📊 Experiments & Results
Evaluation Setup
Pairwise comparison of 20+ VLMs using both crowdsourced human votes (Arena) and automated judging (Bench)
Benchmarks:
- WildVision-Arena (Open-ended VLM Chat) [New]
- WildVision-Bench (Static VLM Evaluation Set (500 samples)) [New]
Metrics:
- Elo Rating
- Spearman's Correlation (between Bench score and Arena Elo)
- Inter-annotator agreement (Cohen's Kappa)
- Statistical methodology: Bradley-Terry model for Elo estimation; Spearman correlation for ranking alignment.
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Leaderboard standings in the WildVision-Arena showing the dominance of proprietary models. | ||||
| WildVision-Arena | Elo Rating | 1198 | 1307 | +109 |
| WildVision-Arena | Elo Rating | 1165 | 1307 | +142 |
| WildVision-Bench | Spearman Correlation | 0.80 | 0.94 | +0.14 |
| WildVision-Bench | Spearman Correlation | 0.64 | 0.94 | +0.30 |
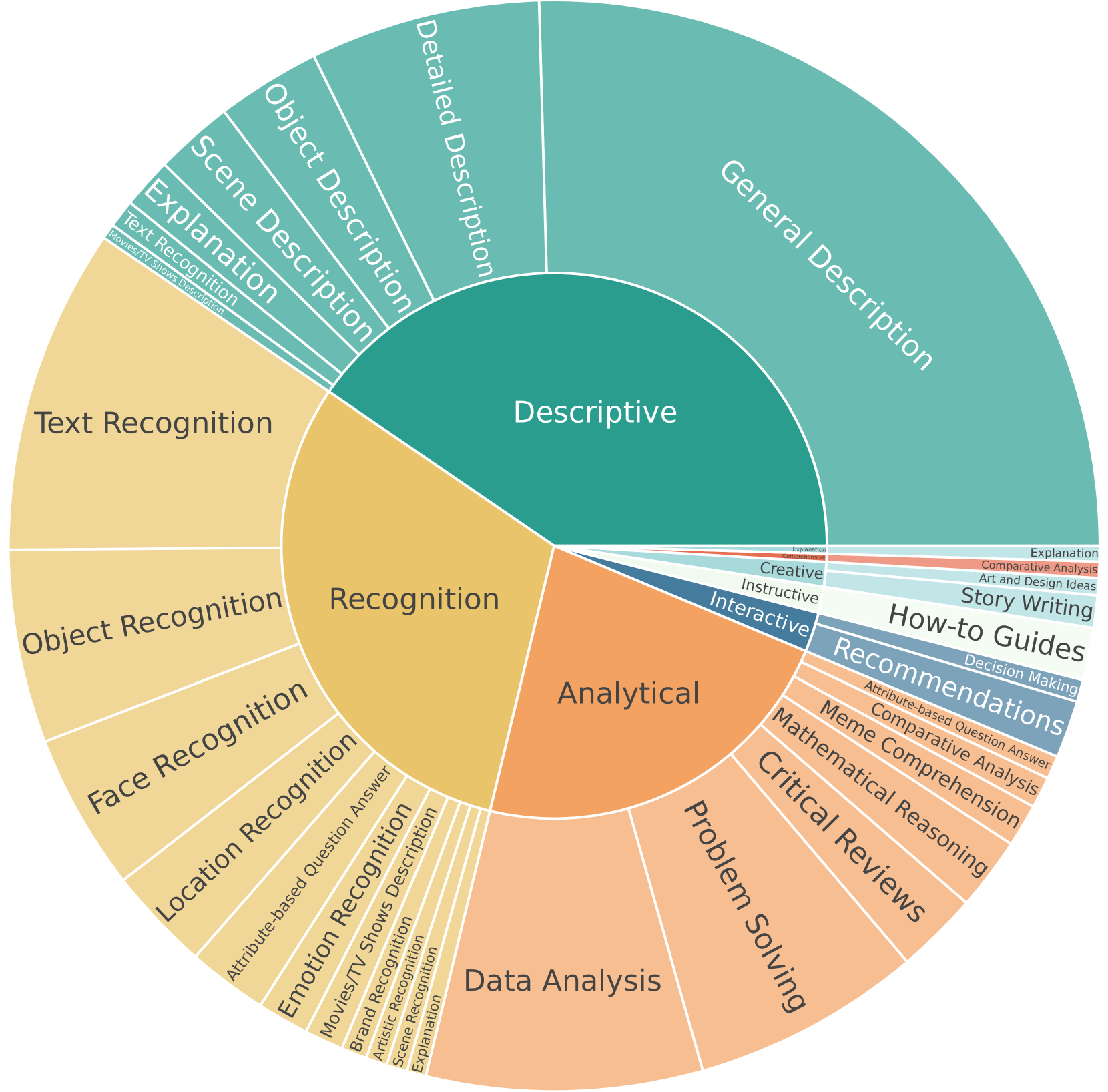
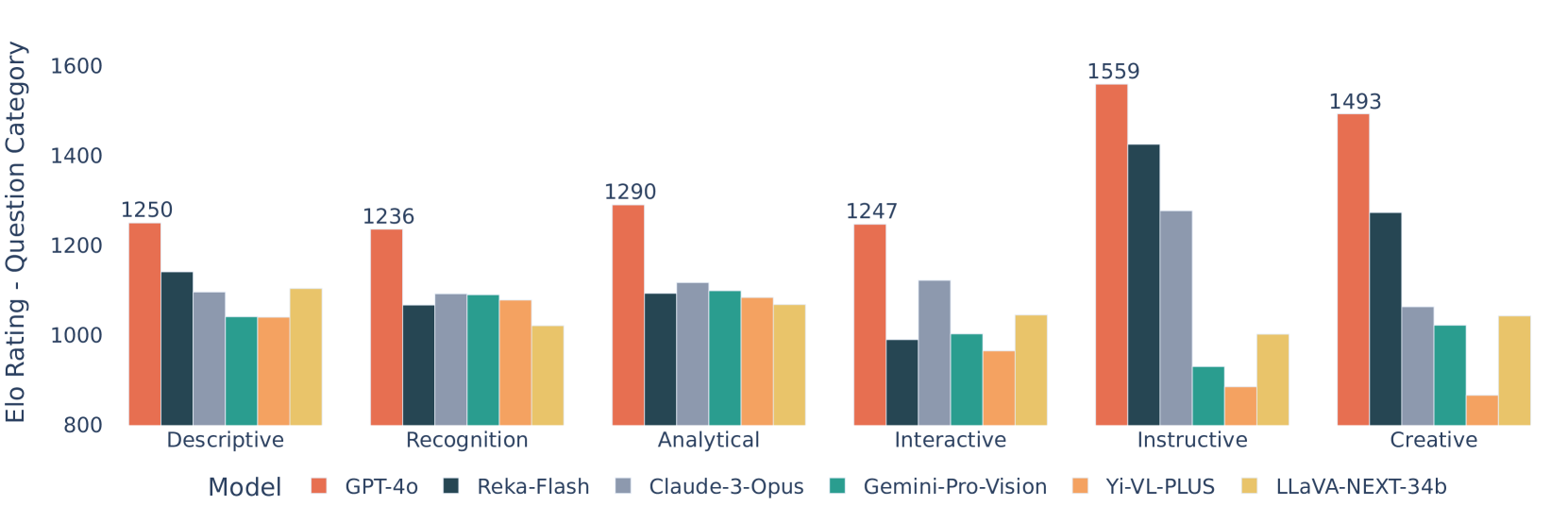
Experiment Figures
Heatmap of battle counts and win fractions for top models.
Spearman correlation heatmap between different benchmarks (MMVet, MMMU, etc.) and the Arena Elo.
Main Takeaways
- Proprietary models (GPT-4o, GPT-4V, Gemini) significantly outperform open-source models (LLaVA-Next) in real-world scenarios.
- GPT-4o is the current state-of-the-art, winning 77% of battles against GPT-4V.
- Automated evaluation using GPT-4o as a judge correlates extremely well (0.94) with human preferences, suggesting it is a viable proxy for expensive human evaluation.
- Failure analysis shows models still struggle with expert domain knowledge (e.g., specific game characters) and spatial reasoning.