📝 Paper Summary
Modularized RAG pipeline
Context Compression
REFRAG accelerates RAG inference by feeding pre-computed, compressed chunk embeddings directly into the decoder instead of raw tokens, using a reinforcement learning policy to selectively expand only critical chunks.
Core Problem
RAG systems suffer from high latency (Time-To-First-Token) and memory usage because they process long, concatenated retrieval contexts where many tokens are irrelevant or redundant.
Why it matters:
- Long contexts increase KV cache memory linearly and TTFT quadratically, limiting throughput for web-scale applications
- Current methods treat RAG contexts as generic text, ignoring the unique block-diagonal sparsity where retrieved passages are often unrelated to each other
- Repeatedly encoding the same retrieved passages for different queries is computationally wasteful
Concrete Example:
In a RAG system retrieving 10 passages, a standard LLM must re-process all tokens of every passage for every new query. REFRAG pre-computes embeddings for these passages once; for a new query, it feeds compact embeddings (e.g., 1 embedding per 16 tokens) to the decoder, expanding only the few chunks strictly necessary for the answer.
Key Novelty
Compress-Then-Select Decoding Framework
- Replaces raw context tokens with pre-computed chunk embeddings from a lightweight encoder, reducing the decoder's input sequence length by factors like 16x or 32x
- Employ a 'compress anywhere' mechanism that allows the decoder to mix compressed embeddings and raw tokens seamlessly
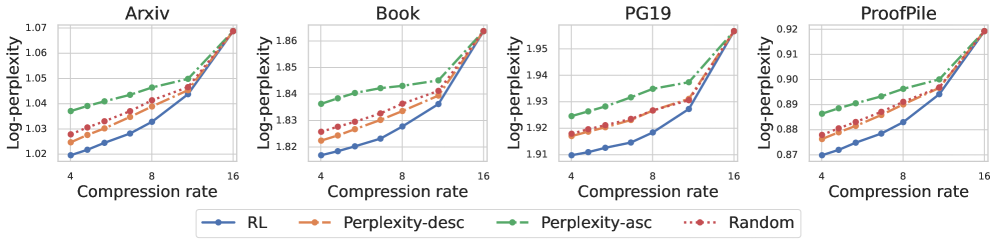
- Uses a lightweight Reinforcement Learning policy to decide dynamically which chunks to keep compressed and which to expand to full tokens for accuracy
Architecture
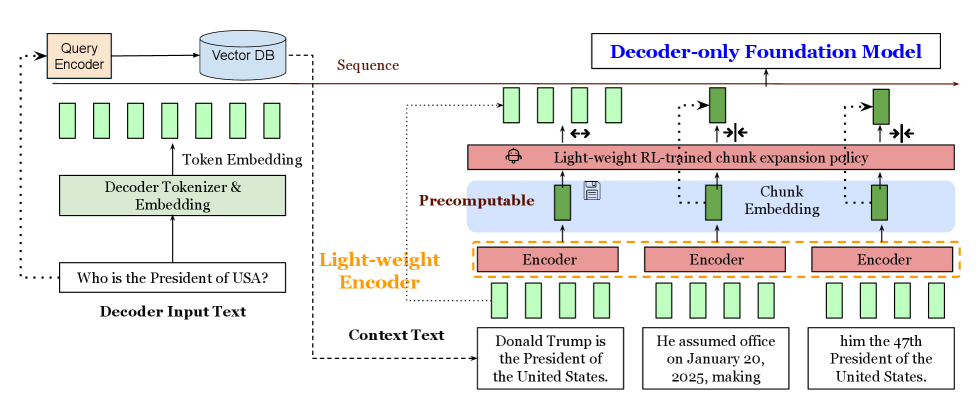
The REFRAG architecture illustrating the compression and decoding process.
Evaluation Highlights
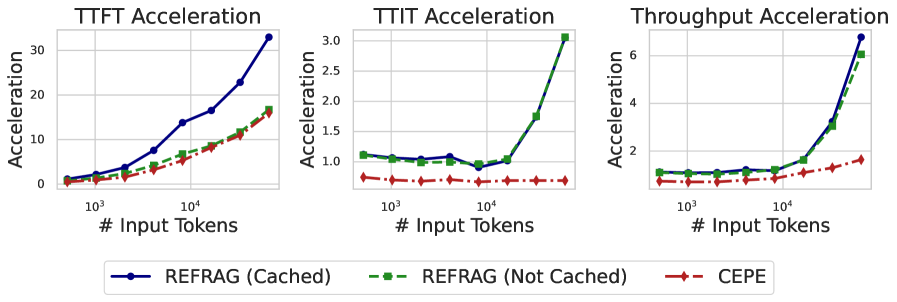
- Achieves 30.85x speedup in Time-To-First-Token (TTFT) compared to LLaMA-2-7B with a compression rate of 32
- Maintains perplexity comparable to full-context LLaMA while being 3.75x faster than the previous state-of-the-art compression method (CEPE)
- Extends effective context window by 16x, outperforming LLaMA on downstream RAG tasks by utilizing more retrieved passages within the same latency budget
Breakthrough Assessment
8/10
Significant practical speedup (30x) for RAG without architectural changes to the base LLM. The ability to mix compressed and raw tokens via RL is a clever, effective solution to the compression-accuracy trade-off.