📝 Paper Summary
Remote Sensing (RS)
Vision-Language Models (VLMs)
Domain Adaptation
The paper introduces RS5M, the first large-scale (5 million) remote sensing image-text dataset constructed via filtering and captioning, and trains GeoRSCLIP, a domain-specific VLM that significantly outperforms general baselines.
Core Problem
General Vision-Language Models (GVLMs) like CLIP are trained on common objects and underperform on domain-specific remote sensing tasks due to domain mismatch and a lack of large-scale paired RS data.
Why it matters:
- Remote sensing imagery is critical for environmental monitoring and disaster management, but labeling is expensive and requires expertise.
- Existing RS image-text datasets are too small (thousands of pairs vs. millions needed) to effectively transfer or fine-tune powerful pre-trained models.
- Current deep learning models in RS often rely on single-modality data, missing the rich supervision provided by natural language descriptions.
Concrete Example:
When a standard CLIP model pre-trained on internet photos tries to classify satellite imagery, it struggles because it hasn't seen 'hyperspectral' or 'SAR' data concepts, or specific overhead viewpoints (e.g., distinguishing a 'roundabout' from a generic 'road' from space).
Key Novelty
Domain Vision-Language Model (DVLM) Framework via RS5M Dataset
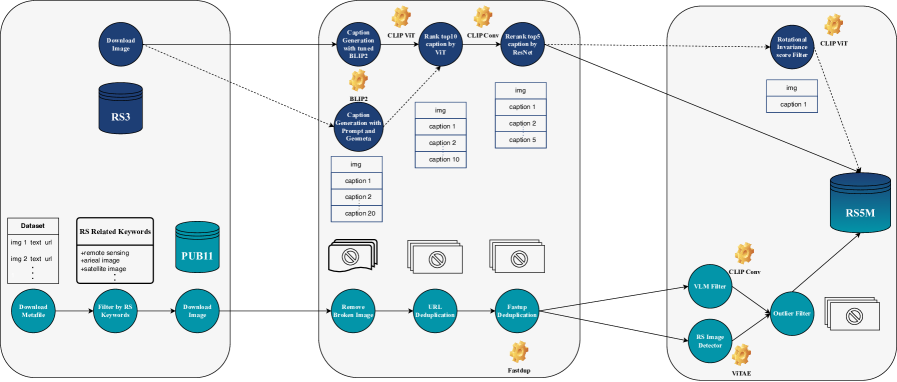
- Constructs a massive 5-million-pair dataset (RS5M) by filtering general internet datasets for RS content and generating captions for existing label-only RS datasets.
- Proposes a 'Domain Vision-Language Model' (DVLM) paradigm that bridges general pre-training and specific downstream tasks using Parameter-Efficient Fine-Tuning (PEFT) on this new data.
- Introduces a rotation-invariant caption selection method during dataset construction to ensure descriptions remain accurate regardless of the satellite image's orientation.
Architecture
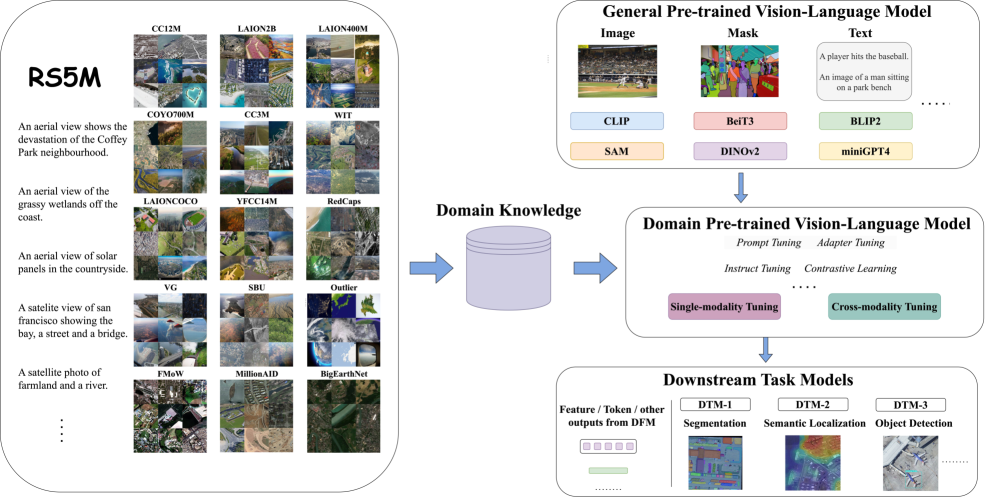
The Domain Vision-Language Model (DVLM) framework concept.
Evaluation Highlights
- +3% to +20% improvement in Zero-shot Classification tasks compared to baselines/state-of-the-art.
- +3% to +6% improvement in Remote Sensing Cross-Modal Text–Image Retrieval (RSCTIR).
- +4% to +5% improvement in Semantic Localization (SeLo) tasks.
Breakthrough Assessment
8/10
The dataset scale (5M pairs) is nearly 1000x larger than previous RS image-text datasets, addressing a critical bottleneck. The resulting model improvements are substantial across multiple tasks.