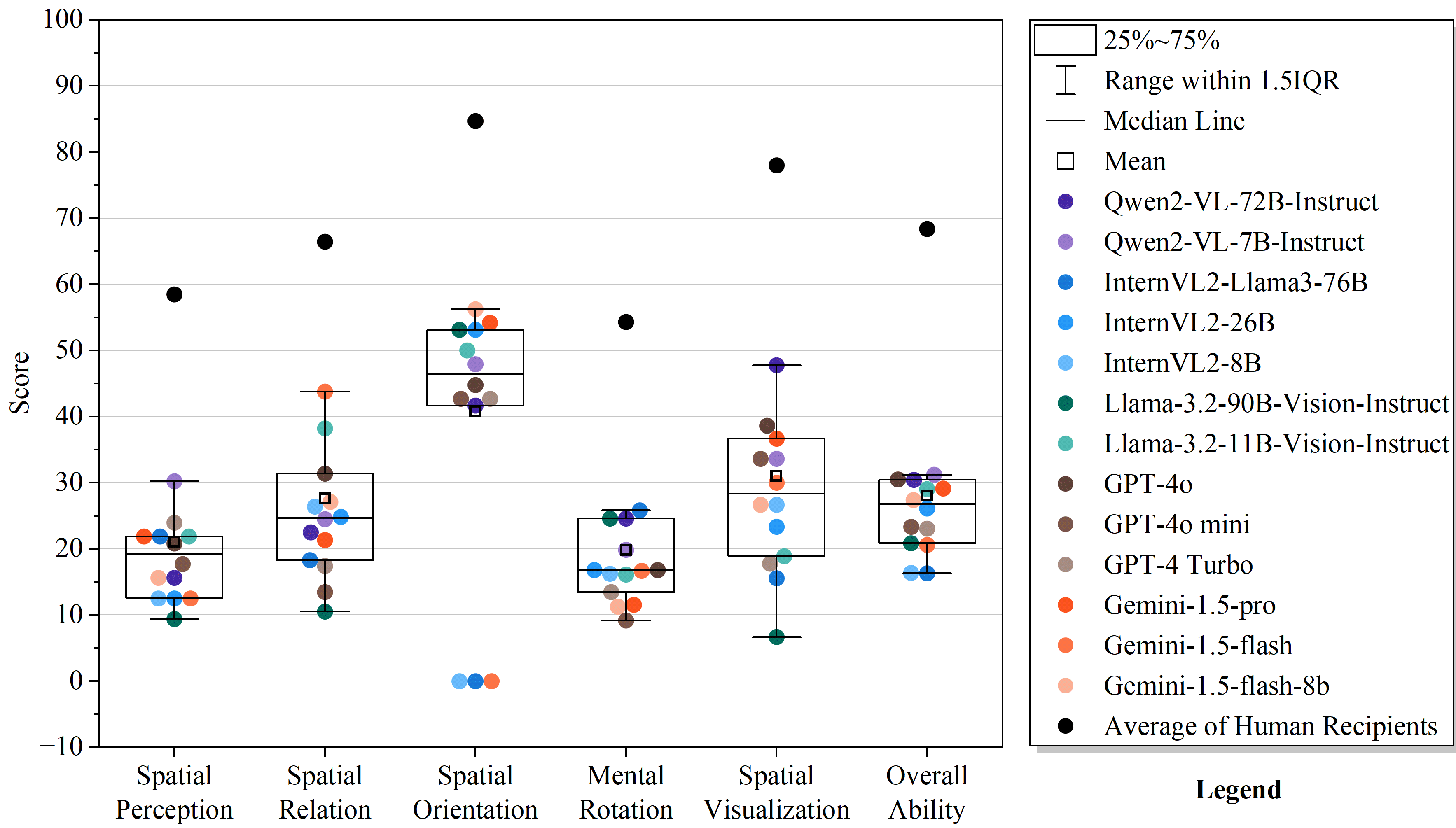
Radar chart comparing average VLM performance against human baselines across the five spatial abilities
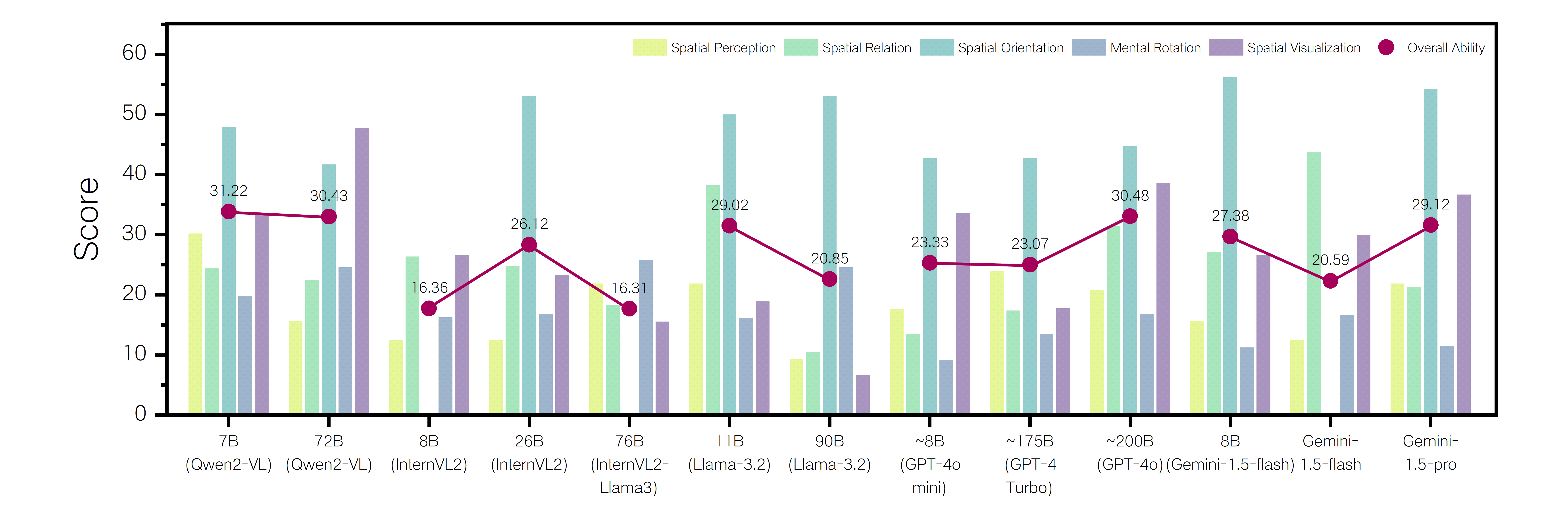
Scatter plot of model performance vs parameter count
Main Takeaways
- VLMs mirror human difficulty hierarchies: performance is strongest in 2D Spatial Orientation and weakest in 3D Mental Rotation
- Scaling laws do not apply to current spatial tasks; smaller, well-architected models (Qwen2-VL-7B) often beat larger ones (GPT-4o, InternVL2-76B)
- Spatial abilities in VLMs are independent (Pearson's r < 0.4), suggesting they require distinct computational mechanisms rather than a single 'spatial' module
- Chain-of-Thought and Few-shot prompting provide limited gains, indicating that the core deficit is a lack of dynamic simulation capability (mental rotation engine) rather than just pattern recognition