📝 Paper Summary
Internal Knowledge Retrieval
Parameter-Efficient Fine-Tuning
Awakening Augmented Generation (AAG) enables LLMs to generate their own compressed context and dynamically create adapter parameters to activate internal knowledge for question answering without external retrieval.
Core Problem
Large Language Models possess extensive internal knowledge but struggle to effectively activate it for specific tasks, often leading to hallucinations or requiring computationally expensive retrieval of external documents.
Why it matters:
- Retrieval-Augmented Generation (RAG) depends on external resources and incurs high inference costs due to processing long retrieved documents (over 100x prompt length increases).
- Generation-Augmented Generation (GAG) often relies on powerful external models (like GPT-4) or costly API calls, limiting privacy and broad application.
- Existing methods often require specific retraining for different domains, making them resource-inefficient and hard to generalize across scenarios.
Concrete Example:
For the question 'what does jamaican people speak?', RAG might retrieve >200 tokens ('Jamaica is regarded... official language is English...'). AAG aims to internally generate a compressed cue like 'official language ... Jamaica' (20 tokens) and modify model parameters to answer correctly without external lookups.
Key Novelty
Internal Knowledge Awakening via Symbolic and Parameter Context
- Explicit Awakening: Uses a fine-tuned generator to create a compressed 'dummy document' (symbolic context) that mimics the information density of a retrieved document but is generated internally.
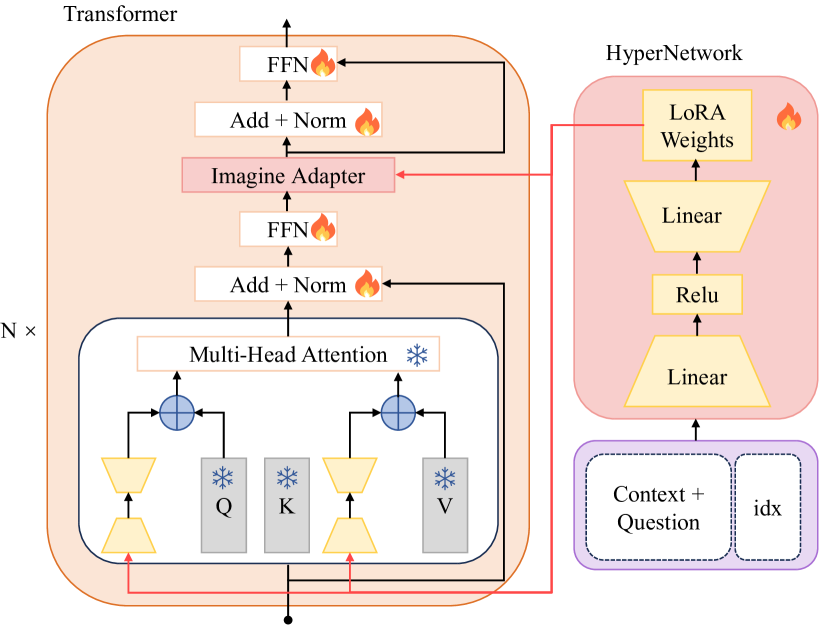
- Implicit Awakening: Uses a hypernetwork to dynamically generate LoRA adapter weights (parameter context) for the LLM based on the specific question and dummy document.
- Long Context Distillation: Trains the student model (with short context) to mimic the internal representations and attention patterns of a teacher model (FiD) that has access to long retrieved contexts.
Architecture
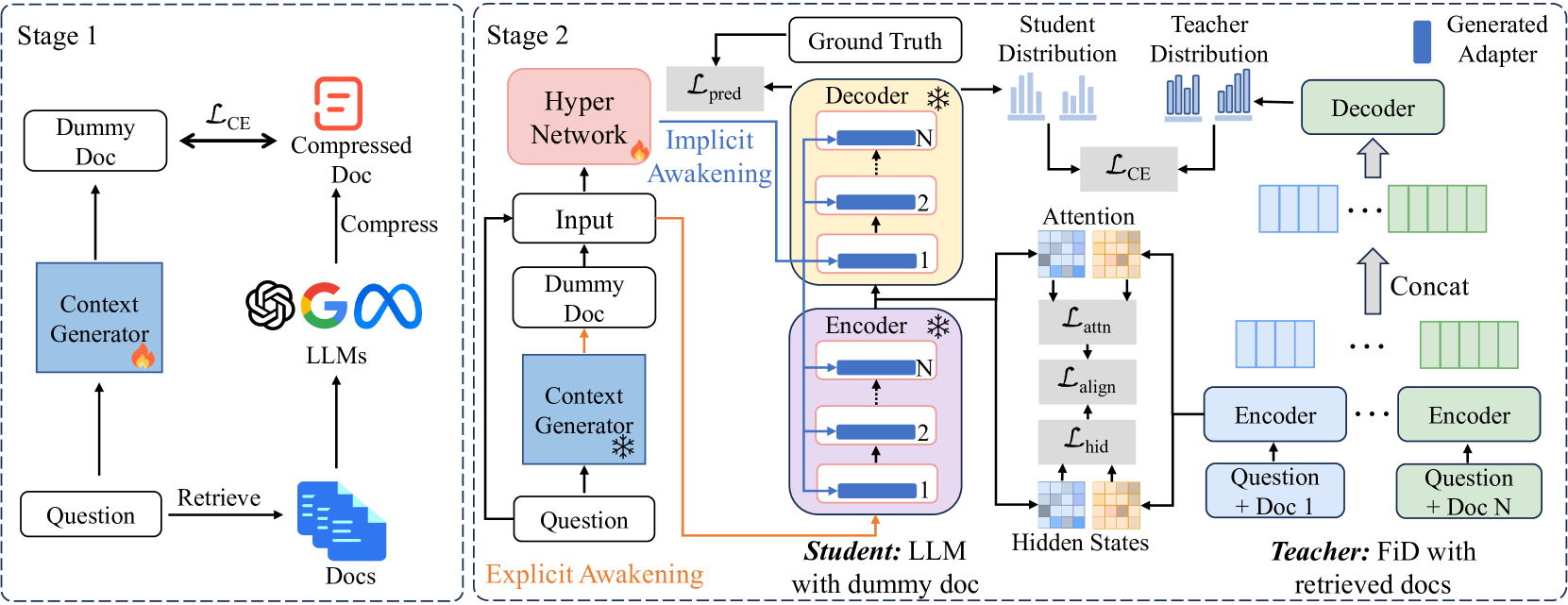
The overall framework of AAG, illustrating the Explicit Awakening (context generator) and Implicit Awakening (hypernetwork) modules.
Evaluation Highlights
- Outperforms baselines that retrieve and generate knowledge by 2% under the same document settings on NQ, TriviaQA, and WebQ datasets.
- Achieves similar performance to retrieval baselines while reducing inference cost (tokens processed) by up to 4x.
- Demonstrates effective out-of-distribution generalization, maintaining performance even when tested on datasets different from the training distribution.
Breakthrough Assessment
7/10
Novel combination of hypernetworks for dynamic adapter generation and knowledge distillation to simulate RAG without retrieval. Strong efficiency gains, though still relies on the premise that the model *has* the knowledge internally.