📝 Paper Summary
Vision-Language Model Evaluation
Image Captioning Benchmarks
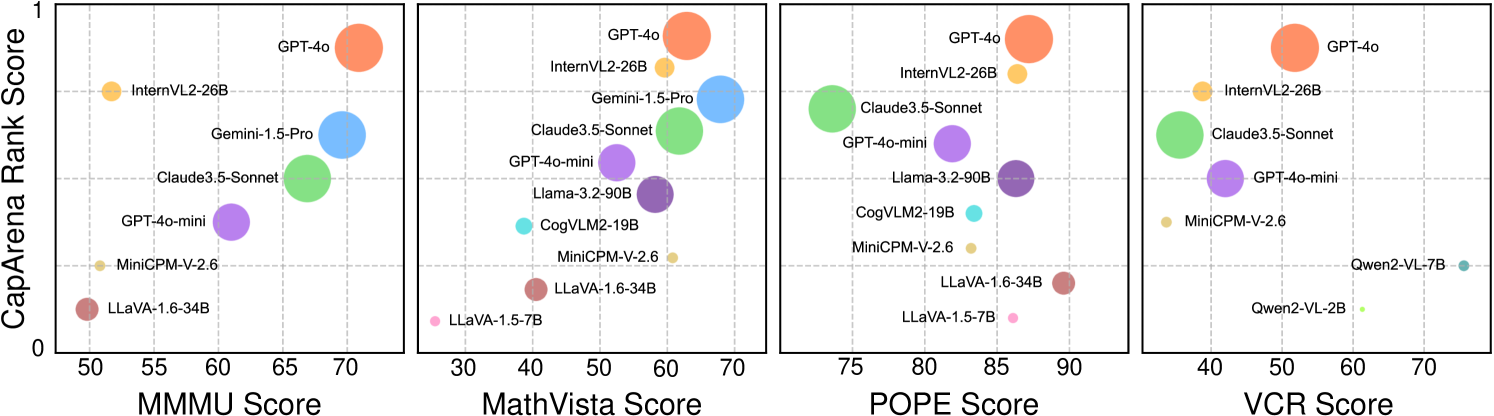
CapArena introduces a large-scale pairwise human benchmark for detailed image captioning, revealing that GPT-4o surpasses human performance and that VLM-as-a-Judge is the only automated metric reliably correlating with human rankings.
Core Problem
Existing image captioning benchmarks (like MSCOCO) rely on short, outdated captions that fail to challenge modern Vision-Language Models (VLMs), while traditional metrics cannot accurately measure the quality of long, detailed descriptions.
Why it matters:
- Current VLMs are optimized for Visual Question Answering (VQA) but their fundamental ability to comprehensively describe images is unmeasured
- Traditional metrics like CLIPScore and BLEU fail to correlate with human judgments on detailed captions, leaving researchers without reliable feedback
- The lack of benchmarks prevents the community from knowing if open-source models are closing the gap with commercial models in basic visual perception
Concrete Example:
In an image showing a cat pouncing on a dog (Table 1), Qwen2-VL generates a long but imprecise description of the cat's posture. Traditional metrics might score it highly due to keyword overlap, but human annotators prefer the human-written caption that captures the specific 'pouncing' action. CapArena captures this nuance via pairwise voting.
Key Novelty
Pairwise Battle Arena for Detailed Captioning
- Adapts the 'Chatbot Arena' methodology to image captioning by collecting over 6,500 pairwise human preference votes on detailed descriptions
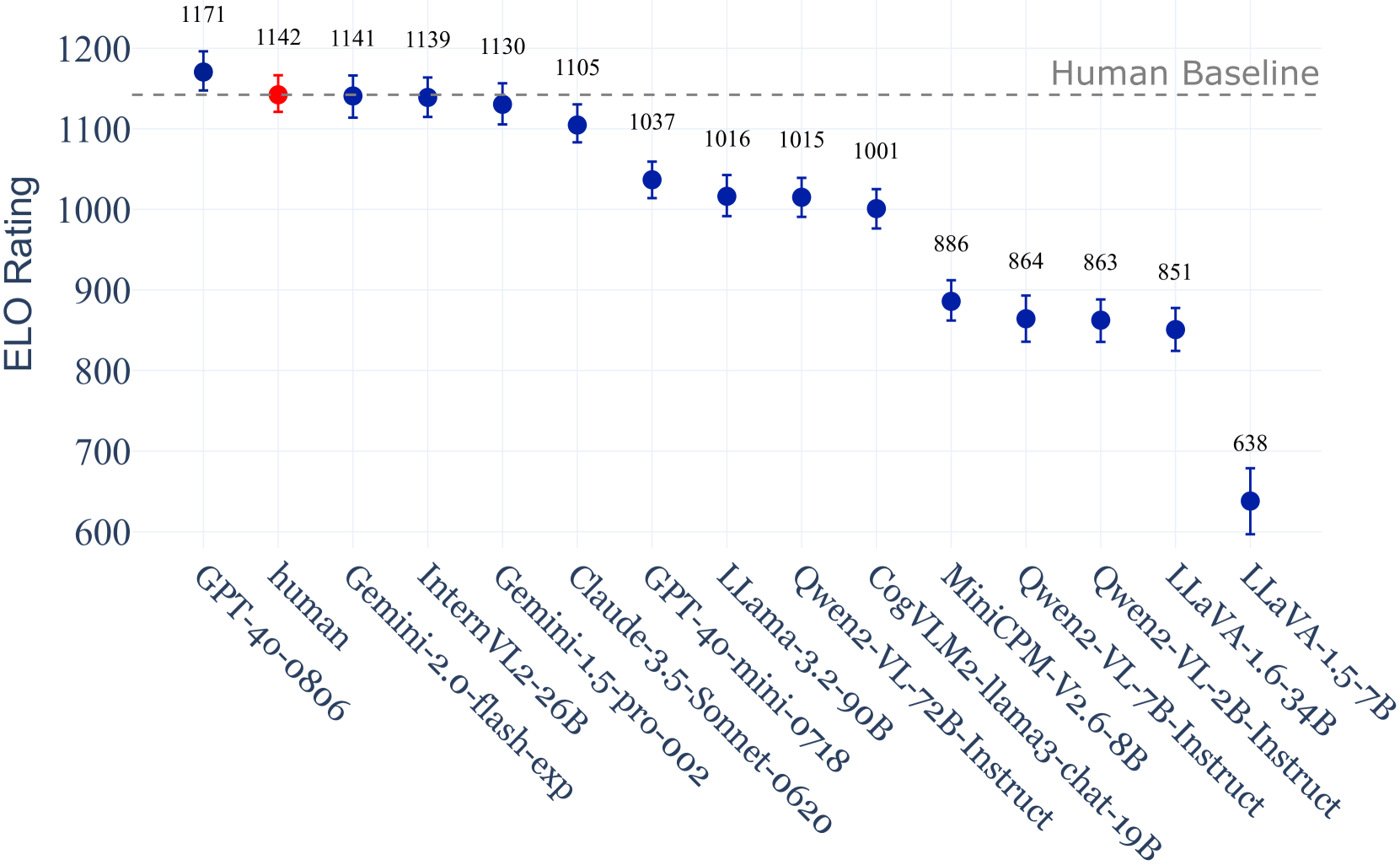
- Uses the Bradley-Terry statistical model to convert pairwise wins/losses into a continuous Elo rating scale for ranking models
- Proposes CapArena-Auto, an automated pipeline using GPT-4o with reference captions to mimic human judging at low cost
Architecture
Conceptual flowchart of the scoring mechanism (Text-based description as no explicit architecture diagram exists for the methodology)
Evaluation Highlights
- GPT-4o achieves an Elo rating of ~1195, surpassing the human baseline (~1180) and establishing a new state-of-the-art
- CapArena-Auto (automated evaluation) achieves 94.3% correlation with human rankings, significantly outperforming traditional metrics like METEOR
- InternVL2-26B (Elo ~1140) outperforms much larger open-source models like Llama-3.2-90B (Elo ~1060), highlighting the importance of strong vision encoders
Breakthrough Assessment
9/10
Marks a pivotal milestone where AI (GPT-4o) explicitly surpasses human performance in detailed image captioning. fundamentally shifts evaluation from n-gram matching to pairwise preference.