📝 Paper Summary
Vision-Language-Action (VLA) Models
Robot Learning
Instruction Tuning
LLaRA adapts pretrained Vision-Language Models for robot control by converting behavior cloning trajectories into visual conversation data and enhancing them with self-supervised auxiliary tasks like spatial reasoning.
Core Problem
Adapting pretrained Vision-Language Models (VLMs) to robotic control is difficult due to data scarcity and the models' lack of precise spatial awareness required for manipulation.
Why it matters:
- Directly transferring VLMs to robotics often fails because standard vision-language data lacks the spatial precision needed for low-level control
- Curating high-quality conversation-style data for robotics is non-trivial and hard to scale for new domains compared to standard computer vision tasks
- Current approaches often rely on specialized tokens or architectures, limiting the efficient transfer of generalist VLM knowledge to robotic agents
Concrete Example:
A standard VLM trained on image captions might describe a mug's color but fail to output the precise pixel coordinates needed for a robot gripper to grasp the handle, as it lacks fine-grained spatial grounding.
Key Novelty
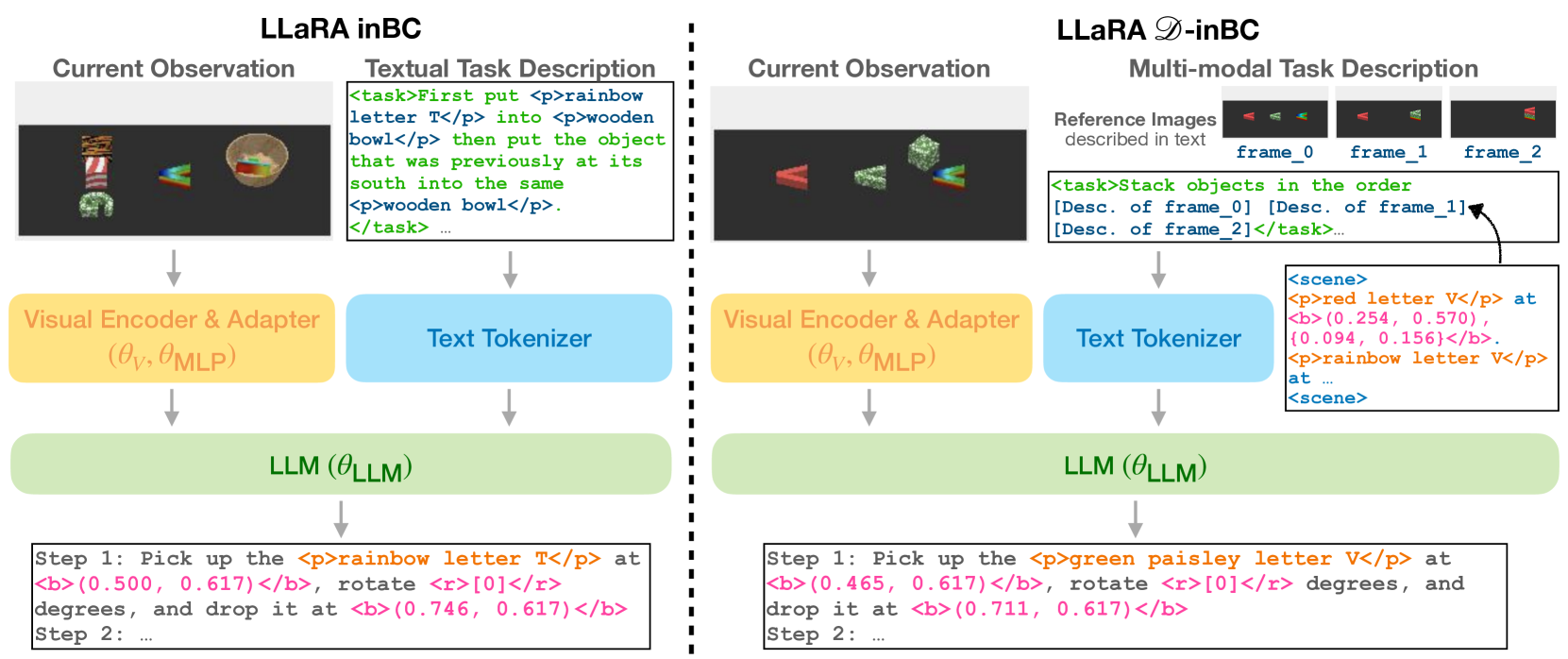
Visuomotor Instruction Tuning with Self-Supervised Auxiliary Data
- Converts standard robot behavior cloning data (state-action pairs) into text-based conversations where actions are represented as normalized image coordinates
- Generates six types of auxiliary instruction-tuning datasets (e.g., spatial relationships, future prediction) from existing trajectories without requiring new human annotations
- Uses a Description-Instruct-BC pipeline to handle multiple-image observations by converting reference images into textual descriptions via object detection
Architecture
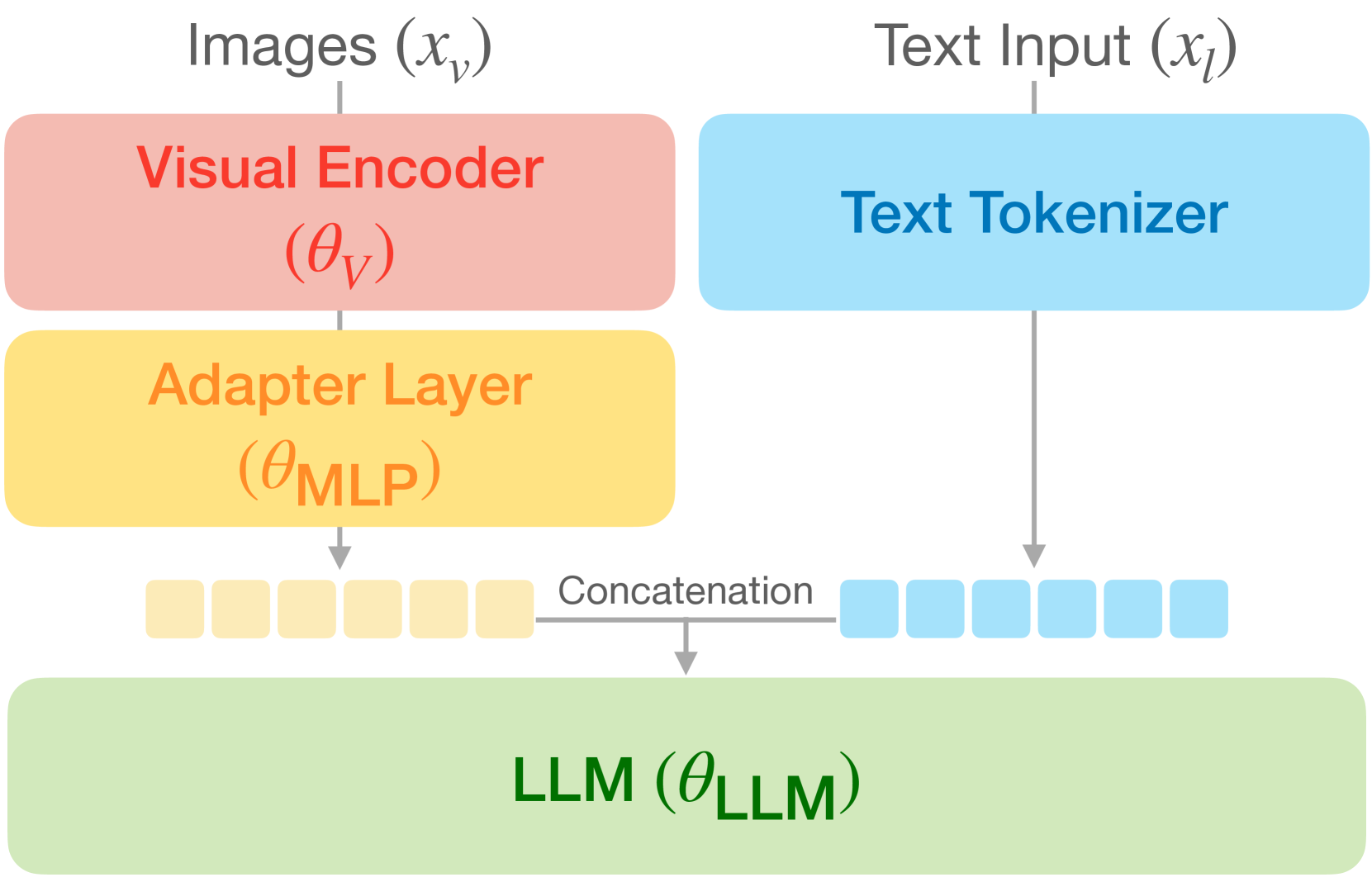
The LLaVA model architecture adapted for LLaRA, showing the flow from image/text inputs to language output.
Breakthrough Assessment
7/10
Proposes a clever, scalable data generation pipeline that bridges the gap between general VLMs and specific robot policies without architectural changes, though the core innovation is primarily data-centric.