📝 Paper Summary
Visual Instruction Tuning
Dataset Construction
Vision-Language Models (VLMs)
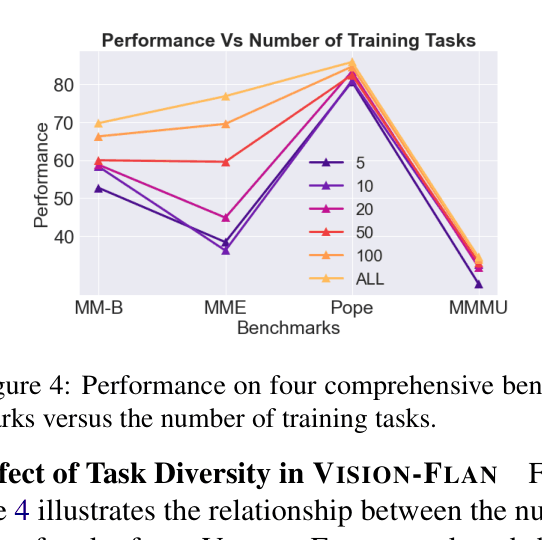
Vision-Flan scales visual instruction tuning with 187 diverse human-labeled tasks to improve VLM capabilities and robustness, demonstrating that only 1,000 synthesized instances are needed for alignment.
Core Problem
Existing Vision-Language Models (VLMs) suffer from poor generalizability, hallucination, and catastrophic forgetting due to low task diversity in pre-training and reliance on biased GPT-4 synthesized instruction data.
Why it matters:
- VLMs like LLaVA perform poorly on basic tasks like OCR because pre-training is dominated by image captioning and lacks diversity
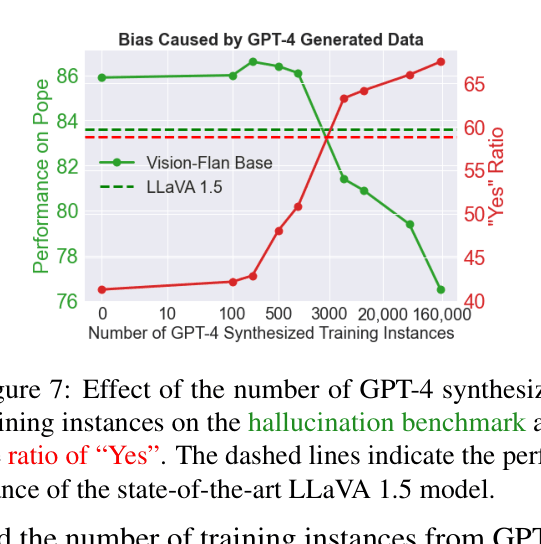
- Reliance on GPT-4 synthesized data introduces spurious correlations and a bias toward positive answers ('Yes'), causing severe hallucinations where models describe objects not present in the image
- Visual instruction tuning often causes catastrophic forgetting, where VLMs lose performance on basic detection tasks (e.g., MNIST, CIFAR-10) compared to their base vision encoders
Concrete Example:
When trained on GPT-4 synthesized data, VLMs frequently answer 'Yes' to questions about object existence even when the object is absent (hallucination) because the training data is biased. Additionally, standard VLMs fail basic OCR tasks absent from caption-heavy pre-training data.
Key Novelty
Two-Stage Tuning with Massive Task Diversity (Vision-Flan)
- Constructs the Vision-Flan dataset by aggregating 187 diverse academic tasks (1.6M instances) re-formatted with expert-written instructions, moving beyond simple captioning
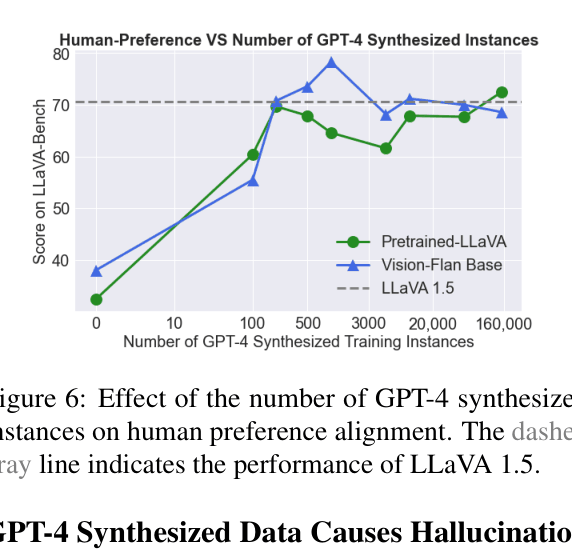
- Proposes a two-stage tuning framework: first fine-tuning on diverse human-labeled tasks for capability, then tuning on a tiny subset (1,000 instances) of GPT-4 data for human-preference alignment
- Empirically proves that visual instruction tuning primarily helps the LLM understand visual features, while the MLP connector is largely learned during pre-training
Architecture
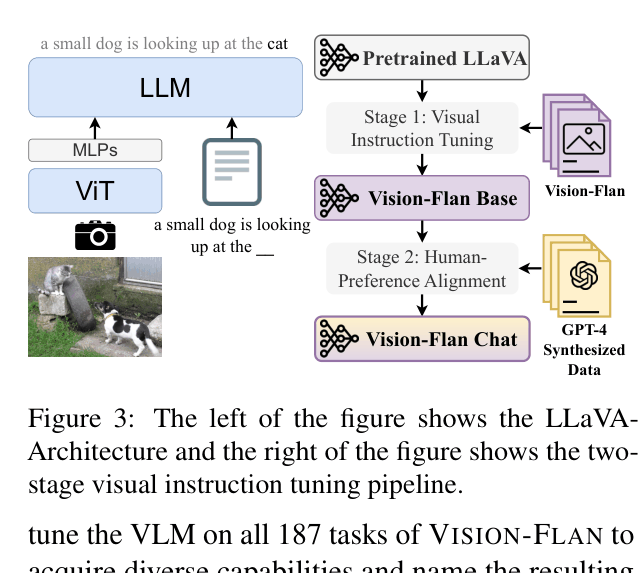
The LLaVA model architecture and the proposed two-stage visual instruction tuning pipeline.
Evaluation Highlights
- +3.1 points on MM-Bench and +6.5 points on MME compared to LLaVA-1.5, achieving state-of-the-art results
- Maintains 84.0% average accuracy on catastrophic forgetting benchmarks (CF), significantly outperforming LLaVA-1.5's 73.3%
- Achieves 78.3 on LLaVA-Bench (alignment metric) using only 1,000 GPT-4 synthesized instances, validating the efficiency of the two-stage approach
Breakthrough Assessment
8/10
Significantly challenges the trend of relying solely on synthesized data, providing a rigorous dataset and methodology that improves robustness and reduces hallucination with minimal synthetic data.