📝 Paper Summary
Medical Vision-Language Models (VLM)
Multimodal Clinical Decision Support
Hulu-Med unifies medical text, 2D images, 3D volumes, and video into a single transparent architecture using universal patch encoding and token reduction, outperforming specialized models.
Core Problem
Clinical decision-making requires integrating text, 2D/3D images, and video, but current AI systems are fragmented into modality-specific models, preventing holistic cross-modal insights.
Why it matters:
- Existing generalist VLMs (Vision-Language Models) fail to cover the full spectrum of clinical needs, particularly 3D volumes (CT/MRI) and surgical video analysis
- Specialized medical AI tools are often opaque, relying on proprietary datasets that hinder reproducibility, community scrutiny, and clinical trust
- Clinicians must manually synthesize signals from fragmented AI tools, leading to workflow inefficiencies and potential diagnostic errors
Concrete Example:
A clinician analyzing a patient's care journey needs to correlate a 3D CT scan with a surgical video and text notes. Current systems require three separate models (one for 3D, one for video, one for text), whereas Hulu-Med processes all three inputs natively in one context.
Key Novelty
Unified Medical-Generalist Architecture with Transparent Pipeline
- Replaces modality-specific encoders with a single patch-based visual encoder extended via 2D RoPE (Rotary Positional Embeddings) to handle 3D volumes and videos as sequences of patches
- Implements a 'medical-aware token-reduction' strategy that prunes ~55% of redundant visual tokens, enabling the processing of computationally heavy 3D/video data without specialized hardware
- Releases the entire development pipeline—including data curation, synthesis recipes, and training code—addressing the transparency crisis in medical AI
Architecture
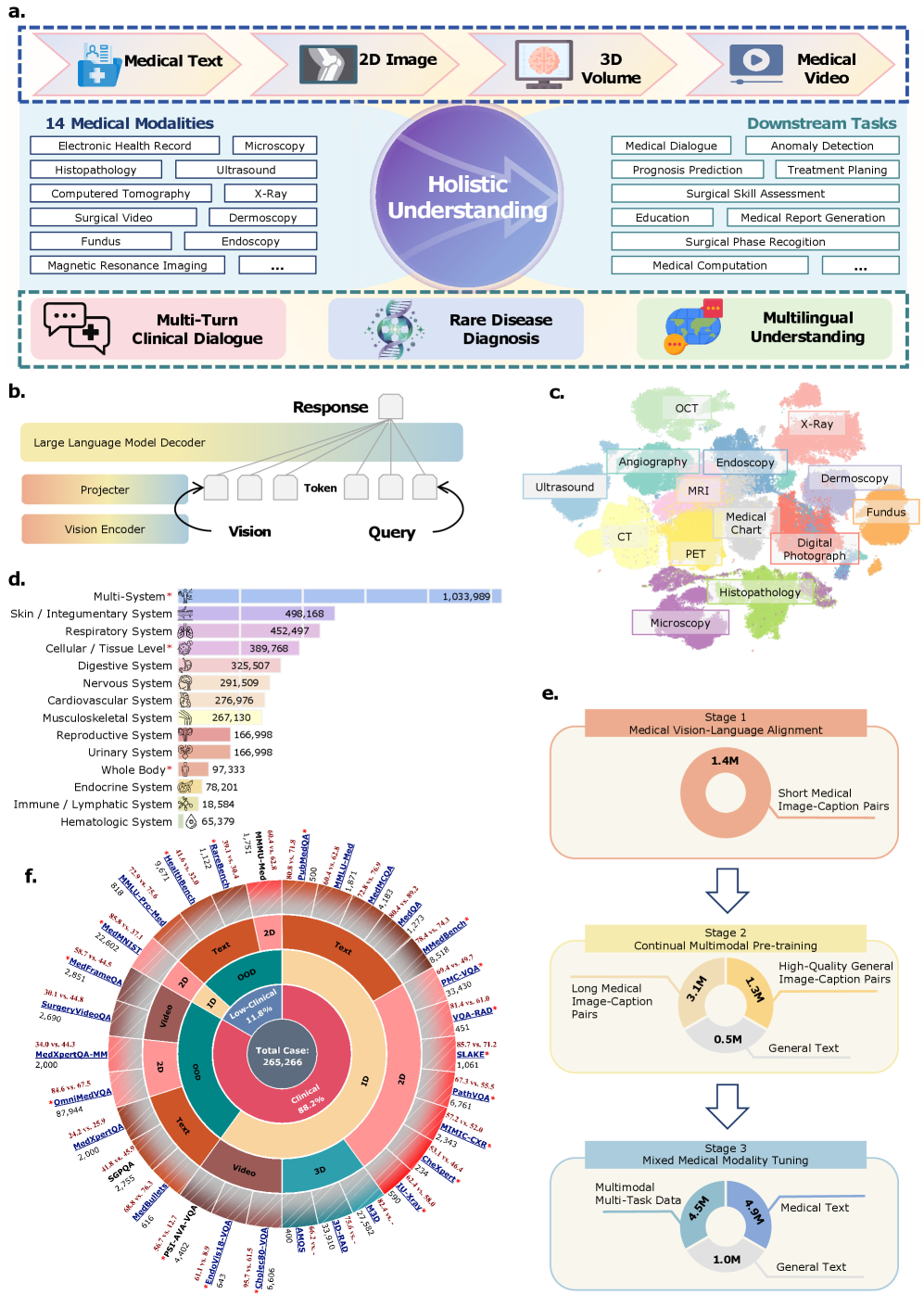
The unified architecture of Hulu-Med processing diverse inputs (Text, Image, Volume, Video).
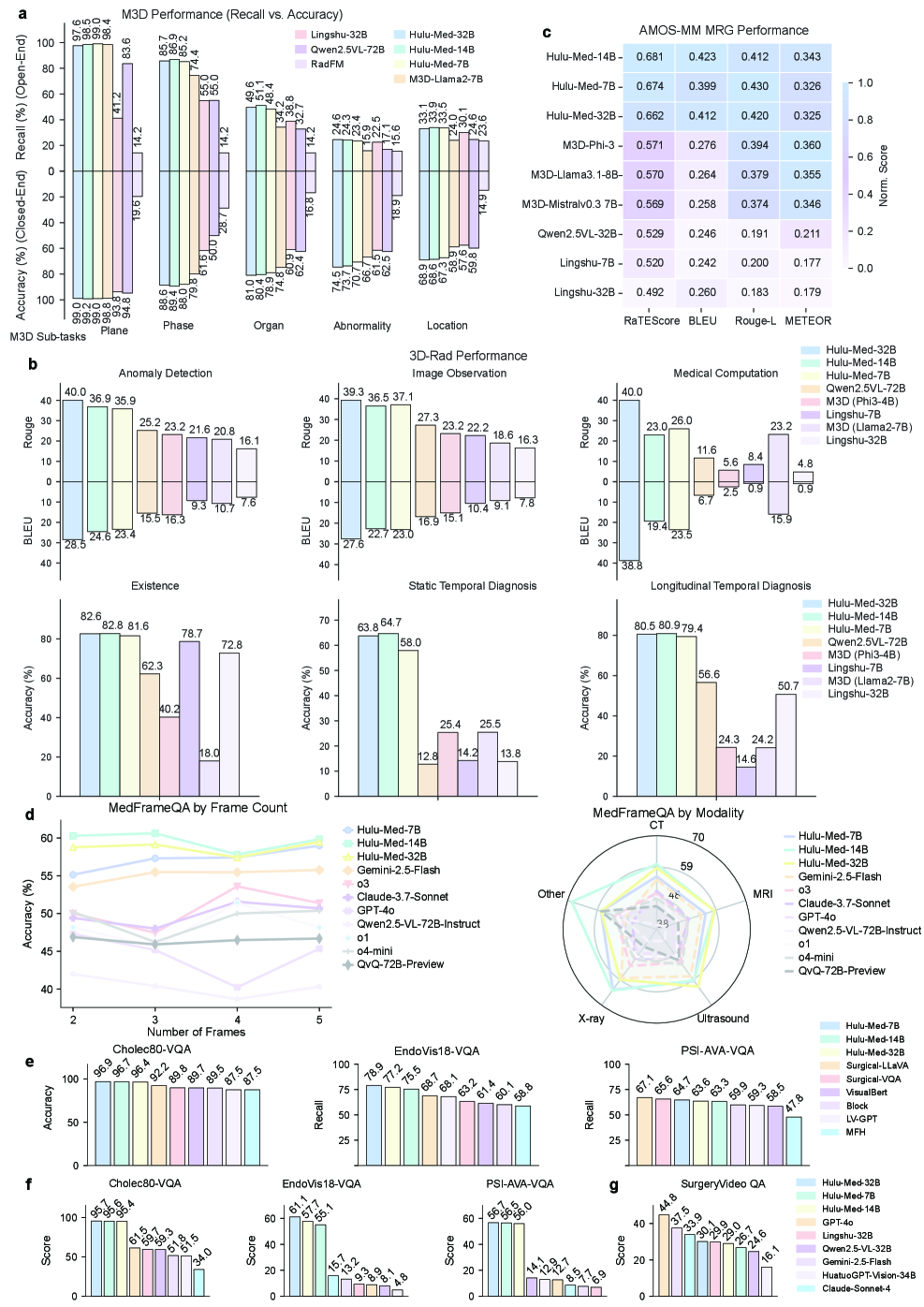
Evaluation Highlights
- Surpasses GPT-4o on 16 of 30 medical benchmarks and outperforms existing open-source models on 27 of 30 benchmarks
- Hulu-Med-7B achieves a RaTEScore of 57.0 on MIMIC-CXR (report generation), significantly outperforming the larger specialized MedGemma-27B (51.3)
- Maintains high accuracy on 3D/video tasks despite a 55% reduction in visual tokens, validating the efficiency of the pruning strategy
Breakthrough Assessment
9/10
A significant leap in unifying disparate medical modalities (2D/3D/Video) into one open architecture. The transparency and efficiency (token reduction) address major barriers to clinical AI adoption.