📝 Paper Summary
Multimodal Sequential Recommendation (MSR)
Large Vision Language Models (LVLMs)
Generative Recommendation
MSRBench evaluates three commercial Large Vision Language Models across five integration strategies for sequential recommendation, finding that using LVLMs as rerankers is the most effective but computationally expensive approach.
Core Problem
Traditional multimodal sequential recommenders use shallow alignment that may overlook intricate correlations between modalities, while the best strategies for integrating powerful Large Vision Language Models (LVLMs) into these systems remain unstudied.
Why it matters:
- Current multimodal systems struggle to fully leverage complex visual-textual relationships crucial for web-based content
- There is no systematic benchmark comparing different roles LVLMs can play (e.g., direct recommender vs. enhancer vs. reranker)
- Industry adoption requires understanding the trade-offs between recommendation accuracy gains and the high computational cost of LVLMs
Concrete Example:
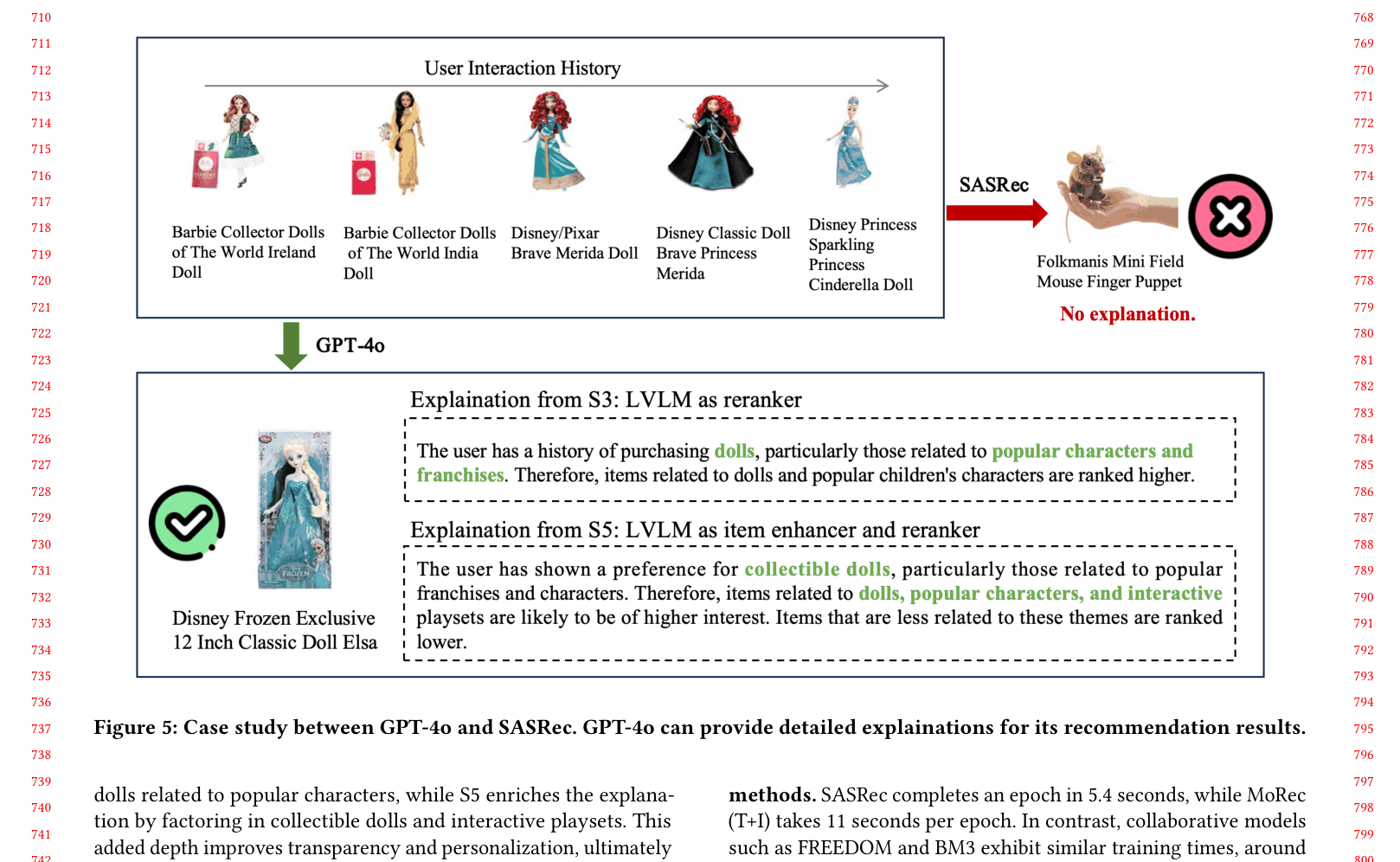
In a SASRec system, a user who buys dolls receives a generic 'finger puppet' recommendation because the model misses the specific visual style preference. In contrast, an LVLM acting as a reranker can analyze the visual consistency of the user's history and correctly recommend a 'collectible doll' instead.
Key Novelty
MSRBench: A Systematic Evaluation of LVLM Roles in Recommendation
- Defines five distinct strategies for LVLM integration: direct recommender, item enhancer (captioning), reranker, and hybrid combinations
- Constructs 'Amazon Review Plus', an augmented dataset where every item image is captioned by three state-of-the-art LVLMs to enable text-rich modeling
- Conducts the first comprehensive empirical study comparing commercial LVLMs (GPT-4V, GPT-4o, Claude-3) against specialized multimodal baselines
Architecture
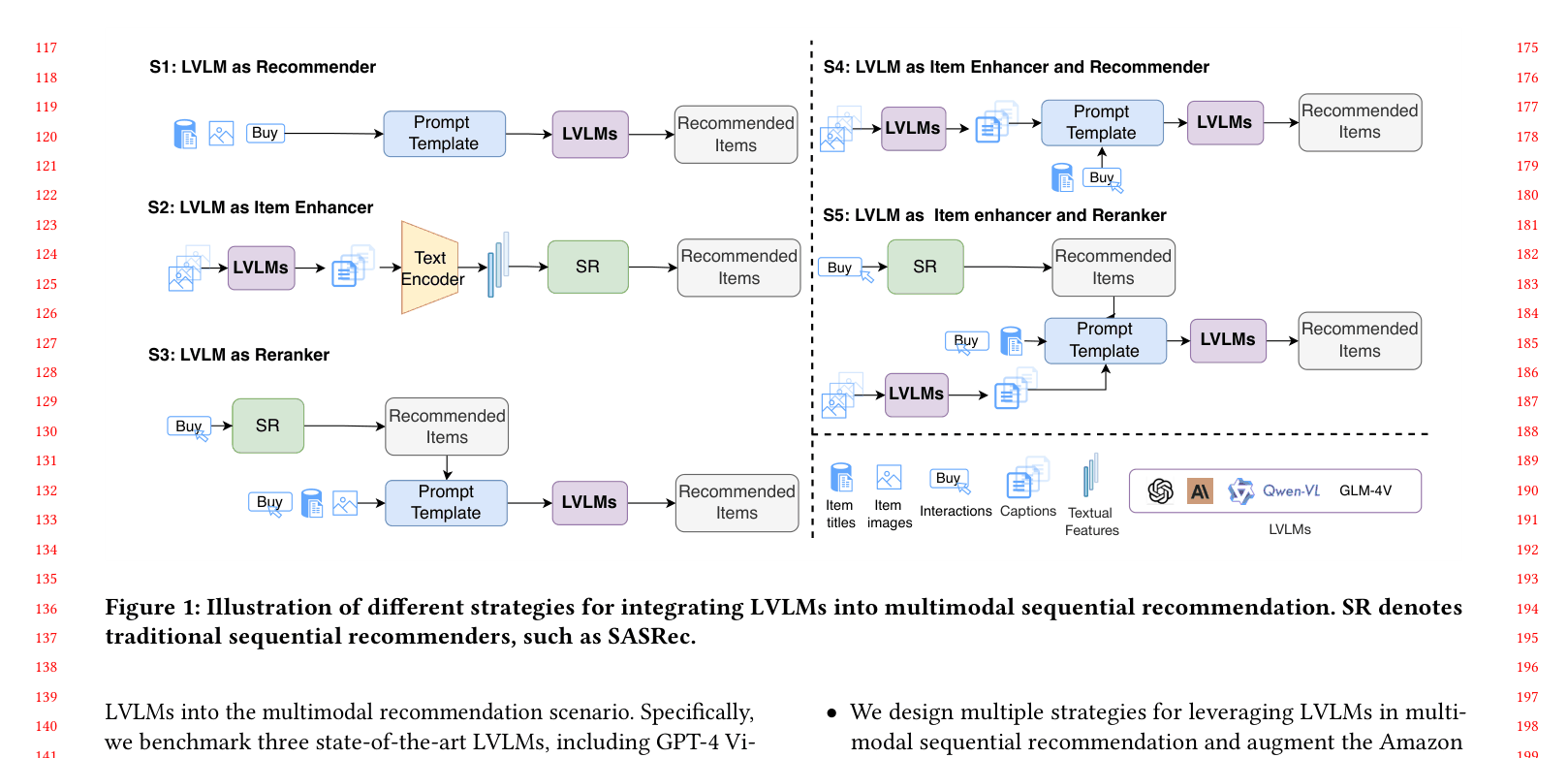
Five different strategies (S1-S5) for integrating LVLMs into the recommendation pipeline
Evaluation Highlights
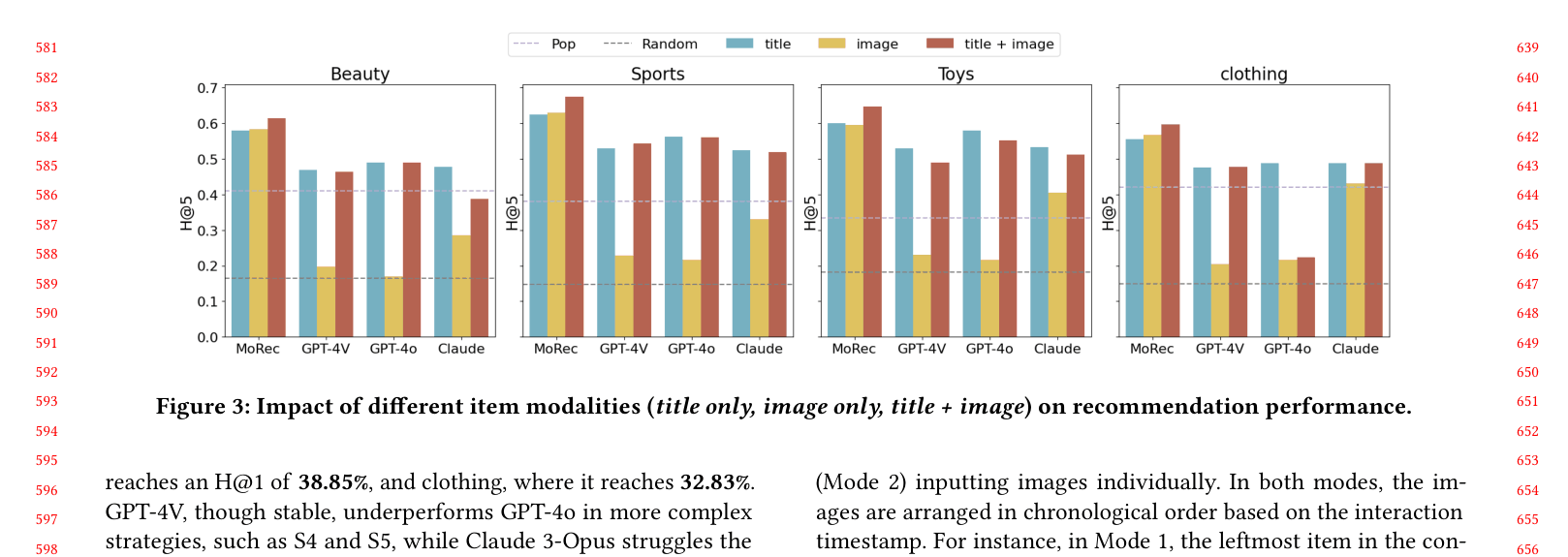
- GPT-4o as a reranker (Strategy 3) achieves 38.85% H@1 on the Beauty dataset, significantly outperforming the best baseline FREEDOM (33.00%)
- Using LVLMs as rerankers (S3) consistently outperforms using them as direct recommenders (S1), with S3 achieving ~1.6x higher H@1 than S1 for GPT-4o on Beauty (38.85% vs 23.37%)
- LVLM inference is computationally expensive: S3 (Reranker) with GPT-4V requires ~42.49 seconds per user, compared to 0.0025 seconds for traditional baselines
Breakthrough Assessment
7/10
Provides a crucial, systematic empirical foundation for LVLM usage in recommendation. While methodologically standard (benchmarking existing models), the insights on strategy trade-offs and efficiency are highly valuable for the field.