📝 Paper Summary
Remote Sensing
Vision-Language Models (VLMs)
Disaster Response
DisasterM3 is a large-scale, multi-sensor dataset designed to evaluate and train Vision-Language Models on complex disaster assessment tasks, ranging from damage counting to generating actionable rescue reports.
Core Problem
General-purpose and existing remote sensing VLMs fail in disaster scenarios due to lack of domain-specific data, inability to process multi-sensor inputs (SAR + Optical), and poor performance on fine-grained counting tasks.
Why it matters:
- Disasters require rapid, accurate damage assessment (e.g., counting collapsed buildings) to guide rescue teams, which current generic models cannot reliably provide
- Extreme weather often blocks optical sensors, necessitating the use of Synthetic Aperture Radar (SAR), but most VLMs are trained primarily on optical imagery
- Current remote sensing datasets focus on general geospatial tasks (classification/captioning) rather than the complex reasoning and reporting needed for emergency response
Concrete Example:
In an earthquake scene, generic VLMs like LLaVA-1.5 struggle to identify collapsed vs. intact buildings and fail to reason about safe rescue routes. When provided with a post-disaster SAR image (which looks like noise to untrained eyes), standard models perform poorly compared to optical images due to the modality gap.
Key Novelty
Multi-Hazard, Multi-Sensor, Multi-Task Disaster Benchmark
- Curates 26,988 bi-temporal image pairs (pre/post-disaster) across 36 disaster events, integrating both Optical and Synthetic Aperture Radar (SAR) data to handle weather obstructions
- Defines 9 distinct tasks ranging from basic recognition to complex reasoning (e.g., finding optimal rescue paths) and long-form report generation, creating a full pipeline for disaster response AI
Architecture
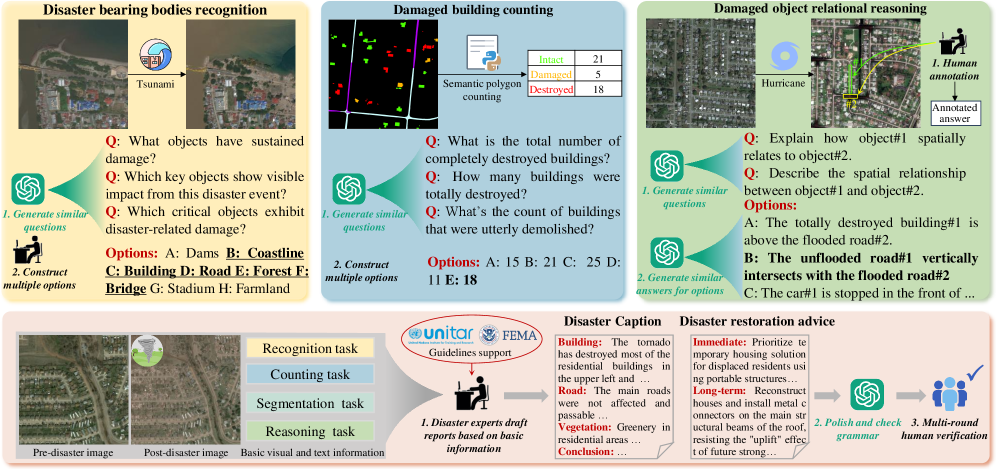
The dataset construction and annotation pipeline.
Evaluation Highlights
- Fine-tuning Qwen2.5-VL-7B on DisasterM3 yields up to +10.4% improvement on Question Answering tasks compared to the base model.
- For Referring Segmentation, fine-tuned PSALM achieves +40.8% improvement in mIoU (mean Intersection over Union) on optical data compared to the baseline.
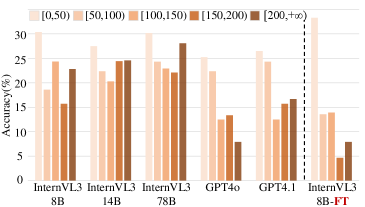
- Integrating SAR imagery remains a challenge: performance on post-disaster SAR images is significantly lower than optical images (e.g., ~38% vs ~64% accuracy for Qwen2.5-VL-7B), highlighting the cross-sensor gap.
Breakthrough Assessment
8/10
Significant contribution to the specialized domain of disaster response. The inclusion of SAR data and complex reasoning tasks (like report generation) pushes the boundary for Remote Sensing VLMs beyond simple classification.