📝 Paper Summary
Detailed Image Captioning
Vision-Language Model Evaluation
Reinforcement Learning from Feedback (RLHF)
The paper introduces a fine-grained metric and benchmark for detailed image captioning that decomposes text into atomic facts, and leverages this verification process to automatically generate feedback for training VLMs to reduce hallucinations.
Core Problem
Traditional image captioning metrics rely on short, coarse ground-truth annotations that fail to capture the detail of modern VLM outputs, leading to poor correlation with human judgment and an inability to accurately measure hallucinations.
Why it matters:
- Existing benchmarks (like COCO) penalize valid detailed descriptions because they don't appear in the brief reference captions
- Standard metrics (BLEU, CIDEr) cannot distinguish between creative detail and hallucination
- Poor evaluation metrics mislead the development of Vision-Language Models (VLMs) by not reflecting actual visual perception capabilities
Concrete Example:
A modern VLM might describe 'a vintage wooden chair with intricate carvings,' but if the ground truth is simply 'a chair in a room,' standard metrics (like BLEU) may penalize the extra detail as incorrect, or fail to verify if the 'intricate carvings' actually exist.
Key Novelty
Atomic Decomposition for Evaluation and Alignment
- Decomposes captions into 'primitive information units' (smallest self-sufficient facts) to evaluate precision and recall individually, rather than comparing full sentence embeddings or n-grams.
- Uses this decomposition to create a verifiable reward signal: an LLM splits the text, a VLM verifies each fact, and the aggregated score drives Reinforcement Learning (RL) optimization without human labeling.
Architecture
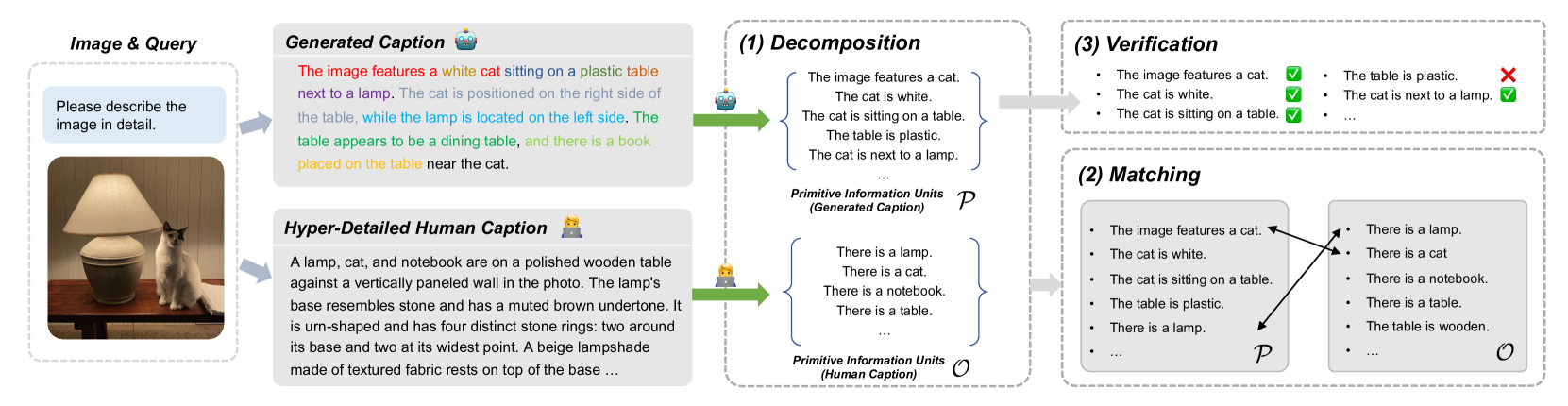
Overview of the DCScore evaluation framework and FeedQuill pipeline.
Evaluation Highlights
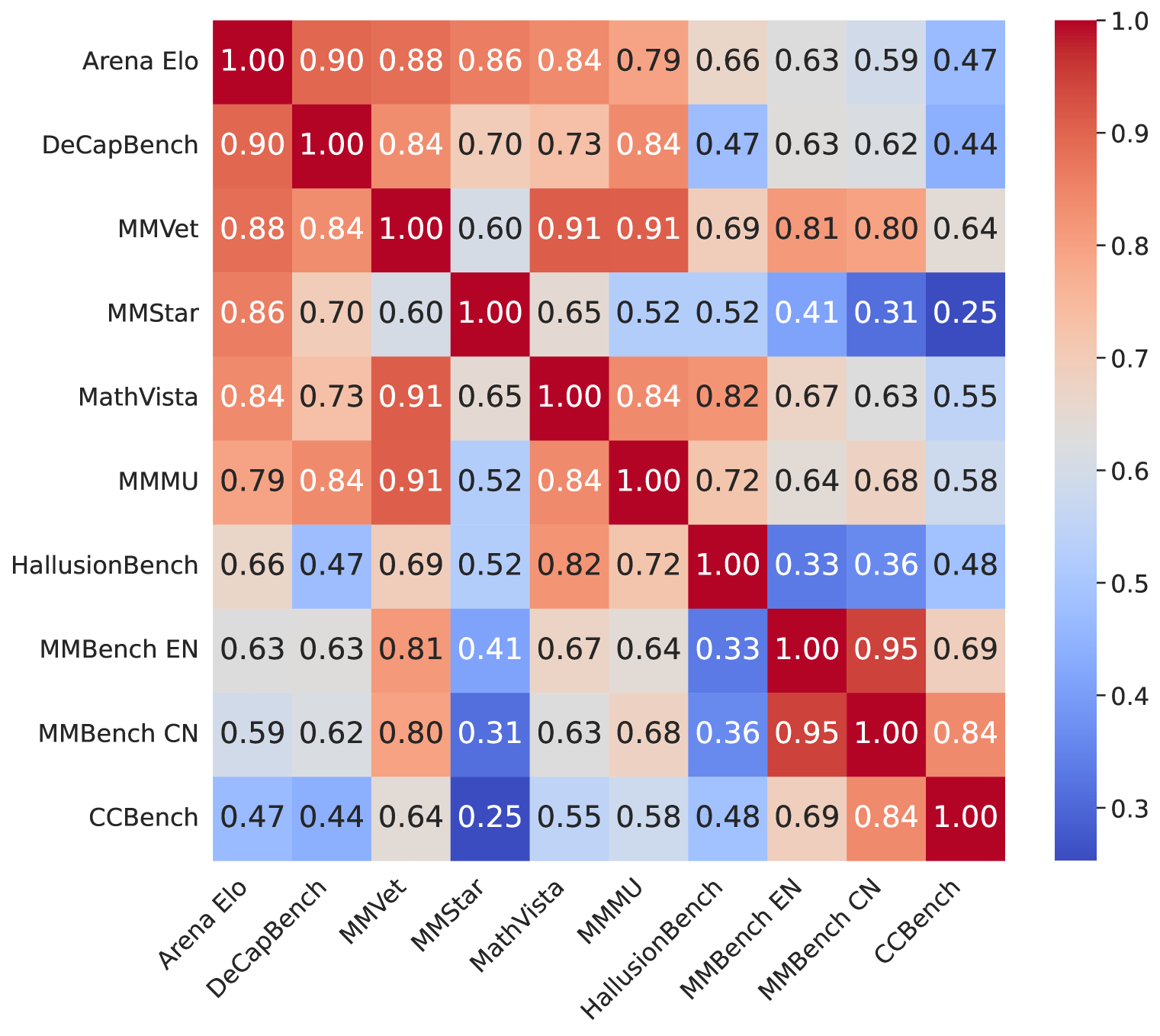
- DCScore improves Pearson correlation with human judgment by 0.2375 compared to state-of-the-art metrics.
- DeCapBench achieves 0.90 Spearman correlation with VLM Arena Elo ratings, surpassing benchmarks like MMVet and MMStar.
- FeedQuill optimization reduces hallucinations by 40.5% (relative) on the mmHal-V benchmark.
Breakthrough Assessment
8/10
Addresses a critical gap in VLM evaluation (detailed captioning) with a high-correlation metric and successfully closes the loop by using the metric for automated alignment training.