📝 Paper Summary
GUI Agents
Online Reinforcement Learning
Synthetic Data Generation
ZeroGUI enables GUI agents to self-improve via online reinforcement learning by using VLMs to automatically generate training tasks and verify success, removing the need for human supervision.
Core Problem
Existing GUI agents rely on expensive offline human annotations and struggle to generalize to dynamic, interactive environments where elements shift or disappear.
Why it matters:
- Manual collection of action trajectories and element grounding labels is costly and hard to scale across diverse applications
- Agents trained on static offline data often fail in open-ended scenarios due to non-stationary environments
- Real-world deployments lack ground-truth labels, preventing agents from learning from their own interactions
Concrete Example:
In OSWorld, an agent might be asked to 'Browse the natural products database.' An offline-trained agent might fail if the database UI has changed. ZeroGUI allows the agent to practice on generated variations of this task and receive feedback from a VLM judge, correcting its policy without human intervention.
Key Novelty
Self-Evolving Agent Loop via VLM Simulation
- Uses a VLM (Vision-Language Model) to hallucinate diverse tasks from random screenshots, creating an infinite curriculum for the agent
- Replaces hand-crafted evaluation scripts with a VLM-based 'visual judge' that votes on task success based on trajectory screenshots
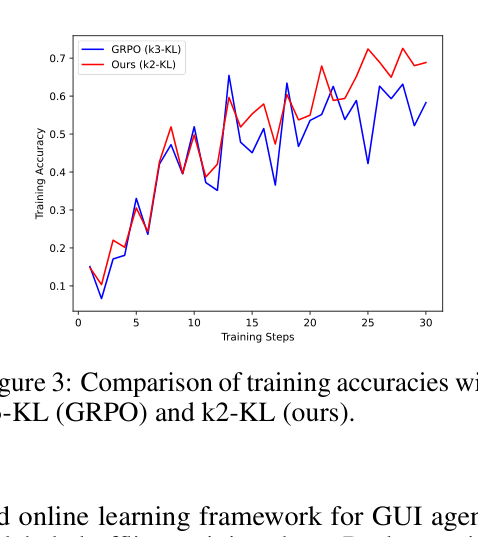
- Adapts the GRPO algorithm for multi-step GUI interactions, enabling the agent to learn from both generated tasks and test-time scenarios
Architecture
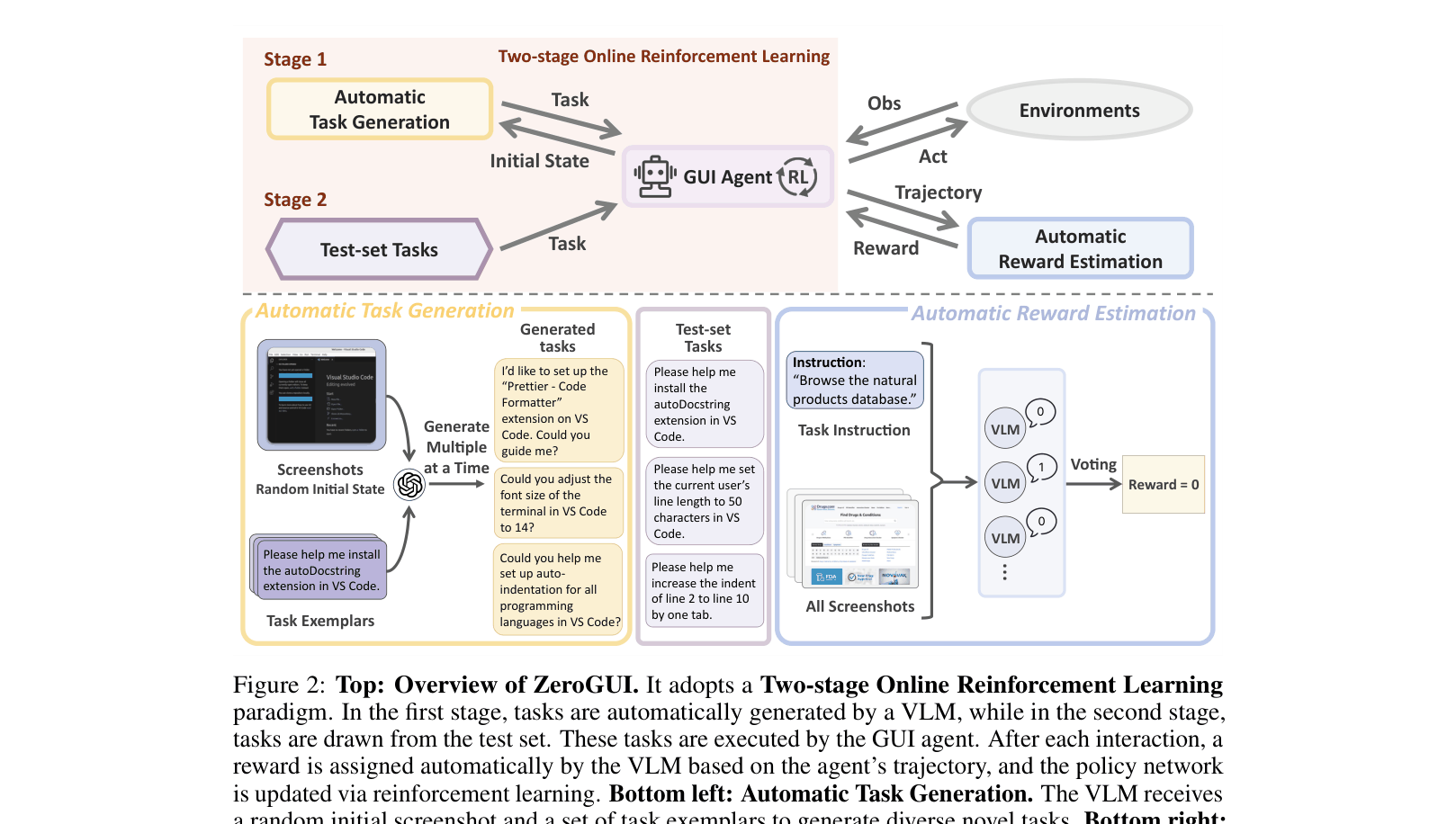
The ZeroGUI framework workflow, illustrating the interaction between the VLM components and the GUI agent during online learning.
Evaluation Highlights
- +63% relative improvement in success rate for Aguvis-7B on the OSWorld benchmark compared to the base model
- +14% relative improvement for UI-TARS-7B-DPO on OSWorld, with significant gains in the feasible task subset (+40%)
- Generalizes to mobile environments: +2.8 success rate improvement on the AndroidLab operation subset
Breakthrough Assessment
8/10
Strong conceptual advance in fully automating the feedback loop for GUI agents. The zero-human-cost framing addresses the primary bottleneck (data) in the field, with significant empirical gains.